Python 数据分析 —— Pandas ②
Posted 苍夜月明
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python 数据分析 —— Pandas ②相关的知识,希望对你有一定的参考价值。
文章目录
读入数据
首先:读入 movie_data.xlsx
df = pd.read_excel(r'D:\\数据分析\\movie_data.xlsx')
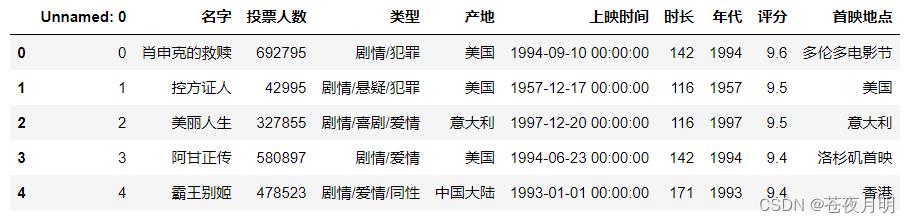
查看一下前5行数据
df.head()
数据格式转换
在做数据分析时,原始数据往往会因为各种各样的原因产生各种数据格式问题。
数据格式是我们非常需要注意的一点,数据格式错误往往会造成很严重的后果。
并且,很多异常值在我们经过格式转换后才会发现,对我们规整数据,清洗数据有着重要的作用。
常用方法:
- dtypes
- astype
- loc
查看格式
df.dtypes

查看某一列数据的具体格式
df['投票人数'].dtype

将产地转化为字符串格式
先看产地格式
df['产地'].dtype

用 astype 转化
df['产地'] = df['产地'].astype('str')
将年代转化为整数格式
df['年代'] = df['年代'].astype('int')

报错了,因为这一列数据中有个异常数据,不能成功转化(一颗老鼠屎,坏了一锅汤)
接下来要处理异常值了,只有异常值处理好了才能修改整列的数据类型
1. 根据报错数据,找到对应的行位置
df[df.年代 == '2008\\u200e']

这样看还看不出问题,就得用 .values 了
df[df.年代 == '2008\\u200e']['年代'].values

果然年代有问题
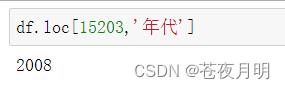
2.用loc修改
df.loc[15203,'年代'] = 2008
修改成功!
再次转换
df.年代 = df.年代.astype('int')
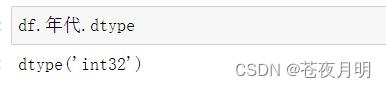
这次成功转换成了int型
将时长转化为整数格式
df.时长 = df.时长.astype('int')

果不其然报错了,那就改吧
把 8U 列找出来
df[df.时长 == '8U']

改掉
df.loc[31636,'时长'] = 8
转换
df.时长 = df.时长.astype('int')

