NoisyTune: A Little Noise Can Help You Finetune Pretrained Language Models Better论文研读
Posted 冲冲冲鸭鸭鸭~
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了NoisyTune: A Little Noise Can Help You Finetune Pretrained Language Models Better论文研读相关的知识,希望对你有一定的参考价值。
今天也要加油呀!o(* ̄▽ ̄*)ブ
目录
一、摘要
有效地微调预训练语言模型(PLMs)对于其在下游任务中的成功至关重要。然而,PLMs可能存在过度拟合训练前任务和数据的风险,这些任务和数据通常与目标下游任务存在差距。现有PLMs 微调的方法可能难以克服这种差距,并导致性能不佳。在《NoisyTune》一文中,提出了一种非常简单但有效的方法NoisyTune,通过微调PLMs参数之前添加一些噪声,帮助PLMs更好地微调下游任务。更具体地说,我们提出了一种矩阵式扰动方法,该方法根据不同参数矩阵的标准差向其添加不同的均匀噪声。这样,就可以考虑PLMs中不同类型参数的不同特性。
二、模型
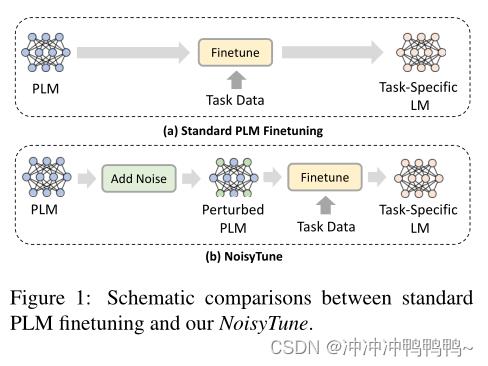
PLMs通常具有不同类型的参数矩阵,如查询、键、值和前馈网络矩阵。PLMs中的不同参数矩阵通常具有不同的特征和尺度。
因此,PLMs中的所有参数矩阵添加统一的噪声可能不是保持其良好模型效用的最佳选择。为了应对这一挑战,我们提出了一种基于矩阵的扰动方法,该方法根据不同参数矩阵的方差向其添加不同强度的噪声。将PLMs中的参数矩阵(或标量/向量)表示为[W1,W2,…,WN],其中N是参数矩阵类型的数量。将参数矩阵Wi的扰动版本表示为Wi~,其计算如下:
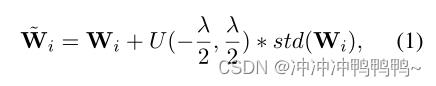
