有序的Map集合
Posted 普通网友
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了有序的Map集合相关的知识,希望对你有一定的参考价值。
我们通常使用的Map集合是HashMap,在大多数情况下HashMap可以满足我们的要求,但是HashMap有一个缺点:HashMap****是无序的,即其迭代顺序与其key或value的大小无关。而在某些情况下,如果我们需要Map集合里的元素有序,那么HashMap是不能满足我们的要求的。
那么有没有有序的Map集合呢?有,Java提供了两种有序的Map集合:LinkedHashMap和TreeMap;
**(一)**LinkedHashMap
LinkedHashMap继承了HashMap,是HashMap的子类。
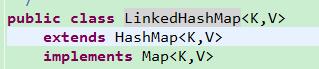
其实LinkedHashMap与HashMap区别不大,也是通过计算键的hash值,映射到hash表中,那么LinkedHashMap是如何实现有序的呢?
LinkedHashMap不仅维护着一个hash****表,而且还维护着一个双向链表,而这个双向链表里的元素就是有序的。
LinkedHashMap的Entry继承于HashMap的Entry,并且增加了before和after属性。
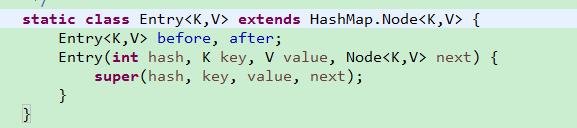
可以看到before和after的类型都是Entry,LinkedHashMap通过before和after来构建双向链表。
LinkedHashMap的内部结构如图所示:
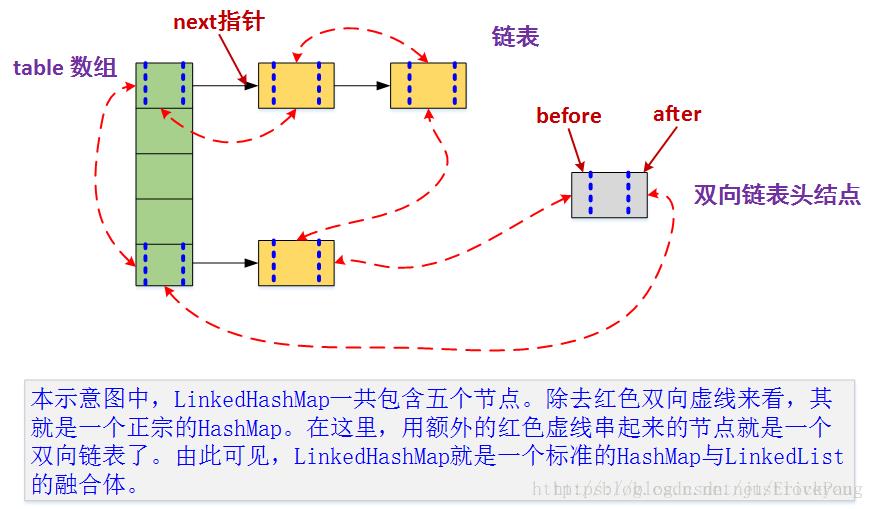
LinkedHashMap有两种排序方式:插入排序和访问排序(修改或访问一个元素后,将该元素移到队列末尾),默认是插入排序。使用accessOrder来标记使用哪种排序方式,accessOrder==true****时,表示使用访问排序,默认为false;注意:LinkedHashMap的有序不是key或value的自然顺序。
LinkedHashMap的插入:
put**():**
LinkedHashMap的put方法和HashMap的相同,不过LinkedHashMap重写了newNode方法,在插入时,会判断双向链表是否为空,如果为空,则将该Entry作为头结点head,否则在双向链表末尾插入该Entry;如果更新值(key相同),则会判断accessOrder是否为true,如果为true,则将该Entry移到双向队列的尾部。
get**():**
LinkedHashMap在get的时候,会判断accessOrder是否为true,即是否按访问顺序排序,如果是true,则会把该Entry移到双向队列的尾部。然后再返回value。
LinkedHashMap****的迭代:
LinkedHashMapIterator实现了迭代器的功能,其是对双向循环链表的遍历操作。但是这个迭代器是abstract的,不能直接被对象所用。
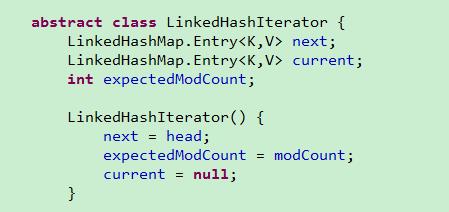
LinkedHashMap中的LinkedKeyIterator**,LinkedValueIterator,LinkedEntryIterator都继承了LinkedHashMapIterator,并且实现了Iterator接口,我们可以使用上面三种迭代器来迭代key,value,entry。**三种迭代器迭代的是同一个双向链表,即迭代的元素是相同的,只是返回的类型不同。
遍历TreeMap的键值对
LinkedHashMap map = new LinkedHashMap();
Integer integ = null;
Iterator iter = map.entrySet().iterator();
while(iter.hasNext())
Map.Entry entry = (Map.Entry)iter.next();
// 获取key
key = (String)entry.getKey();
// 获取value
integ = (Integer)entry.getValue();
**(二)**TreeMap
TreeMap也是一个有序的Map集合,其底层是一颗红黑树,该映射根据其键的自然顺序进行排序,或者根据创建映射时提供的 Comparator 进行排序,具体取决于使用的构造方法。

TreeMap的Entry结构如下:
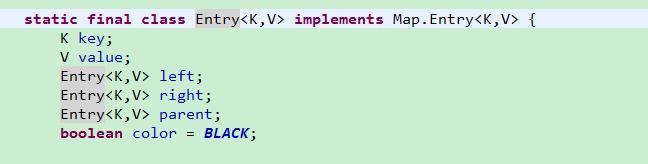
可以看出来TreeMap的Entry其实是一个树节点,构建了一颗红黑树。而entry的插入,就是在红黑树中新增一个节点,并调整红黑树。
