深度学习方法(二十):Hinton组最新无监督学习方法SimCLR介绍,以及Momentum Contrastive(MoCo)
Posted 大饼博士X
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深度学习方法(二十):Hinton组最新无监督学习方法SimCLR介绍,以及Momentum Contrastive(MoCo)相关的知识,希望对你有一定的参考价值。
本篇文章记录一下最近发表的两个比较类似的无监督representation learning工作:
- SimCLR——Hinton组的工作,第一作者Ting Chen
- MoCo v2——He Kaiming组的工作,第一作者Xinlei Chen
SimCLR
该研究一次就把无监督学习(学习后再用于分类等后续任务)的指标提升了 7-10%,甚至可以媲美有监督学习的效果。在这篇论文中,研究者发现[4]:
- 多个数据增强方法组合对于对比预测任务产生有效表示非常重要。此外,与有监督学习相比,数据增强对于无监督学习更加有用;
- 在表示和对比损失之间引入一个可学习的非线性变换(MLP)可以大幅提高模型学到的表示的质量;
- 与监督学习相比,对比学习得益于更大的批量和更多的训练步骤。
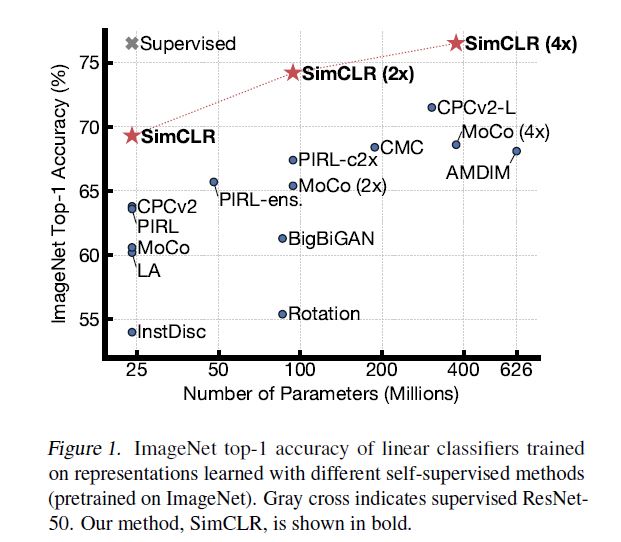
