Docker部署单节点ElasticSearch7+配置kibana7+X-Pack
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Docker部署单节点ElasticSearch7+配置kibana7+X-Pack相关的知识,希望对你有一定的参考价值。
参考技术A 添加如下配置:注意:
如果出现修改容器配置文件导致容器无法启动,无法再进入容器的话
使用命令将kibana容器配置文件拷贝到当前目录
docker cp kibana:/usr/share/kibana/config/kibana.yml .
然后进行修改,修改完毕回写容器
docker cp kibana.yml kibana:/usr/share/kibana/config/kibana.yml
然后再次启动容器即可
Ubuntu环境下用docker从0到1部署Elasticsearch 7集群
目录
博主爆肝了几个晚上,从0到1,终于把elasticsearch集群整出来了! 踩了很多坑, 吐血总结,我觉得只要不放弃,就一定会有奇迹!
一、镜像准备
ubuntu 20+, docker最新版, elasticsearch 7.1.15, 镜像nshou/elasticsearch-kibana, 可以通过
docker search elasticsearch
搜索到指定版本的elasticsearch镜像

docker pull nshou/elasticsearch-kibana

二、配置准备
本来想直接在Ubuntu上弄elasticsearch配置,简单的思想就是用docker cp命令将配置文件拷贝出来,然后用-v将修改后的配置挂载到docker容器里的指定路径即可,结果发现修改后的配置文件,无法挂载并覆盖容器里的配置文件。
warning: 经查,因为用vim编辑并修改的配置文件,会修改linux的inode信息,而docker容器里的配置文件是通过inode来进行映射关联的,相等则替换,因此每次都vim后, inode变了,那么也不会将docker容器里的配置文件替换掉。
解决方案: 采用echo命令往配置文件里逐行输入配置,此方式太慢,那么直接在另一台电脑上采用File zilla 工具进行配置文件的替换,注意: 首先要用docker cp 将容器里的源配置文件拷贝出来,简单讲就是不在linux环境中编辑文件。
1.ubuntu安装ssh
1)ubuntu安装ssh服务器
sudo apt-get install openssh-server
2)出现问题时,重启ssh服务即可
sudo service ssh restart
2. 开放22号端口
iptables -I INPUT -p tcp --dport 22-j ACCEPT
iptables-save
//永久保存修改
sudo apt-get install iptables-persistent
sudo netfilter-persistent save
sudo netfilter-persistent reload
//查看端口是否打开
sudo -s lsof -i: 22
如果没有iptables,那么先用sudo apt-get install iptables命令安装。
3. 配置密码可访问
切换到 /etc/ssh 目录下, 然后在sshd_config文件里添加一行配置:
PasswordAuthentication yes

重启ssh服务
sudo service ssh restart
4. 登录到ubuntu服务器
ssh准备好后,可以在windows的cmd环境里用ssh命令进行登录,如果是windows10家庭版的环境,那么在设置里打开开发者选项即可添加ssh功能,在桌面上添加一个bat,输入内容binbing为用户名:
ssh bingbing@192.168.31.166

双击执行后,输入ubuntu的开机密码,成功了的话,会看到如下内容:

三、搭建集群准备
1. FileZilla工具网盘下载
链接:https://pan.baidu.com/s/1Vd6SoQngOVzHOTsh432HDA
提取码:4g9k
2. 启动单节点
先简单启动容器,不需要任何的配置挂载。
docker run -p 9200:9200 -p 9300:9300 --name elasticsearch-node1 \\
-e "cluster.name=elasticsearch" \\
-d nshou/elasticsearch-kibana
 访问指定ip :9200,能看到elasticsearch的提示,说明容器启动成功了。
访问指定ip :9200,能看到elasticsearch的提示,说明容器启动成功了。

容器启动成功!
3. 修改并挂载配置
进入到容器查看相关信息:
docker exec -it elasticsearch-node1 bash

查看Es的配置所在的路径:
发现配置文件在容器里的路径是: /home/elasticsearch/elasticsearch-7.15.1/config, 在config目录下,为了方便可以将容器里的整个config目录拷贝出来, 在ubuntu命令窗口执行命令:
docker cp elasticsearch-node1: /home/elasticsearch/elasticsearch-7.15.1/config /home/data/elasticsearch/node1

给当前目录授权,要不然待会用filezilla传文件的时候会出现没权限的问题:

查看容器的ip地址:
docker inpsect container_id/container_name

查看是否覆盖成功:
如果挂载成功,那么容器里的配置文件会被修改掉! 如果不成功,那么在容器里检查路径是否正确,可以采用pwd命令查看当前文件所在容器中的绝对路径:
pwd
4. 搭建集群
1) 启动3个节点
在搭集群先,先用如下脚本启动3个elasticsearch容器, 注意: 映射的端口要不同才行,这里使用了9200,9201,9202.
sudo docker run -p 9200:9200 -p 9300:9300 --name elasticsearch-node1 \\
-v /home/data/elasticsearch/node1/config:/home/elasticsearch/elasticsearch-7.15.1/config \\
-d nshou/elasticsearch-kibana
sudo docker run -p 9201:9200 -p 9301:9300 --name elasticsearch-node2 \\
-v /home/data/elasticsearch/node2/config:/home/elasticsearch/elasticsearch-7.15.1/config \\
-d nshou/elasticsearch-kibana
sudo docker run -p 9202:9200 -p 9302:9300 --name elasticsearch-node3 \\
-v /home/data/elasticsearch/node3/config:/home/elasticsearch/elasticsearch-7.15.1/config \\
-d nshou/elasticsearch-kibana
问题1: 启动第二个容器的时候开始报错:
max virtual memory areas vm.max_map_count [65530] is too low,increase to at least [262144]
原因:elasticsearch用户拥有的虚拟内存太小,至少需要262144 解决。
切换到root用户,在/etc/sysctl.conf文件最后添加一行 vm.max_map_count=262144
vm.max_map_count=262144保存后,执行命令:
sudo sysctl -p
查看结果:
bingbing@bingbing-NH5x-7xRCx-RDx:~/桌面$ sudo sysctl -p
[sudo] bingbing 的密码:
vm.max_map_count = 262144
修改完毕后,再次启动容器2和容器3,启动成功后,再进行下一步。
2) 查看Ip
分别启动, 启动成功后,可以观察3个容器是否启动起来:

然后分别查看每个容器对应的IP地址: docker inspect container即可。
node1: 172.17.0.2
node2: 172.17.0.3
node3: 172.17.0.6
3) 准备配置文件
这是一位大哥整理的配置文件的字段说明,还蛮详细的,大家可以参考。
| 参数 | 说明 |
| cluster.name | 集群名称,相同名称为一个集群 |
| node.name | 节点名称,集群模式下每个节点名称唯一 |
| node.master | 当前节点是否可以被选举为master节点,是:true、否:false |
| node.data | 当前节点是否用于存储数据,是:true、否:false |
| path.data | 索引数据存放的位置, 可不配置,会放在默认位置 |
| path.logs | 日志文件存放的位置,可不配置 |
| bootstrap.memory_lock | 需求锁住物理内存,是:true、否:false |
| bootstrap.system_call_filter | SecComp检测,是:true、否:false |
| network.host | 监听地址,用于访问该es |
| network.publish_host | 可设置成内网ip,用于集群内各机器间通信 |
| http.port | es对外提供的http端口,默认 9200 |
| transport.tcp.port | TCP的默认监听端口,默认 9300 |
| discovery.seed_hosts | es7.x 之后新增的配置,写入候选主节点的设备地址,在开启服务后可以被选为主节点 |
| cluster.initial_master_nodes | es7.x 之后新增的配置,初始化一个新的集群时需要此配置来选举master |
| http.cors.enabled | 是否支持跨域,是:true,在使用head插件时需要此配置 |
| http.cors.allow-origin | “*” 表示支持所有域名 |
为了避免配置文件覆盖不上的问题,一定要注意一点是: 先将容器里的配置文件拷贝出来,然后在windows电脑上做修改,修改1个,复制成3份,然后修改各自节点的信息即可,我在windows电脑上准备3个不同的配置文件。
elasticsearch
├─ node1
│ └─ config
│ └─ elasticsearch.yml
├─ node2
│ └─ config
│ └─ elasticsearch.yml
└─ node3
└─ config
└─ elasticsearch.yml
集群配置,一共3个节点,因此3份配置。
node1:
# 设置集群名称,集群内所有节点的名称必须一致。
cluster.name: elastic
# 设置节点名称,集群内节点名称必须唯一。
node.name: node1
# 表示该节点会不会作为主节点,true表示会;false表示不会
node.master: true
# 当前节点是否用于存储数据,是:true、否:false
node.data: true
# 需求锁住物理内存,是:true、否:false
bootstrap.memory_lock: false
# 监听地址,用于访问该es
network.host: 172.17.0.2
# es对外提供的http端口,默认 9200
http.port: 9200
# TCP的默认监听端口,默认 9300
transport.tcp.port: 9300
# 设置这个参数来保证集群中的节点可以知道其它N个有master资格的节点。默认为1,对于大的集群来说,可以设置大一点的值(2-4)
discovery.zen.minimum_master_nodes: 1
# es7.x 之后新增的配置,写入候选主节点的设备地址,在开启服务后可以被选为主节点
discovery.seed_hosts: ["172.17.0.3:9300", "172.17.0.2:9300", "172.17.0.6:9300"]
discovery.zen.fd.ping_timeout: 1m
discovery.zen.fd.ping_retries: 5
# es7.x 之后新增的配置,初始化一个新的集群时需要此配置来选举master
cluster.initial_master_nodes: ["node1", "node2", "node3"]
# 是否支持跨域,是:true,在使用head插件时需要此配置
http.cors.enabled: true
# “*” 表示支持所有域名
http.cors.allow-origin: "*"
action.destructive_requires_name: true
action.auto_create_index: .security,.monitoring*,.watches,.triggered_watches,.watcher-history*
xpack.security.enabled: false
xpack.monitoring.enabled: true
xpack.graph.enabled: false
xpack.watcher.enabled: false
xpack.ml.enabled: false
node2:
# 设置集群名称,集群内所有节点的名称必须一致。
cluster.name: elastic
# 设置节点名称,集群内节点名称必须唯一。
node.name: node2
# 表示该节点会不会作为主节点,true表示会;false表示不会
node.master: true
# 当前节点是否用于存储数据,是:true、否:false
node.data: true
# 需求锁住物理内存,是:true、否:false
bootstrap.memory_lock: false
# 监听地址,用于访问该es
network.host: 172.17.0.3
# es对外提供的http端口,默认 9200
http.port: 9200
# TCP的默认监听端口,默认 9300
transport.tcp.port: 9300
# 设置这个参数来保证集群中的节点可以知道其它N个有master资格的节点。默认为1,对于大的集群来说,可以设置大一点的值(2-4)
discovery.zen.minimum_master_nodes: 1
# es7.x 之后新增的配置,写入候选主节点的设备地址,在开启服务后可以被选为主节点
discovery.seed_hosts: ["172.17.0.3:9300", "172.17.0.2:9300", "172.17.0.6:9300"]
discovery.zen.fd.ping_timeout: 1m
discovery.zen.fd.ping_retries: 5
# es7.x 之后新增的配置,初始化一个新的集群时需要此配置来选举master
cluster.initial_master_nodes: ["node1", "node2", "node3"]
# 是否支持跨域,是:true,在使用head插件时需要此配置
http.cors.enabled: true
# “*” 表示支持所有域名
http.cors.allow-origin: "*"
action.destructive_requires_name: true
action.auto_create_index: .security,.monitoring*,.watches,.triggered_watches,.watcher-history*
xpack.security.enabled: false
xpack.monitoring.enabled: true
xpack.graph.enabled: false
xpack.watcher.enabled: false
xpack.ml.enabled: false
node3:
# 设置集群名称,集群内所有节点的名称必须一致。
cluster.name: elastic
# 设置节点名称,集群内节点名称必须唯一。
node.name: node3
# 表示该节点会不会作为主节点,true表示会;false表示不会
node.master: true
# 当前节点是否用于存储数据,是:true、否:false
node.data: true
# 需求锁住物理内存,是:true、否:false
bootstrap.memory_lock: false
# 监听地址,用于访问该es
network.host: 172.17.0.6
# es对外提供的http端口,默认 9200
http.port: 9200
# TCP的默认监听端口,默认 9300
transport.tcp.port: 9300
# 设置这个参数来保证集群中的节点可以知道其它N个有master资格的节点。默认为1,对于大的集群来说,可以设置大一点的值(2-4)
discovery.zen.minimum_master_nodes: 1
# es7.x 之后新增的配置,写入候选主节点的设备地址,在开启服务后可以被选为主节点
discovery.seed_hosts: ["172.17.0.3:9300", "172.17.0.2:9300", "172.17.0.6:9300"]
discovery.zen.fd.ping_timeout: 1m
discovery.zen.fd.ping_retries: 5
# es7.x 之后新增的配置,初始化一个新的集群时需要此配置来选举master
cluster.initial_master_nodes: ["node1", "node2", "node3"]
# 是否支持跨域,是:true,在使用head插件时需要此配置
http.cors.enabled: true
# “*” 表示支持所有域名
http.cors.allow-origin: "*"
action.destructive_requires_name: true
action.auto_create_index: .security,.monitoring*,.watches,.triggered_watches,.watcher-history*
xpack.security.enabled: false
xpack.monitoring.enabled: true
xpack.graph.enabled: false
xpack.watcher.enabled: false
xpack.ml.enabled: false
注意: 每个节点的 http.port都为9200, transport.tcp.port为 9300,9200是对外的HTTP请求的接口,9300是集群间节点进行TCP通信的端口。
挂载配置后,然后启动容器一直报错, 集群启动不起来,节点各自分家, 每个都是master。。。。