TreeMap****的插入:
put**():**
如果Comparator 为空,会使用key进行比较,按照从小到大的次序插入到红黑树中。
如果Comparator 不为空,则根据Comparator来进行比较。
TreeMap****的迭代:
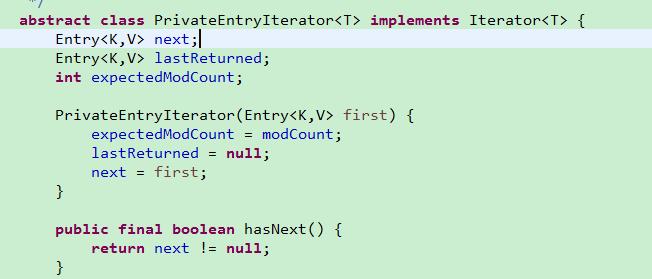
PrivateEntryIterator实现了迭代器的功能,其是对红黑树进行遍历,返回的是红黑树中的有序序列。但是这个迭代器是abstract的,不能直接被对象所用。迭代时使用的是EntryIterator,ValueIterator,KeyIterator等迭代器。
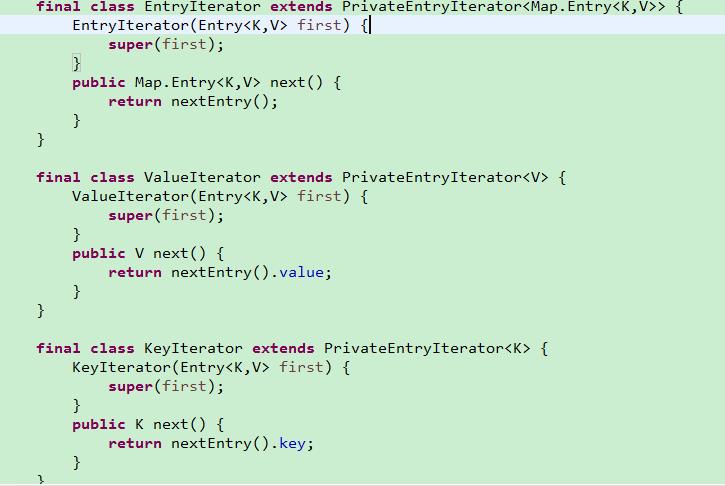
除了顺序遍历,TreeMap还可以逆序遍历,由于TreeMap中的元素是从小到大的顺序排列的。因此,顺序遍历,就是从第一个元素开始,逐个向后遍历;而倒序遍历则恰恰相反,它是从最后一个元素开始,逐个往前遍历。

遍历TreeMap的键值对
TreeMap map = new TreeMap ();
Integer integ = null;
Iterator iter = map.entrySet().iterator();
while(iter.hasNext())
Map.Entry entry = (Map.Entry)iter.next();
// 获取key
key = (String)entry.getKey();
// 获取value
integ = (Integer)entry.getValue();
Map集合以及Collections集合工具类
一、Collection集合主要特点与Map集合的区别
Collection:
单列集合;有两个子接口 List集合元素是有序的,可以重复的 Set集合元素是无序的,不可以重复
List:元素可重复,有序
ArrayList:底层数据结构是数组,查询快,增删慢,不同步,线程不安全,效率高;没有特殊说明一般使用ArrayList集合;
Vector:底层数据结构是数组,查询快,增删慢,同步,线程安全,效率低;有一个elements()特有迭代方法;
LinkedList:底层数据结构是链表,查询慢,增删快,不同步,线程不安全,效率高;有特有的增删方法;
Set:元素不可重复,无序
HashSet:底层数据结构是哈希表,由hashCode()和equals()方法支持它的不可重复性,且不保证迭代顺序,特别是不保证其顺序永久不变;
LinkedHashSet:继承HashSet 底层数据结构是哈希变和链表,所有是有序的,但是不可重复;
TreeSet:底层数据结构是红黑树数据结构(基于HashMap),保证元素唯一并且对其排序;
两种排序方式: 1、自然排序,需要元素所在的类实现Comparable接口,重写compareTo()方法;
2、选择器排序,创建TreeSet方法时需要创建Comparator接口的子实现类作为参数,并且重写其compare()方法。
Map:
双列集合;有两个主要子实现类 HashMap和TreeMap;Map集合是一种键值对的一种映射关系 key-value 其键唯一,值可重复。
二、Map<K,V>接口
1、概述:public interface Map<K,V>将键映射到值的对象;一个映射不能包含重复的键;每个键最多只能映射到一个值。
K - 此映射所维护的键的类型
V - 映射值的类型
2、Map集合主要方法:
添加功能:
V put(K key,V value):添加元素,如果键是第一次存储的时候,返回值null,如果键已经存在,再次存储的时候将第一次的值返回,并且后面的值覆盖掉前面的值
删除功能:
void clear()从此映射中移除所有映射关系(强拆)
V remove(Object key):删除键,返回值
判断功能:
boolean containsKey(Object key):判断当前Map集合中是否存在key:键
boolean containsValue(Object value):判断当前Map姐中是否存在value:值
获取功能:
Set<Map.Entry<K,V>> entrySet()返回一个键值对对象
V get(Object key)返回指定键所映射的值
Set<K> keySet():获取所有的键的集合
Collection<V> values():获取所有的值的集合
3、集合遍历:
A:方式一:使用keySet()方法,获取所有的键,再用键去获取所对应的值
HashMap<K,V> hm = new HashMap<K,V>();
//添加元素put(key,value)