又报错了
把 12J 列找出来
df.loc[31636,'时长'] = 8

改掉
df.loc[23941,'时长'] = 12
再转换
df.时长 = df.时长.astype('int')
又又又报错了
再把 12J 列找出来
改掉
df.loc[23941,'时长'] = 12
再再转换
df.时长 = df.时长.astype('int')
排序
dataframe.sort_values 方法默认升序,ascending = False 为降序
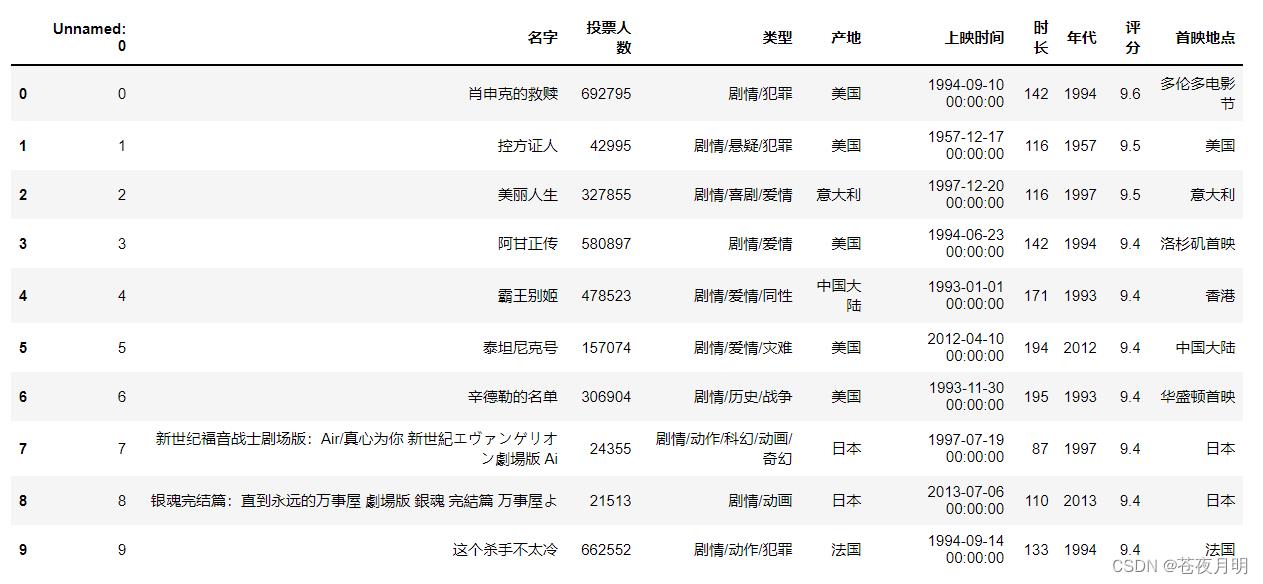
默认排序
按 index 从小到大来
df.head(10)
按照投票人数排序
dataframe.sort_values() 默认升序排列
df.sort_values(by = '投票人数')
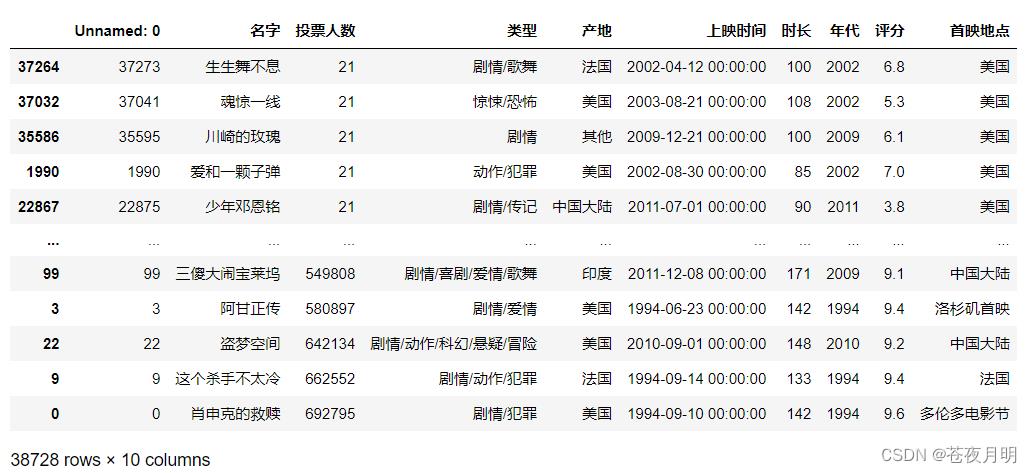
参数 ascending = False 为降序排列
df.sort_values(by = '投票人数',ascending = False)
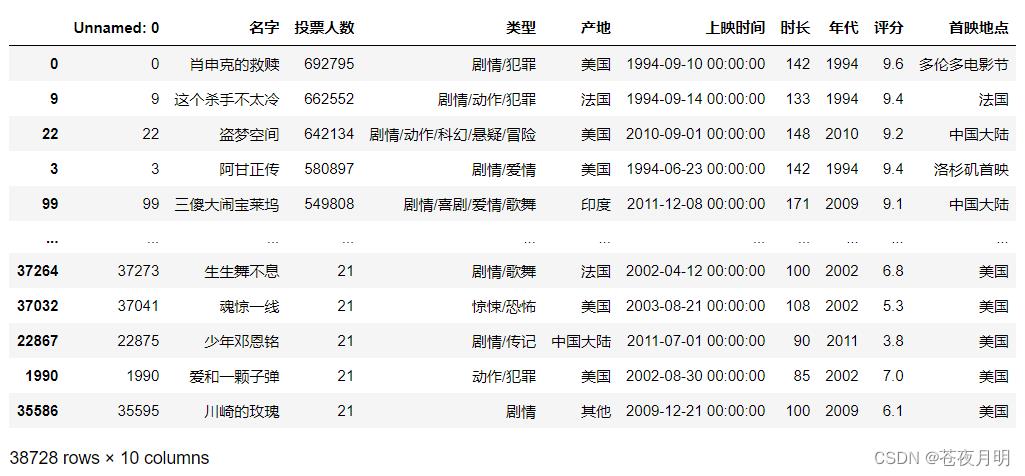
按照年代排序
一样的步骤
默认升序
df.sort_values('年代')

