新版白话空间统计:莫兰指数小结
Posted 虾神说D
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了新版白话空间统计:莫兰指数小结相关的知识,希望对你有一定的参考价值。
CSDN的被爬虫专用声明:虾神原创,公众号\\知乎:虾神说D
转发、转载和爬虫,请主动保留此声明。
本节对前面写的莫兰指数部分留下的一下小问题进行解答,里面包括一些读者朋友们通过邮件提出的一些问题。
Q1:ArcGIS中,计算莫兰指数的工具里面的那个Row(行标准化)是拿来干嘛的?
A:所谓的行标准化,指的是在进行空间权重设定的时候,是否对权重系数进行标准化,具体说来,看下面这个例子:
还是这张图:
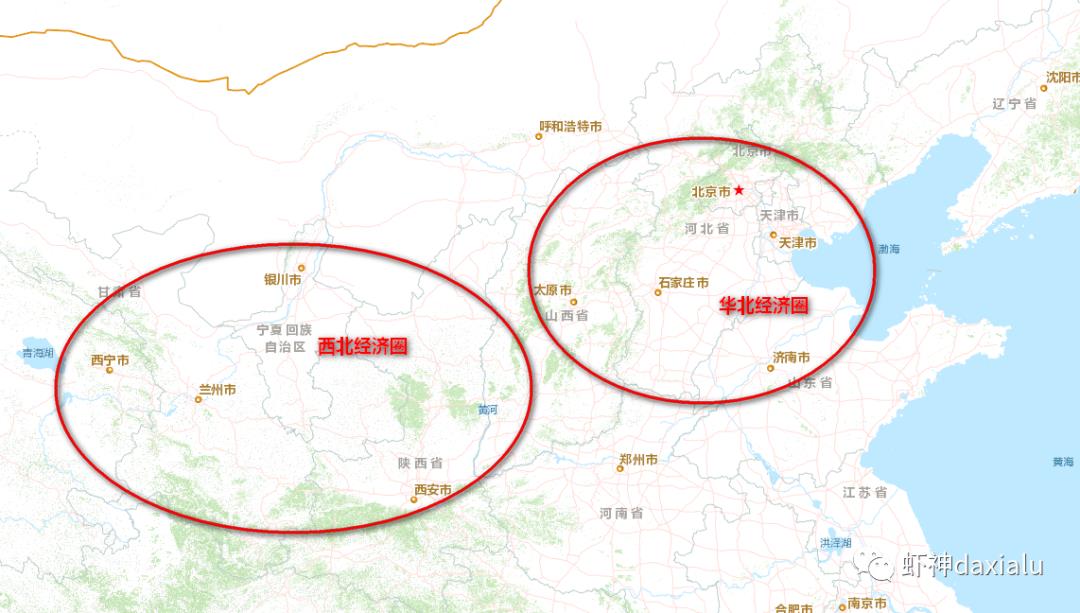
那么我们记录空间关系时候,会记录成这样的结构:
| 城市 | 临近城市 | 空间权重系数 |
| 北京 | 石家庄 | 1 |
| 北京 | 太原 | 1 |
| 北京 | 天津 | 1 |
| 北京 | 济南 | 1 |
| 西安 | 兰州 | 1 |
| 西安 | 银川 | 1 |
| 西安 | 西宁 | 1 |
这种情况,所有有临近关系的城市,都记录为1,那么现在就带来问题了:北京与周边临近城市的空间权重之和等于4,而西安与周边城市的空间权重之和,等于3。
这种情况,带入到莫兰指数的公式里面的时候,可能出现因为空间位置分布不均匀,或者设计采样以及聚合的方式不一致,带来一些计算上的麻烦,最大的麻烦就是有时候莫兰指数计算出来的结果,不在-1 —— 1之间。(大家可以回忆一下莫兰指数的计算公式,会迭代累加所有临近要素的字段值来)
所以,Esri建议对空间权重进行标准化,也就是用1来除以所有临近要素的数量,权重系数取平均值,那么上面这个空间权重矩阵就会记录成这个样子:
| 城市 | 临近城市 | 空间权重系数 |
| 北京 | 石家庄 | 0.25 |
| 北京 | 太原 | 0.25 |
| 北京 | 天津 | 0.25 |
| 北京 | 济南 | 0.25 |
| 西安 | 兰州 | 0.333 |
| 西安 | 银川 | 0.333 |
| 西安 | 西宁 | 0.333 |
这样,所有的空间要素与临近要素的空间权重之和,就都等于1了,不管你如何去设计你的采样方式,也不管数据分布是稀疏还是稠密,带入到公式里面的计算权重结果都是一样的。
Q2、莫兰指数计算的时候,为什么说最少需要30个样本才具备一定的可信性?这种说法出自哪个理论?
