JUC系列并发容器之ConcurrentHashMap(JDK1.8版)扩容图解说明
Posted 顧棟
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了JUC系列并发容器之ConcurrentHashMap(JDK1.8版)扩容图解说明相关的知识,希望对你有一定的参考价值。
ConcurrentHashMap(JDK1.8)扩容说明
文章目录
扩容过程
触发条件
第一种场景在新增结点的时候,在addCount中检查元素个数时,若到达扩容阈值时,若数组长度小于64会调用tryPresize对Node数组进行2倍扩容transfer方法对结点的位置进行重分配。
第二种场景是在新增结点的时候,在当桶中链表结点数超过8个,会调用treeifyBin尝试进行将链表转为红黑树,但是若数组小于64,则也会对Node数组进行扩容,不链表转为红黑树。
基本原理
新建一个Node数组,其长度为旧数组长度的2倍,然后将旧的元素迁移到新数组中。
可以有一个或多个线程一起进行数据迁移,单核不支持多线程并行迁移。
迁移的过程中,旧数组的长度是N,每个线程扩容一段,一段的长度使用遍历stride(步长)来表示,为了降低资源竞争频率,stride最小的范围长度是16。transferIndex表示整个数组扩容的进度,每个调用tranfer的线程会对当前旧table中[transferIndex-stride, transferIndex-1]位置的结点进行迁移,不过是倒叙的方式进行的。
步骤
具体实现主要集中在transfer(Node<K,V>[] tab, Node<K,V>[] nextTab)方法中。
-
计算出stride的值
MIN_TRANSFER_STRIDE是16。if ((stride = (NCPU > 1) ? (n >>> 3) / NCPU : n) < MIN_TRANSFER_STRIDE) stride = MIN_TRANSFER_STRIDE; -
首次扩容,进行新Node数组的初始化。
if (nextTab == null) // initiating try @SuppressWarnings("unchecked") Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n << 1]; nextTab = nt; catch (Throwable ex) // try to cope with OOME sizeCtl = Integer.MAX_VALUE; return; nextTable = nextTab; // 将 transferIndex 指向最右边的桶,也就是数组索引下标最大的位置 transferIndex = n; -