降序
df.sort_values('年代',ascending = False)
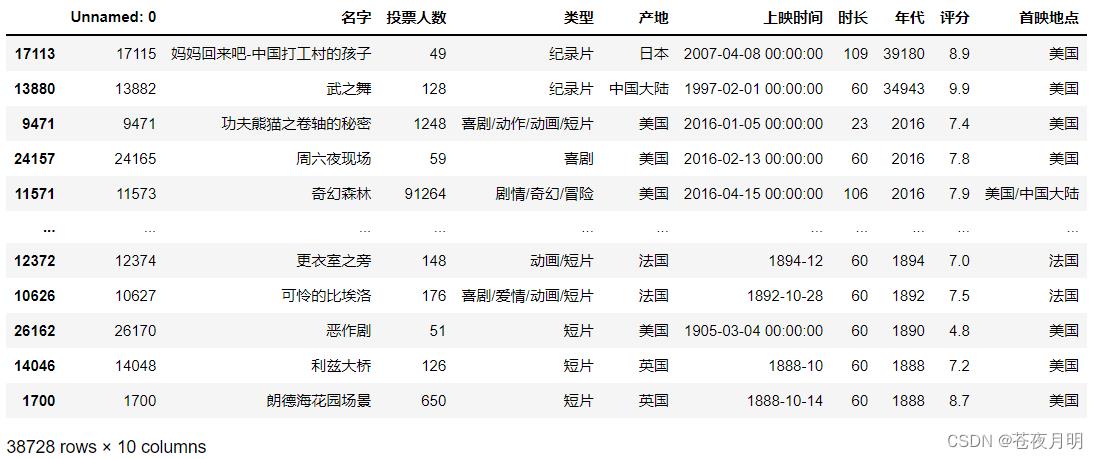
多个值排序
先按照评分排序;如果评分相同,再按照投票排序
给 by 传多个参数就行,用列表!
df.sort_values(by = ['评分','投票人数'],ascending = False)
列表里元素的先后顺序,就是排序的先后顺序
基本统计分析
描述性统计
dataframe.describe():对dataframe中的数值型数据进行描述性统计。
df.describe()
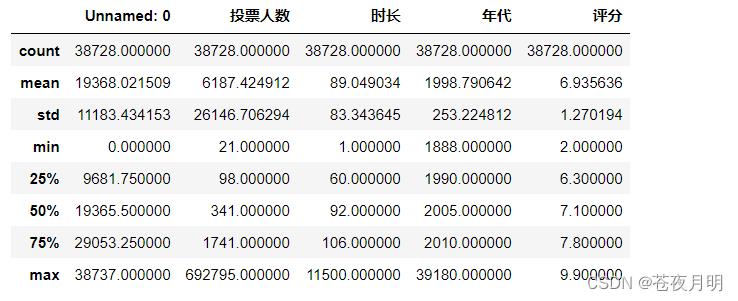
通过观察发现,时长的 max 是11500,不可能;年代的 max 是39180,更不可能。
通过描述性统计,可以发现一些异常值,很多异常值往往需要自己逐步发现
df[df.时长>1000] # 挑出异常数据

df[df.年代>2022] # 挑出异常数据

删除异常数据
df.drop(df[df.时长>1000].index,inplace = True)
df.drop(df[df.年代>2022].index,inplace = True)
可以直接用 挑出异常数据.index 高级drop
可此时有个问题,删了几条数据导致index不连续了。
不用着急,不用着急,有方法!
df.index = range(len(df))
给index重新赋值,而且不用事先查看到底多少条数据,因为可以直接len(df),简便。
最值
df.投票人数.max() # 一定得加()啊!!!