A:30个样本这个说法只是一个经验公式,没有确切的理论来证明。
所谓的“经验公式”,就是某个大牛,在某次会议或者与同行聊天的时候说:我觉得,这个样子,应该就差不多了……然后所谓的“这个样子”就是经验公式了,至于后面那个“应该就差不多了”,就被大家选择性的遗忘。

最出名的经验公式,就是费舍尔的95%(后面在讲PZ值的时候,还会给大家详细说这个故事)。
那么既然这30个样本,只是个经验公式,那么在实际使用的时候,可不可以不遵守呢?比如我就只有15个样本(例如要做某个市各县区的空间自相关——我国大部分地级市,下面只有十几个区县;或者我要做北京市某个指标的空间自相关——北京也只有十六个区县)不够30个怎么办?
答案当然是肯定的。首先确定30个样本只是建议值,并非确定值,只是一般来说,如果不满30个样本做出来的结果可能不是非常显著,但是绝对不是不可以用。(当然,你要遇上某个教条型的审稿人,把你的论文给毙回来的话,虾神也是木有办法的)。
如果真的遇上这种情况,就像真要去做北京市的莫兰指数,十六个区县加入运算,导致结果不显著,有没有改进的办法呢?答案肯定是有的。
为什么说不满30个会导致结果不显著呢?因为莫兰指数需要计算某个样本的临近指标值,所以你样本数量太少,会导致临近要素也相对比较少,所以算出来结果很不理想。那么解决方法自然就是增加临近要素咯——很简单做法,就是自定义空间权重关系,增加空间临近要素。根据Esri的研究结果表明,如果你的数据属性分布偏斜严重的时候,建议每个要素最好要有8个或者8个以上的临近要素,结果才比较可靠。
至于怎么做去?等讲到空间权重矩阵的时候,我们会详细说明——如果有等不及的同学,可以看旧版本的白话空间统计里面有关空间权重矩阵的部分:(下面是旧版,里面很多内容在新版里面会重新订正——基本上会是重写,敬请期待)