由advance变量控制桶的遍历,是否进行下一个桶的迁移;由finishing变量控制数组整个扩容是否结束。
-
for循环中进行不通过条件处理,while结构体中,通过CAS操作TRANSFERINDEX,成功执行CAS,说明获取这个桶的结点迁移执行权,多个线程之间也是通过TRANSFERINDEX并行进行不同桶的迁移,在对应的桶的迁移时,advance为false。
处理的逻辑分为4种:
case1:当前的任务是整个数组扩容的最后一个任务或者扩容冲突。
if (i < 0 || i >= n || i + n >= nextn) int sc; //扩容结束后做后续工作,将 nextTable 设置为 null,表示扩容已结束,将 table 指向新数组,sizeCtl 设置为扩容阈值 if (finishing) nextTable = null; table = nextTab; sizeCtl = (n << 1) - (n >>> 1); return; //每当一条线程扩容结束就会更新一次 sizeCtl 的值,进行减 1 操作 if (U.compareAndSwapInt(this, SIZECTL, sc = sizeCtl, sc - 1)) //若成立,说明该线程不是扩容大军里面的最后一条线程,直接return回到上层while循环 if ((sc - 2) != resizeStamp(n) << RESIZE_STAMP_SHIFT) return; //(sc - 2) == resizeStamp(n) << RESIZE_STAMP_SHIFT 说明这条线程是最后一条扩容线程 //之所以能用这个来判断是否是最后一条线程,因为第一条扩容线程进行了如下操作: // U.compareAndSwapInt(this, SIZECTL, sc, (rs << RESIZE_STAMP_SHIFT) + 2) //除了修改结束标识之外,还得设置 i = n; 以便重新检查一遍数组,防止有遗漏未成功迁移的桶 finishing = advance = true; i = n; // recheck before commitcase2:该桶为空即Node数组i下标中为null。
else if ((f = tabAt(tab, i)) == null) // 遇到数组上空的位置直接放置一个占位对象,以便查询操作的转发和标识当前处于扩容状态 advance = casTabAt(tab, i, null, fwd);case3:该桶(Node数组i下标的元素)已经完成迁移。