Set<K> hs = hm.keySet();
for(K key : hs){
System.out.println(key + "---" + hm.get(key));
}
B:方式二:使用entrySet()方法,获取键值对对象,通过Map.Entry<K,Y>接口的getKey()、getValue()方法遍历集合
HashMap<K,V> hm = new HashMap<K,V>();
//添加元素put(key,value)
Set<Entry<K, Y>> s = hm.entrySet();
for(Entry<K, Y> se : s){
K key = se.getKey();
Y value = se.getValue();
system.out.println(key + "---" + value);
}
4、子实现类——HashMap
1)概述:HashMap集合是哈希表组成,并且他们的键允许null,值也可以允许null,,该类不能保证被元素的顺序恒久不变。
2)因为键的唯一性,所以在键的位置上存储自定义类的时候需要重写hashCode()和equals()方法;
值可以重复,不影响。
3)HashMap和Hashtable的区别
HashMap和Hashtable都实现了Map接口,他两是平级关系,Hashtable类似HashMap;
HashMap集合:允许有null键和null值,线程不安全,不同步,执行效率高;
Hashtable集合:不允许有null键和null,线程安全的,同步,效率低。
3)LinkedHashMap——extends HashMap
底层是有哈希表和链表组成,可以保证键的唯一性,和有序性(存取一致);
5、子实现类——TreeMap
1)底层基于红黑树的数据结构,该映射根据其键的自然顺序进行排序,或者根据其键进行选择器排序,具体取决于使用的构造方法
2)排序方式:(排序排的都是键,排序方式同TreeSet)
自然排序:要求储存在键位置上的元素的类implements Comparable接口并且重写compareTo()方法;
选择器排序:使用TreeMap(Comparator<T> comparator)构造器,使用匿名内部类的方式创建Comparator的子实现类对象,并重写compare()方法;
三、Collections —— 集合工具类
1、概述:对集合操作的工具类,没有构造方法,所有方法都由static修饰,可以直接调用;
2、常用方法:
public static <T> void sort(List<T> list):默认自然排序:将集合中的元素升序排序
默认的自然排序:需要元素所在的类implements Comparable接口,重写compareTo()方法,指定排序的方式;
比较器排序:public static <T> void sort(List<T> list,Comparator<T> c)
注意,如果两种排序方式都是使用了,那么最终结果遵从比较器排序。
public static <T> int binarySearch(List> list,T key):二分查找搜索法:key:查找的元素
public static void reverse(List list):反转功能(StringBuffer也有reverse功能)
public static void shuffle(List<?> list):随机置换,打乱顺序
四、集合嵌套遍历
1、ArrayList嵌套HashMap
/*需求:
假设ArrayList集合的元素是HashMap。有3个。
每一个HashMap集合的键和值都是字符串。
元素我已经完成,请遍历。
结果:
周瑜---小乔
吕布---貂蝉
郭靖---黄蓉
杨过---小龙女
令狐冲---任盈盈
林平之---岳灵珊*/
import java.util.ArrayList;
import java.util.HashMap;
import java.util.Set;
public class ArratListTest {
public static void main(String[] args) {
ArrayList<HashMap<String,String>> al = new ArrayList<HashMap<String,String>>();
HashMap<String,String> hm1 = new HashMap<String, String>();
HashMap<String,String> hm2 = new HashMap<String, String>();
HashMap<String,String> hm3 = new HashMap<String, String>();