df.投票人数.min()

df.评分.max()

df.评分.min()

均值和中值
均值(平均数)用 mean()
df.投票人数.mean()
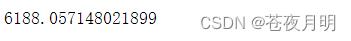
中值(中位数)用 median()
df.投票人数.median()


方差和标准差
方差用 var()
df.评分.var()
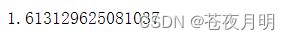
标准差用 std()
df.评分.std()
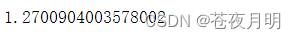
求和
df.投票人数.sum()

相关系数和协方差
相关系数用 corr()
因为相关系数反映的是两个东西之间的相关性,所以这时需要两个变量了,多个变量用列表
投票人数和评分的相关系数
df[['投票人数','评分']].corr()

投票人数和评分的相关系数是:0.122956,正相关且相关性弱。
协方差用 cov()
协方差概念:
协方差(Covariance)在概率论和统计学中用于衡量两个变量的总体误差。而方差是协方差的一种特殊情况,即当两个变量是相同的情况。
协方差表示的是两个变量的总体的误差,这与只表示一个变量误差的方差不同。如果两个变量的变化趋势一致,也就是说如果其中一个大于自身的期望值,另外一个也大于自身的期望值,那么两个变量之间的协方差就是正值。如果两个变量的变化趋势相反,即其中一个大于自身的期望值,另外一个却小于自身的期望值,那么两个变量之间的协方差就是负值。
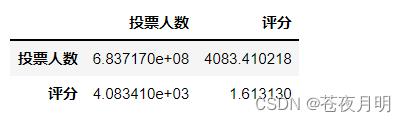
投票人数和评分的协方差
df[['投票人数','评分']].cov()
计数
len:数据长度unique:去重,看唯一值replace:数据替换value_counts:具体取值出现了多少次
查看电影数量
len(df)

有几条数据,就有多少部电影
查看有多少种产地
df.产地.unique()

len(df.产地.unique())

影片来自28个国家
产地中包含了一些重复数据,比如美国和USA,德国和西德,俄罗斯和苏联
我们可以通过数据替换的方法将这些相同国家的电影数据合并一下。
df.产地.replace('USA','美国',inplace = True)
df.产地.replace('西德','德国',inplace = True)
df.产地.replace('苏联','俄罗斯',inplace = True)
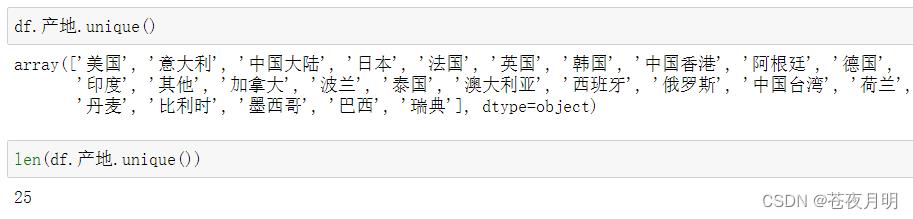
数据替换后,影片来自25个国家
计算每一年电影的数量
df.年代.value_counts()