学会看日志能够帮我们排查问题,这个时候,我们可以进入到容器里查看日志, 选举master信息:
bingbing@bingbing-NH5x-7xRCx-RDx:~/桌面$ docker exec -it elasticsearch-node1 bash
elasticsearch@144ff2559dff:~$ cat elasticsearch-7.15.1/logs/elastic.log

从日志里好像没看出什么问题,然后我再次检查配置文件,经排查,发现在host列表里,","和引号之间需要有一个空格" ",如果没有空格,那么无法形成集群。
discovery.seed_hosts: ["172.17.0.3:9300", "172.17.0.2:9300", "172.17.0.6:9300"]
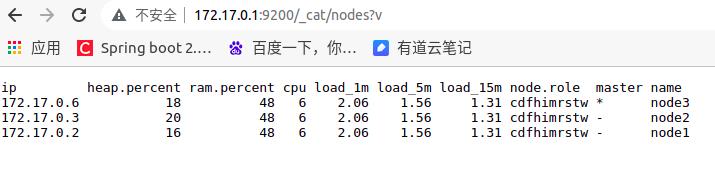
修改完配置后,再次按照顺序启动node1,node2,node3,都启动成功后,可以间隔时间访问 http://172.17.0.2:9200/_cat/nodes?v, 会发现页面上显示的结果在改变,因为这个时候elasticsearch在选举master节点,过半分钟后,再次查看页面。
ip heap.percent ram.percent cpu load_1m load_5m load_15m node.role master name 172.17.0.6 21 43 5 1.26 2.00 1.90 cdfhimrstw - node3 172.17.0.3 16 43 5 1.26 2.00 1.90 cdfhimrstw - node2 172.17.0.2 15 43 5 1.26 2.00 1.90 cdfhimrstw * node1

历经了七七四十九次的重启,终于看到了我想要的结果!。。。。。

然而过一段时间后,再次访问master节点,相同地址: http://172.17.0.2:9200/_cat/nodes?v

只有node1在这,node2和node3去哪儿了呢? 访问: http://172.17.0.6:9200/_cat/nodes?v

发现node2和node3形成了另外一个集群, node3被选举为了master。这种场景有点像分布式环境中的脑裂问题一样,master脱离集群后,从节点重新选举一个master出来,两个master的节点就会出现不一致的情况,就像"脑裂一样"!

进入到节点1的容器中查看原因:
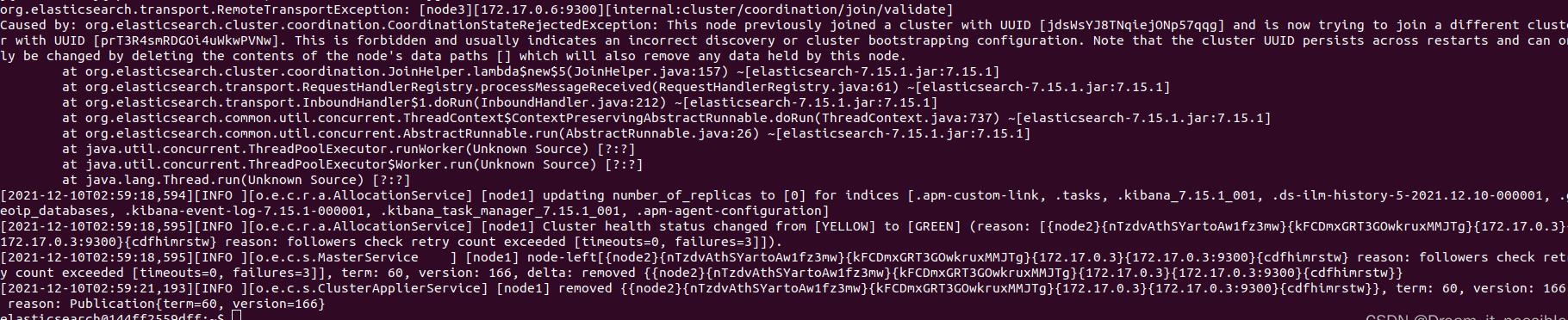
org.elasticsearch.transport.RemoteTransportException: [node1][172.17.0.2:9300][internal:cluster/coordination/join/validate]
Caused by: org.elasticsearch.cluster.coordination.CoordinationStateRejectedException: This node previously joined a cluster with UUID [jdsWsYJ8TNqiejONp57qqg] and is now trying to join a different cluster with UUID [prT3R4smRDGOi4uWkwPVNw]. This is forbidden and usually indicates an incorrect discovery or cluster bootstrapping configuration. Note that the cluster UUID persists across restarts and can only be changed by deleting the contents of the node's data paths [] which will also remove any data held by this node.
大概的意思是: 这个节点之前加入了了一个UUID为jdsWsYJ8TNqiejONp57qqg 的集群,现在又尝试加入到另外一个集群里,这是不允许的。
接着直接访问docker容器的ip地址,然后响应报错:
"error": "root_cause": [ "type": "master_not_discovered_exception", "reason": null ], "type": "master_not_discovered_exception", "reason": null , "status": 503
我以为自己又配错了,然而过一段时间后,再次访问该节点,发现该节点又重新加入到之前的集群里。