首先是空间关系概念化:
然后是空间权重矩阵:
嗯,还有两个外篇:
Q3、不会用ArcGIS,还有其他软件可以做莫兰指数么?
A、当然有,ArcGIS是最全面的工具,和空间相关你只要想找,都能找到——所以通常把ArcGIS这种大型软件比喻成沃尔玛……从一次性口罩到雷明顿狙击枪(当然是美国的沃尔玛),只要你想买的东西,都能找得到……

但是如果你要买个口香糖,街边的便利店也是可以买到的……或者你觉得沃尔玛的枪支种类太少,也可以去光顾专业的枪店:

好了,言归正传——
所以,除了ArcGIS以外,还有很多软件可以做莫兰指数:
如果你会写代码的话,Python里面的PySAL包,就可以实现空间统计的大部分功能:
或者使用R语言里面的Spdep包:

这两个是我最经常用的,特别是Spdep包,具备了极其强大的空间统计分析能力,包括空间权重矩阵、多种空间自相关算法、多种空间统计学模型等等。
当然,如果你说,不会写代码怎么办呢?你还可以使用号称空间统计学第一强大的软件:Geoda:
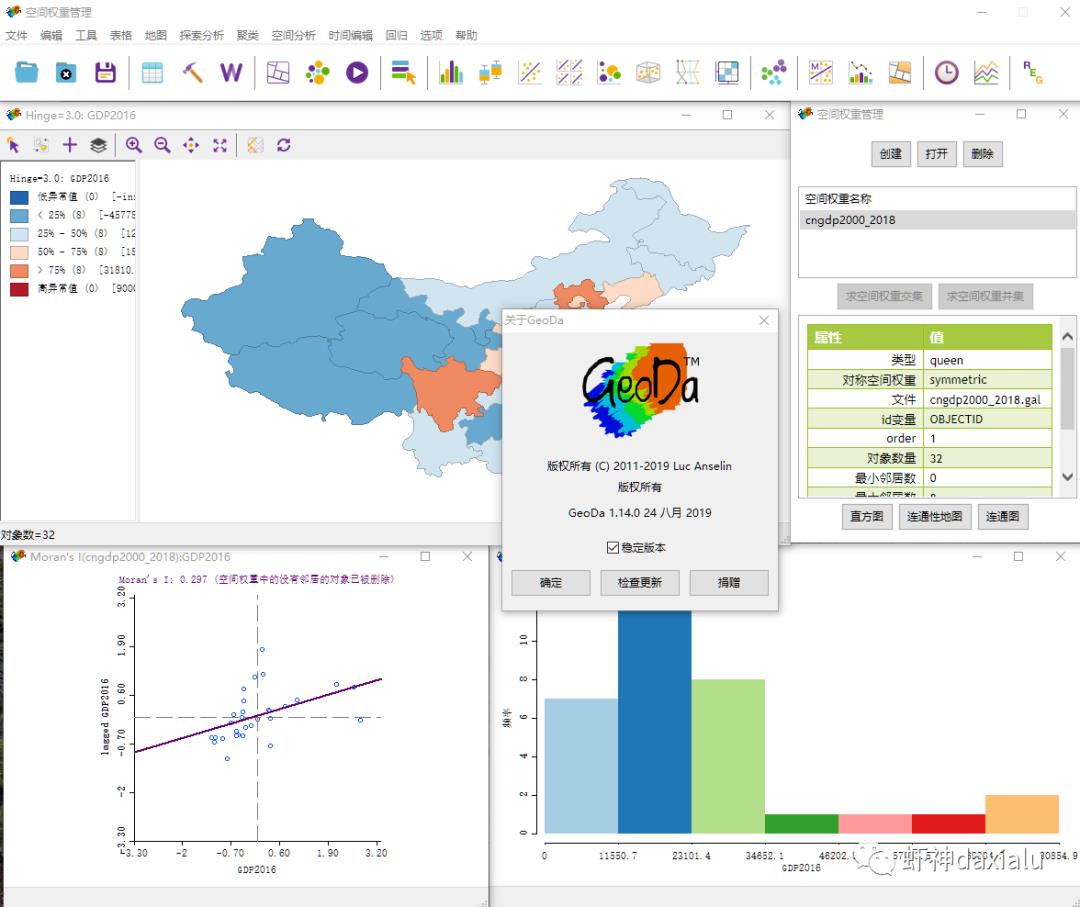
具体geoda有多出名我这里不详细说明了,在后面讲LISA的时候,还会在把这个东西给拉出来。目前关键是Geoda目前开发小组里面的负责人之一,是中国人,所以目前这个软件包括了全中文界面和说明,大家有兴趣的可以下载试用一下。
另外,Geoda软件提供的下载,有百度云盘地址——灰常中国特色,大家可以在公众号发送“geoda”来提取云盘地址。
Q4、点和面,要做空间自相关很好理解,如果我要用线来做空间自相关怎么做呢?