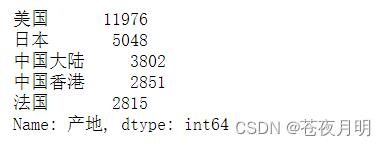
电影产出前5位的产地
df.产地.value_counts().head()
保存数据
df.to_excel(r'D:\\数据分析\\movie_data2.xlsx')
数据透视
Excel中数据透视表的使用非常广泛。Pandas也提供类似功能的函数:pivot_table
使用 pivot_table 需要注意:
- 确保理解了被分析的数据
- 清楚想通过透视表解决什么问题
基础形式
默认计算均值(平均数)
参数:
- 需要做数据透视的数据集
- index :数据透视表中按index分类
查看各个年代分类下的投票人数、时长、评分的均值
pd.pivot_table(df,index = ['年代'])
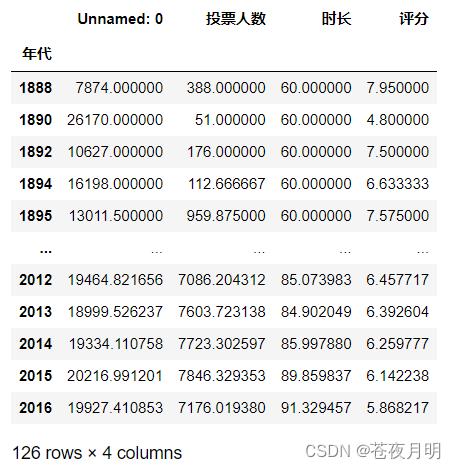
根据年代分类,计算数据(df)里各数值型数据的均值。
设置查看数据数量
这个数据中间用省略号省略了,但我还想看怎么办
用 options.display.参数1 = 参数2 :设置能显示出来的数据的条数
参数:
- 行或列
- 条数
pd.options.display.max_rows = 500 # 显示最大行为500
pd.options.display.max_columns = 30 # 显示最大列为100
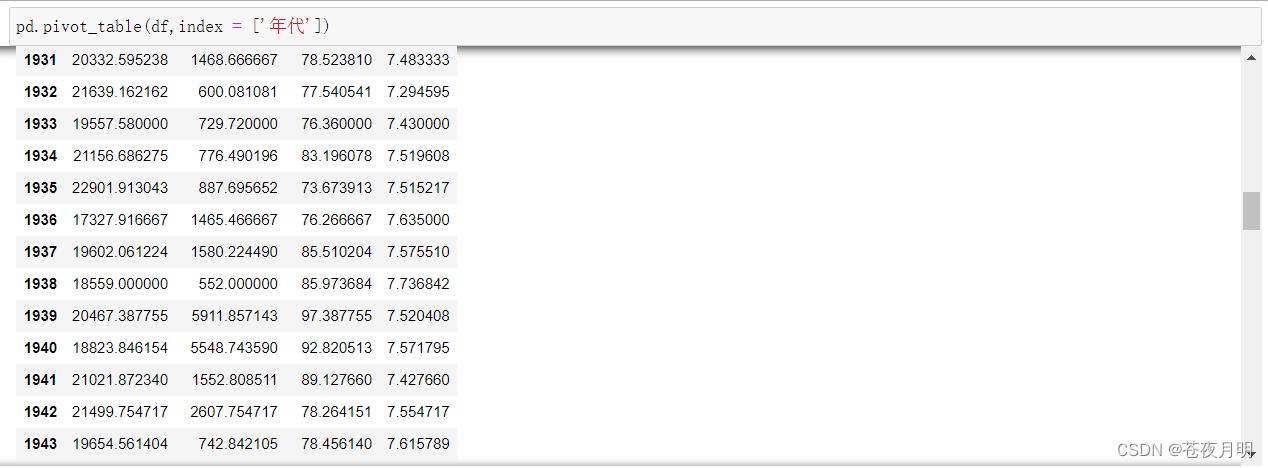
这样就能展示500条数据了,右边有个滑块能滑
多个索引
也可以有多个索引(index 列表里有多个值)。大多数的 pivot_table 参数可以通过列表获取多个值。
查看各个年代、各个产地分类下的投票人数、时长、评分的均值
pd.pivot_table(df,index = ['年代','产地'])
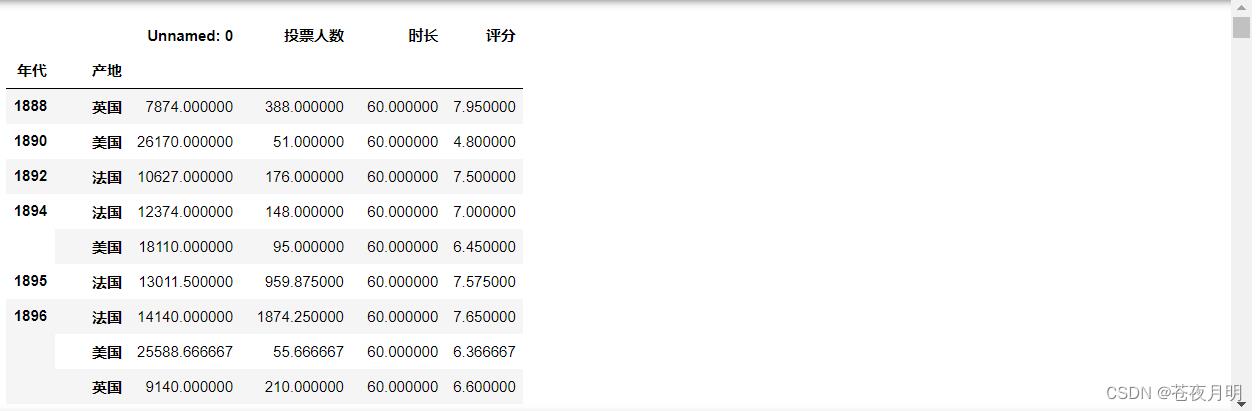
指定需要汇总的数据
在 pivot_table 里加个 values[] 参数
pd.pivot_table(df,index = ['年代','产地'],values = ['评分'])