基于这些发现,他们在 ImageNet ILSVRC-2012 数据集上实现了一种新的半监督、自监督学习 SOTA 方法——SimCLR。在线性评估方面,SimCLR 实现了 76.5% 的 top-1 准确率,比之前的 SOTA 提升了 7%。在仅使用 1% 的 ImageNet 标签进行微调时,SimCLR 实现了 85.8% 的 top-5 准确率,比之前的 SOTA 方法提升了 10%。在 12 个其他自然图像分类数据集上进行微调时,SimCLR 在 10 个数据集上表现出了与强监督学习基线相当或更好的性能。
总体思路如下图:对一个Batch中的每一个样本 x x x,先随机进行两次数据增强,然后经过Encoder f f f得到特征表达 h h h,这个特征表达是用于后续finetune任务的特征表达。而在无监督学习loss之前,还要经过一个projection head g g g,这个head可以由简单的MLP网络组成,作者采用: z i = g ( h i ) = W ( 2 ) σ ( W ( 1 ) h i ) z_i = g(h_i)=W^(2)\\sigma (W^(1) h_i) zi=g(hi)=W(2)σ(W(1)hi) 两层MLP,中间是ReLU。
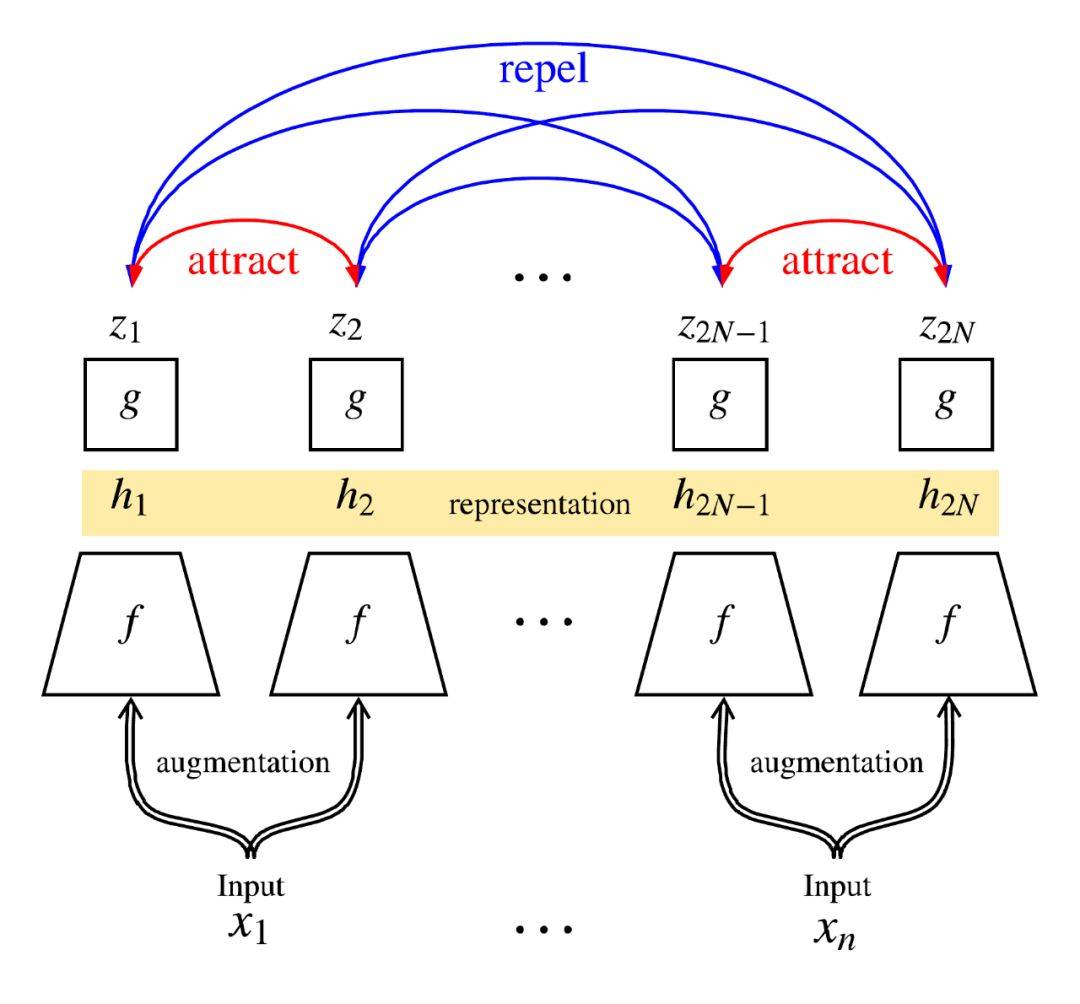
Loss采用contrastive loss,目的是让相似的图片特征相似度尽可能高,不同图片特征相似度尽可能低。