式中,std代表标准偏差。函数U(a,b)表示从a到b的均匀分布噪声,λ是控制相对噪声强度的超参数。注意,U(a,b)是与Wi形状相同的矩阵,而不是标量。
代码实现只需要两行:
for name ,para in model.named parameters ():
model.state dict()[name][:] +=(torch.rand(para.size())−0.5)*noise_lambda*torch.std(para)三、实验
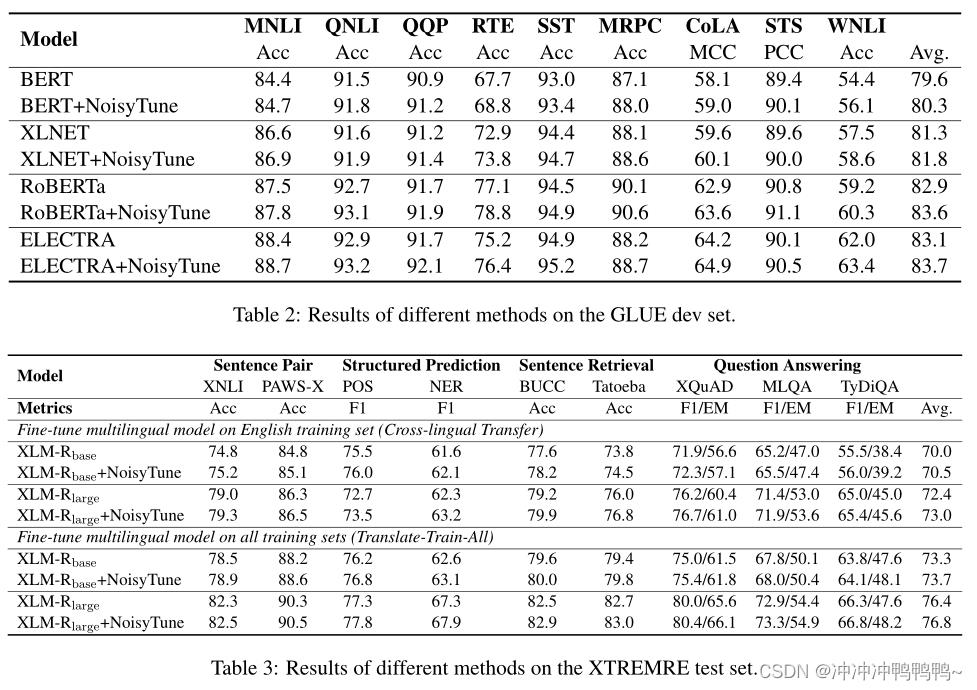
NoisyTune可以应用到各种预训练语言模型中,能够增强现有PLMs微调技术以实现更好的性能。如下表所示,多个预训练模型在增加NoisyTune后效果都有所提升。
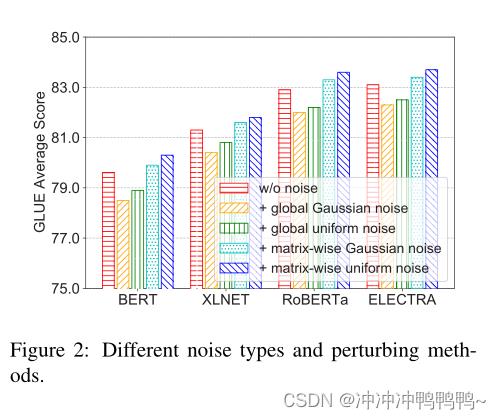
文章中也研究了不同增加噪声的方法,其中,矩阵级均匀噪声得到的效果最好。如下图所示:
同时,在不同数据量下,NoisyTune方法相对于finetune均有所提高。
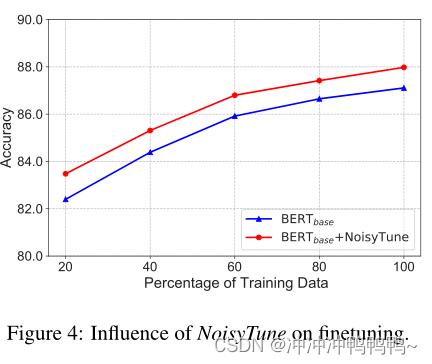
文章中也研究了NoiseyTune中的超参数λ的影响,λ是控制相对噪声强度。如下表所示:
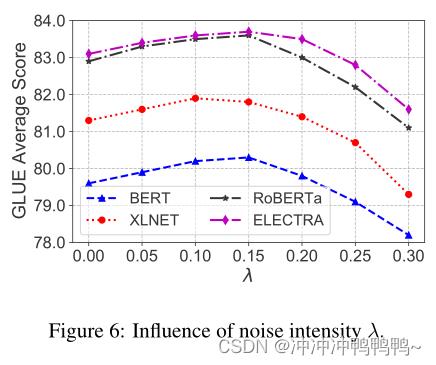
从图中可以看出,当λ太小或太大时,性能都不能达到最佳的。这是因为当λ太小时,PLMs很难进行参数空间探索和克服过拟合问题。当λ太大时,PLMs中有用的预训练知识可能会被随机噪声淹没。0.1到0.15之间的值更适合于GLUE数据集上的NoisyTune。
以上是关于NoisyTune: A Little Noise Can Help You Finetune Pretrained Language Models Better论文研读的主要内容,如果未能解决你的问题,请参考以下文章