A:ArcGIS里面支持用线图层做空间自相关,但是仅支持下面几种空间权重模式:
即:
-
反距离模式
-
反距离平方模式
-
距离范围模式
-
无差别区域模式
-
自定义权重文件模式:
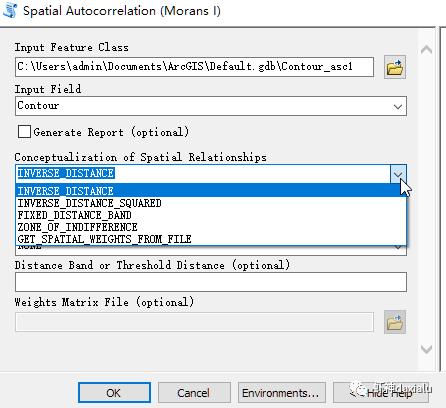
可以看见,面要素常见的共边相邻和共点相邻模式没有,所以说,做空间统计,最核心的在于如何定义空间权重关系。
在ArcGIS里面,线与线的距离,通常是测量两条线的中点的距离,所以测量出来的距离与认知并不一致……如果想按照你自定义的空间关系来做线要素的空间自相关,那又回到了那个老问题:自定义空间权重矩阵文件。
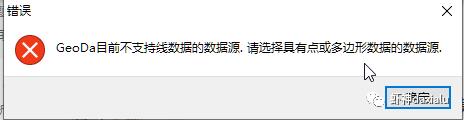
PS:geoda目前不支持线数据做空间统计:
Q5、我的数据是一堆点,只有空间位置,没有属性信息,可不可以做莫兰指数?
A:首先,这些点本身是不可以做莫兰指数的,因为做莫兰指数的话,必须有一个属性字段,而且还必须是数值型的属性字段才行。
如果没有属性字段,就只能做密度分析——这当然也是一种空间分析手段;另外还可以做多距离空间聚类分析,当然这种方法,我后面在讲多距离空间聚类分析 (Ripley's K 函数)的时候会专门写。
除了上面两种方式,那么有没有其他的办法呢?当然木有问题(虾神语录:有困难要上,木有困难,创造困难也要上)。
如果你的点,表示某种事件,比如是一起疾病病例,或者是一起刑事案件,那么可以把点规约到行政区划上面,一个点计数为1,这样行政区划上,多个数值了。
除了可以规约到行政区划上,也可以划分成网格,把点规约到网格上面,也是可以的。
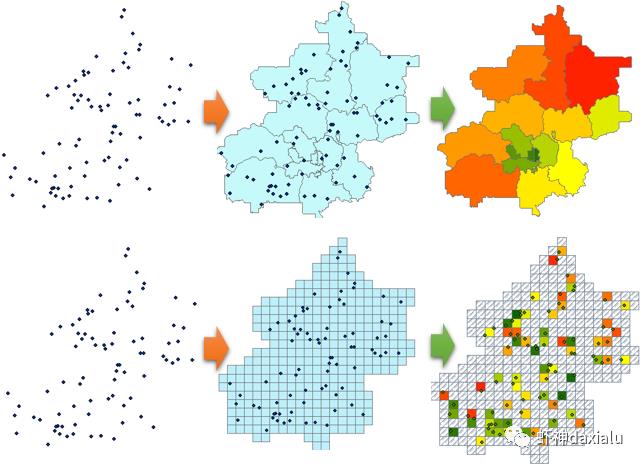
Q6、莫兰指数除了你上一节介绍的用来做空间分布的案例以外,还能做什么?
A:莫兰指数号称空间统计学第一指路标,它几乎在所有空间统计算法里面都有应用:
首先,探索空间数据是否具备一定的分布特征,是莫兰指数的天赋技能,也是他得以存在的意义,这个我们前面已经说过的度量经济空间分布特征随着时间的变化发生的变化,就是主要的应用之一,那么同样,你也可以用来研究人口、民族、社会生活等等其他的方面。
其次,在任何需要探索合适距离的场合,都可以用:
在做聚类的时候,最关键的是选择聚类的合适距离,那么你就可以用莫兰指数来进行探索。
又或是做插值分析的时候,寻找多大距离内的点来进行插值,也很重要,那么你也可以用莫兰指数来进行探索。
然后,还可以度量某些数据随着空间的变化发生的一些规律,比如总结某种社会舆情、疾病疫情等的趋势是否随空间和时间变化的传播情况 ——这些观点、疾病或趋势是继续保持隔离和集中呢,还是已经传播开并变得更加分散了。(请研究本次新冠疫情同学继续加油)
(以上案例,将在后面的文章中,逐一展开——有空的话 )
)

待续未完,下期更精彩
转发、打赏、点赞——随缘。
CSDN的被爬虫专用声明:虾神原创,公众号\\知乎:虾神说D
转发、转载和爬虫,请主动保留此声明。
以上是关于新版白话空间统计:莫兰指数小结的主要内容,如果未能解决你的问题,请参考以下文章