不过,这个时候的master节点已经成为了node3。
我看到这种现象,心里已经有一万匹🏇在奔腾了。。。为啥子一会在集群里,一会又退出,一会又加入!
百思不得其解,只好继续问度娘了,cluster/coordination/join/validate 这个问题经查,一个老哥给出了解决方案,进入到指定节点的容器里,把data文件夹给删掉,是因为之前我一直用的node1,然后已经有了数据,删除data重新启动就好了,我按照此方式重试,结果解决了!
然后我经过一段时间的观测,集群的3个节点稳定了!

从这个现象中说明,在启动的时候集群中的节点数有可能是会变动的,master节点也不是固定不变的。如果有节点中途退出了集群,那么elasticsearch可能会重新选举一个master,退出了的节点,为维持集群平衡也会再次加入到集群里,集群的内部可能会发生变动,但是对外提供的接口保持高可用,这也是elasticsearch集群最终实现的目的。
4) 验证集群是否搭建成功
最后为了验证集群是否成功,我调用了一个创建索引的API,创建一个test索引:
@Test
public void testCreateIndex() throws IOException
CreateIndexRequest createIndexRequest = new CreateIndexRequest("test");
CreateIndexResponse response = restHighLevelClient.indices().create(createIndexRequest, RequestOptions.DEFAULT);
System.out.println(response);
创建成功:
 如果elasticsearch集群中所有的节点都能get到test这个索引,那么表示集群中的节点是正常通信的,也就是说集群搭建成功。
如果elasticsearch集群中所有的节点都能get到test这个索引,那么表示集群中的节点是正常通信的,也就是说集群搭建成功。
访问 http://172.17.0.1:9200/_cat/nodes?v和访问http://172.17.0.2:9200/_cat/nodes?v,http://172.17.0.3:9200/_cat/nodes?v,http://172.17.0.6:9200/_cat/nodes?v的返回都是一样的,其中172.17.2.1是docker容器中的gateway。
ip heap.percent ram.percent cpu load_1m load_5m load_15m node.role master name 172.17.0.6 27 49 6 2.78 1.65 1.33 cdfhimrstw * node3 172.17.0.3 30 49 6 2.78 1.65 1.33 cdfhimrstw - node2 172.17.0.2 14 49 6 2.78 1.65 1.33 cdfhimrstw - node1
然后查看test索引在 172.17.0.3,172.17.0.2,172.17.0.6中是否存在。
访问: http://172.17.0.2:9200/test
 由图可知, 存在172.17.0.2节点里。
由图可知, 存在172.17.0.2节点里。
访问: http://172.17.0.3:9200/test
 由图可知, test索引存在172.17.0.3节点里。
由图可知, test索引存在172.17.0.3节点里。
最后访问: http://172.17.0.6:9200/test
 由图可知, test索引存在172.17.0.6节点里。
由图可知, test索引存在172.17.0.6节点里。
说明集群已经搭建成功,所有节点的信息完成同步,保持一致!
参考: ElasticSearch7.1.1集群搭建_smile in spring的博客-CSDN博客_elasticsearch7集群搭建
以上是关于Docker部署单节点ElasticSearch7+配置kibana7+X-Pack的主要内容,如果未能解决你的问题,请参考以下文章
Elasticsearch7.8.0版本进阶——分布式集群(单节点集群)