else if ((fh = f.hash) == MOVED) // 数组上遇到hash值为MOVED,也就是 -1 的位置,说明该位置已经被其他线程迁移过了,将 advance 设置为 true ,以便继续往下一个桶检查并进行迁移操作 advance = true; // already processedcase4:该桶还未迁移,根据桶首结点的hash值进行链表迁移或红黑树迁移。
链表迁移:找到最后一个与相邻结点runbit不同的结点lastRun。通过这个lastRun将链表分为两个子链表ln和hn,将他们链接到新数组的
i和i+n的位置。红黑树迁移:同样将列表拆分为两个子链表,在插入新数组之前会判断子链表的结点是否满足红黑树个数要求,进行红黑树与链表转换。
synchronized (f) if (tabAt(tab, i) == f) Node<K,V> ln, hn; //该桶下为链表结构 if (fh >= 0) //由于n是2的幂次方(所有二进制位中只有一个1),如n=16(0001 0000),第4位为1,那么hash&n后的值第4位只能为0或1。所以可以根据hash&n的结果将所有结点分为两部分。 int runBit = fh & n; Node<K,V> lastRun = f; //遍历整条链表,找出 lastRun 节点 for (Node<K,V> p = f.next; p != null; p = p.next) int b = p.hash & n; if (b != runBit) runBit = b; lastRun = p; //根据 lastRun 节点的高位标识(0 或 1),首先将 lastRun设置为 ln 或者 hn 链的末尾部分节点,后续的节点使用头插法拼接 if (runBit == 0) ln = lastRun; hn = null; else hn = lastRun; ln = null; //使用高位和低位两条链表进行迁移,使用头插法拼接链表 for (Node<K,V> p = f; p != lastRun; p = p.next) int ph = p.hash; K pk = p.key; V pv = p.val; if ((ph & n) == 0) ln = new Node<K,V>(ph, pk, pv, ln); else hn = new Node<K,V>(ph, pk, pv, hn); //setTabAt方法调用的是 