hm1.put("周瑜", "小乔");
hm1.put("吕布", "貂蝉");
hm2.put("郭靖", "黄蓉");
hm2.put("杨过", "小龙女");
hm3.put("令狐冲", "任盈盈");
hm3.put("林平之", "岳灵珊");
al.add(hm1);
al.add(hm2);
al.add(hm3);
for(HashMap<String,String> hm : al){
Set<String> keySet = hm.keySet();
for(String key : keySet){
System.out.println(key + "---" + hm.get(key));
}
System.out.println();
}
}
}
2、HashMap嵌套ArrayList
/*需求:
假设HashMap集合的元素是ArrayList。有3个。
每一个ArrayList集合的值是字符串。
元素我已经完成,请遍历。
结果:
三国演义
吕布
周瑜
笑傲江湖
令狐冲
林平之
神雕侠侣
郭靖
杨过 */
import java.util.ArrayList;
import java.util.HashMap;
import java.util.Set;
public class HsahMapTest {
public static void main(String[] args) {
HashMap<String,ArrayList<String>> hm = new HashMap<String,ArrayList<String>>();
ArrayList<String> al1 = new ArrayList<String>();
al1.add("吕布");
al1.add("周瑜");
ArrayList<String> al2 = new ArrayList<String>();
al2.add("令狐冲");
al2.add("林平之");
ArrayList<String> al3 = new ArrayList<String>();
al3.add("郭靖");
al3.add("杨过");
hm.put("三国演义", al1);
hm.put("笑傲江湖", al2);
hm.put("神雕侠侣", al3);
Set<String> keySet = hm.keySet();
for(String key : keySet){
System.out.println(key);
ArrayList<String> valueList = hm.get(key);
for(String value : valueList){
System.out.println("\t" + value);
}
}
}
}
3、HashMap嵌套HashMap
/*HashMap嵌套HashMap
基础班
陈玉楼 20
高跃 22
就业班
李杰 21
曹石磊 23
先存储元素,然后遍历元素*/
import java.util.HashMap;
import java.util.Set;
public class HsahMapTest2 {
public static void main(String[] args) {
HashMap<String,HashMap<String,Integer>> hm = new HashMap<String,HashMap<String,Integer>>();
HashMap<String,Integer> hm1 = new HashMap<String, Integer>();
hm1.put("陈玉楼", 20);
hm1.put("高跃", 22);
HashMap<String,Integer> hm2 = new HashMap<String, Integer>();
hm2.put("李杰", 21);
hm2.put("曹石磊", 23);
hm.put("基础班", hm1);
hm.put("就业班", hm2);
Set<String> keySet = hm.keySet();
for(String key : keySet){
System.out.println(key);
HashMap<String, Integer> hashMap = hm.get(key);
Set<String> keySet2 = hashMap.keySet();
for(String key2 : keySet2){
System.out.println("\t" + key2 + "\t" + hashMap.get(key2));
}
}
}
}
以上是关于有序的Map集合的主要内容,如果未能解决你的问题,请参考以下文章