详细的程序流程如下:

数据预处理方法包括:

实验结果:无监督方法效果大跃进,在预训练之后,直接拿特征去训练一个线性分类器,精度已经可以达到ResNet50的精度了。算是最近几年的大突破了。
MoCo [2][3]
这个工作其实在去年就已经有一个版本了,当时效果还没有很好。在SimCLR出来以后借鉴了不少思路,得到了很大的提升。工作原理和SimCLR很相近,有一些优化。
下图总体介绍了一下两个算法的区别,左图是上面的SimCLR,需要有一个相对比较大的batch size N,而在计算loss的时候需要对batch内的所有 N ∗ N N*N N∗N的对都需要计算similarity,计算量比较大,而且在SimCLR算法也得益于大Batch,比较吃硬件内存。

右图是本文算法,可以看到,只需要把query送到encoder中去,而不需要很大的Batch。比较有趣的地方在于Momentum encoder,这边是用于计算positive和negative encoding的,但是这个encoder是不用反向梯度来更新的。而是直接用左边的encoder来做一个moving average。

而且,不需要一个很大的Batch(因为不需要把当前的Batch当做Negative Sample)。在Figure 1b中,两个输入表达的意思和SimCLR是类似的:一个小batch中的图片经过随机的两种数据增强,分别送到encoder和momentum encoder中去,两两对应之间会产生positive pairs。而negative pair哪里来呢?作者维护了一个queue,把之前已经产生过的batch embedding记录在queue里面,每次只需要从queue中取出来当做negative sample用(因为是之前旧的图像batch产生的,因此就假设和当前batch是不一样的,自然就是negative sample了。很聪明的想法,也不需要再计算了。)因此计算loss的代价对一个小的batch来说不论是计算量还是内存都要小很多。
训练的loss和SimCLR是一致的,Contrastive loss:
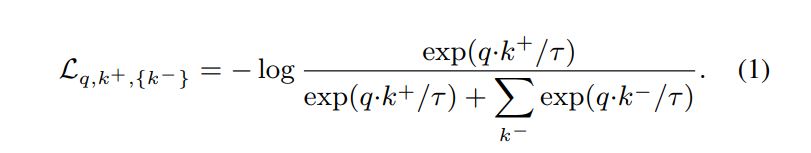
算法的流程如下,前面大致也介绍了。

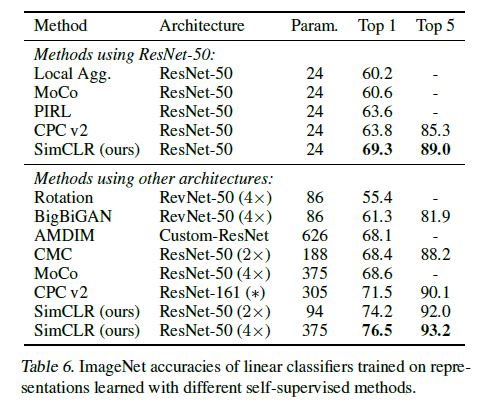
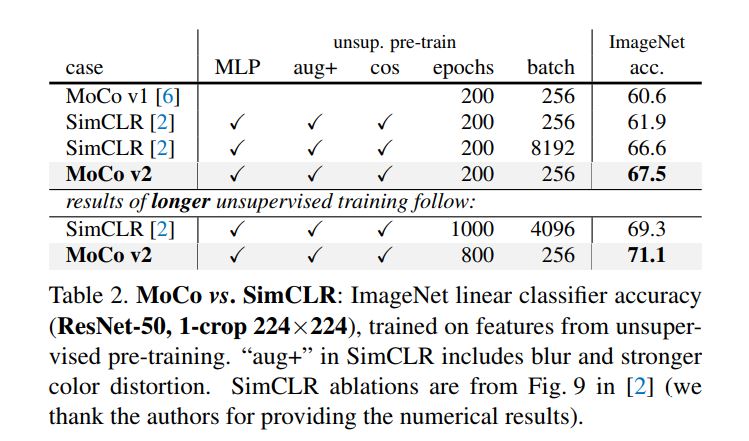
V2版本在V1版本之上做的优化:MLP的head,采用SimCLR的数据增强方法,cos的LR,可以看到加一个两层的MLP head效果最明显。最后全部加起来用。

下面是实验结果,直接和前面结果最好的SimCLR比较,在256 Batchsize下,ImageNet线性分类结果已经超越SimCLR在采用标准的ResNet50 encoder下的结果。但是作者没有比较用2x或者4x模型size时候的效果,因为SimCLR在更大模型size下效果可以大幅提升。
参考资料
[1] A Simple Framework for Contrastive Learning of Visual Representations
[2] Improved Baselines with Momentum Contrastive Learning
[3] Momentum Contrast for Unsupervised Visual Representation Learning
[4] https://www.jiqizhixin.com/articles/2020-02-15-3
[5] 如何评价Kaiming He的Momentum Contrast for Unsupervised?
以上是关于深度学习方法(二十):Hinton组最新无监督学习方法SimCLR介绍,以及Momentum Contrastive(MoCo)的主要内容,如果未能解决你的问题,请参考以下文章