Unsafe 类的 putObjectVolatile 方法 //使用 volatile 方式的 putObjectVolatile 方法,能够将数据直接更新回主内存,并使得其他线程工作内存的对应变量失效,达到各线程数据及时同步的效果 //使用 volatile 的方式将 ln 链设置到新数组下标为 i 的位置上 setTabAt(nextTab, i, ln); //使用 volatile 的方式将 hn 链设置到新数组下标为 i + n(n为原数组长度) 的位置上 setTabAt(nextTab, i + n, hn); //迁移完成后使用 volatile 的方式将占位对象设置到该 hash 桶上,该占位对象的用途是标识该hash桶已被处理过,以及查询请求的转发作用 setTabAt(tab, i, fwd); //advance 设置为 true 表示当前 hash 桶已处理完,可以继续处理下一个 hash 桶 advance = true; //该桶下为红黑树结构 else if (f instanceof TreeBin) TreeBin<K,V> t = (TreeBin<K,V>)f; //lo 为低位链表头结点,loTail 为低位链表尾结点,hi 和 hiTail 为高位链表头尾结点 TreeNode<K,V> lo = null, loTail = null; TreeNode<K,V> hi = null, hiTail = null; int lc = 0, hc = 0; //同样也是使用高位和低位两条链表进行迁移 //使用for循环以链表方式遍历整棵红黑树,使用尾插法拼接 ln 和 hn 链表 for (Node<K,V> e = t.first; e != null; e = e.next) int h = e.hash; //这里面形成的是以 TreeNode 为节点的链表 TreeNode<K,V> p = new TreeNode<K,V> (h, e.key, e.val, null, null); if ((h & n) == 0) if ((p.prev = loTail) == null) lo = p; else loTail.next = p; loTail = p; ++lc; else if ((p.prev = hiTail) == null) hi = p; else hiTail.next = p; hiTail = p; ++hc; //形成中间链表后会先判断是否需要转换为红黑树: //1、如果符合条件则直接将 TreeNode 链表转为红黑树,再设置到新数组中去 //2、如果不符合条件则将 TreeNode 转换为普通的 Node 节点,再将该普通链表设置到新数组中去 //(hc != 0) ? new TreeBin<K,V>(lo) : t 这行代码的用意在于,如果原来的红黑树没有被拆分成两份,那么迁移后它依旧是红黑树,可以直接使用原来的 TreeBin 对象 ln = (lc <= UNTREEIFY_THRESHOLD) ? untreeify(lo) : (hc != 0) ? new TreeBin<K,V>(lo) : t; hn = (hc <= UNTREEIFY_THRESHOLD) ? untreeify(hi) : (lc != 0) ? new TreeBin<K,V>(hi) : t; //setTabAt方法调用的是 Unsafe 类的 putObjectVolatile 方法 //使用 volatile 方式的 putObjectVolatile 方法,能够将数据直接更新回主内存,并使得其他线程工作内存的对应变量失效,达到各线程数据及时同步的效果 //使用 volatile 的方式将 ln 链设置到新数组下标为 i 的位置上 setTabAt(nextTab, i, ln); //使用 volatile 的方式将 hn 链设置到新数组下标为 i + n(n为原数组长度) 的位置上 setTabAt(nextTab, i + n, hn); //迁移完成后使用 volatile 的方式将占位对象设置到该 hash 桶上,该占位对象的用途是标识该hash桶已被处理过,以及查询请求的转发作用 setTabAt(tab, i, fwd); //advance 设置为 true 表示当前 hash 桶已处理完,可以继续处理下一个 hash 桶 advance = true;
图解
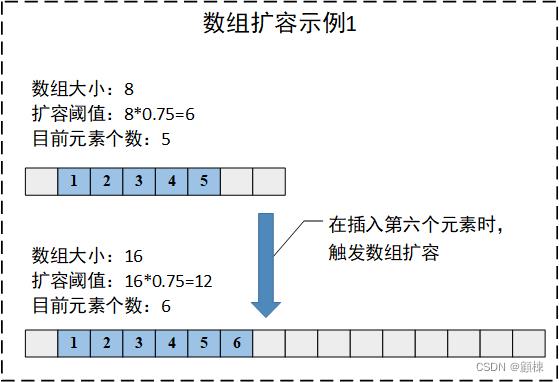
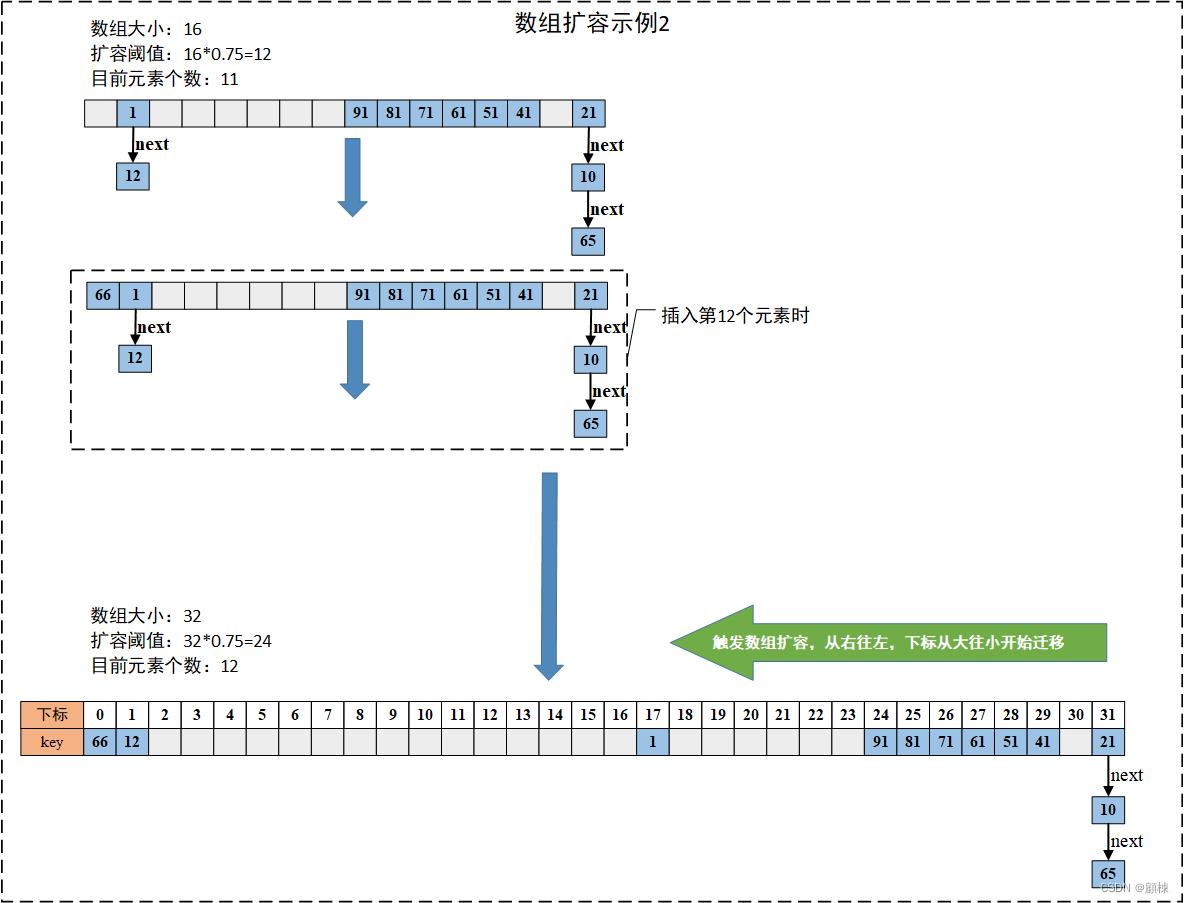
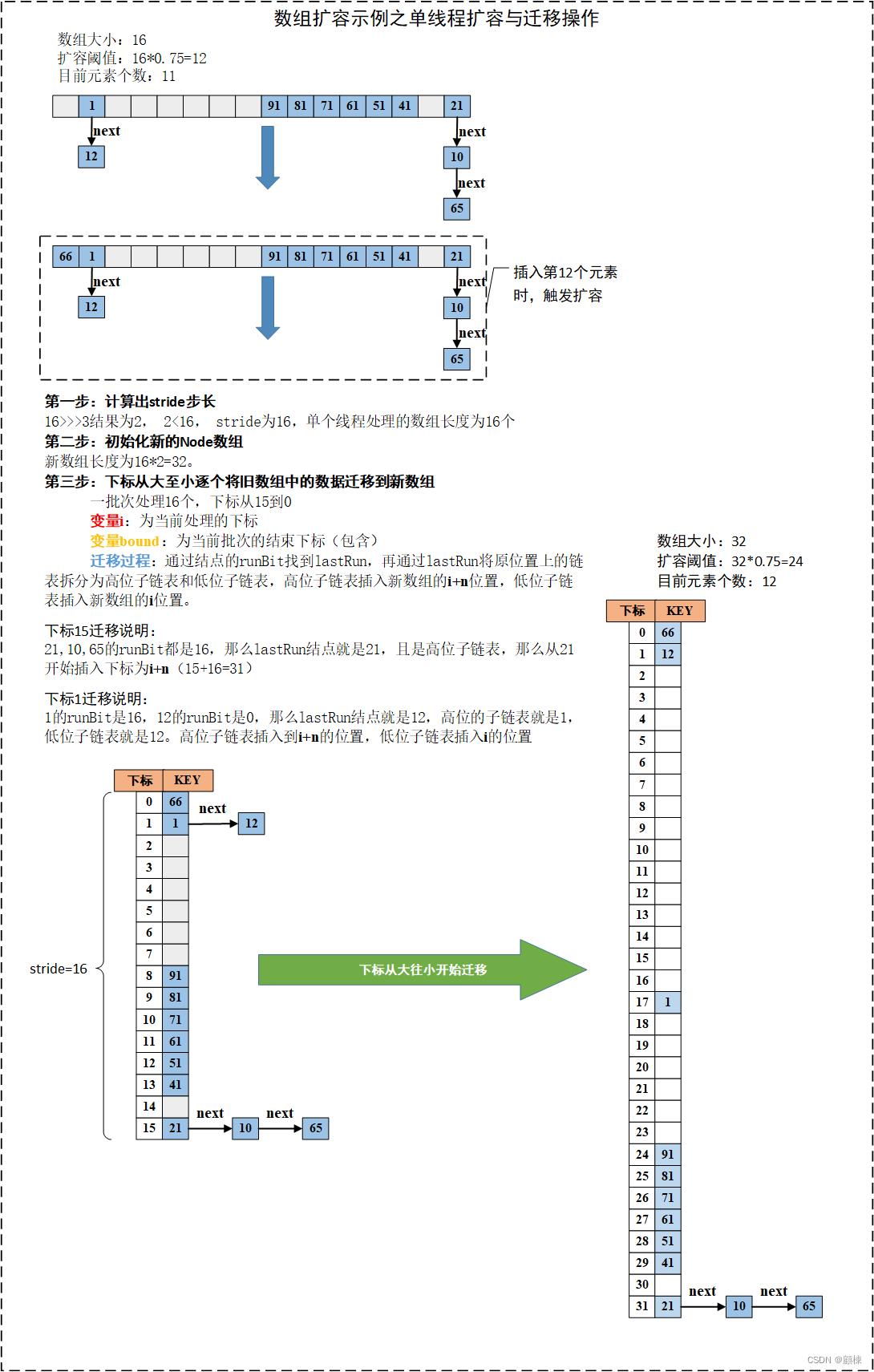
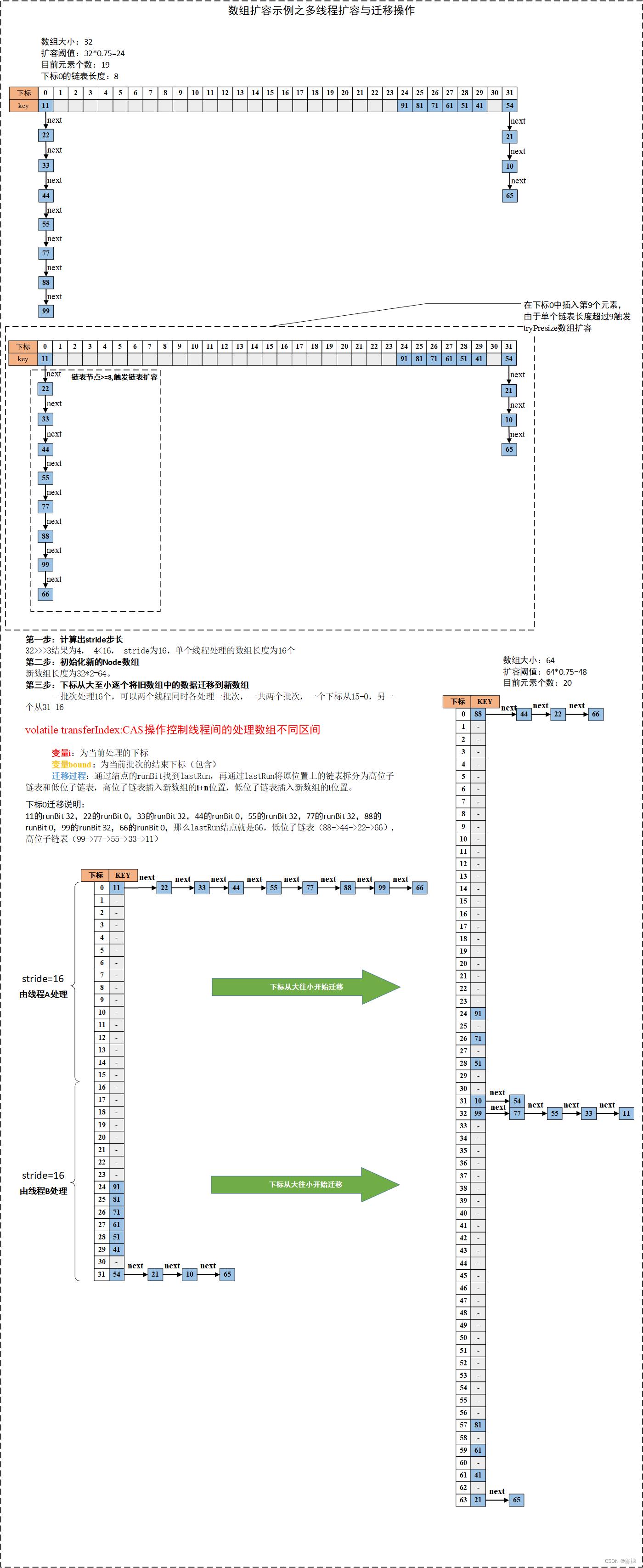
以上是关于JUC系列并发容器之ConcurrentHashMap(JDK1.8版)扩容图解说明的主要内容,如果未能解决你的问题,请参考以下文章
JUC系列并发容器之ConcurrentLinkedQueue(JDK1.8版)
JUC系列并发容器之ConcurrentHashMap(JDK1.8版)