指定函数 —— 同一值指定不同函数
在 pivot_table 里加个 aggfunc 参数
查看各个年代、各个产地分类下的投票人数的总和
pd.pivot_table(df,index = ['年代','产地'],values = ['投票人数'],aggfunc = np.sum)

通过将投票人数和评分列进行对应分组,对产地实现数据聚合和总结
pd.pivot_table(df,index = ['产地'],values = ['投票人数','评分'],aggfunc = [np.sum,np.mean])
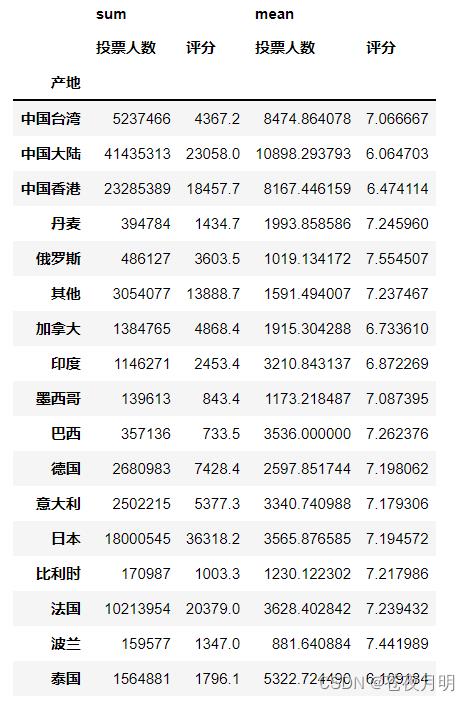
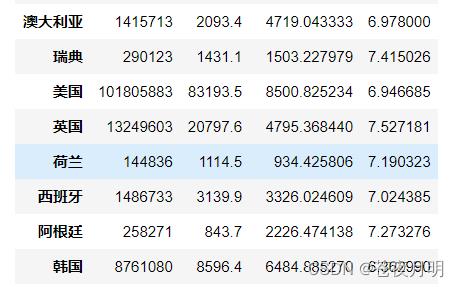
指定函数 —— 不同值指定不同函数
向 aggfunc 传递一个字典。这样做有个副作用,必须将标签做的更加简洁。
pd.pivot_table(df,index = ['产地'],values = ['投票人数','评分'],aggfunc = '投票人数':np.sum,'评分':np.mean,fill_value = 0)
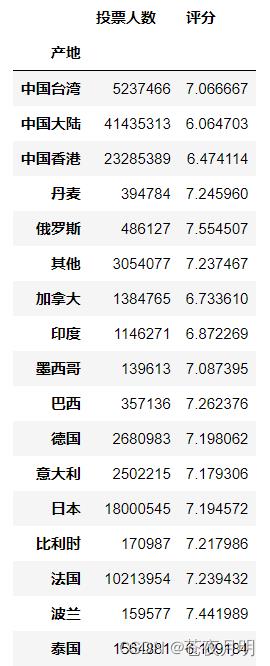
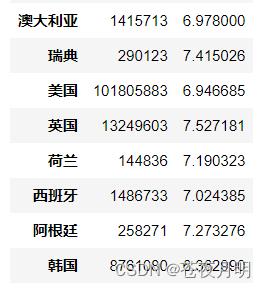
对各个地区的投票人数求和,对评分求均值。
移除非数值
非数值(NaN)难以处理。如果想移除它们,可以使用 fill_value 将其设置为0。
pd.pivot_table(df,index = ['产地'],aggfunc = [np.sum,np.mean],fill_value = 0)
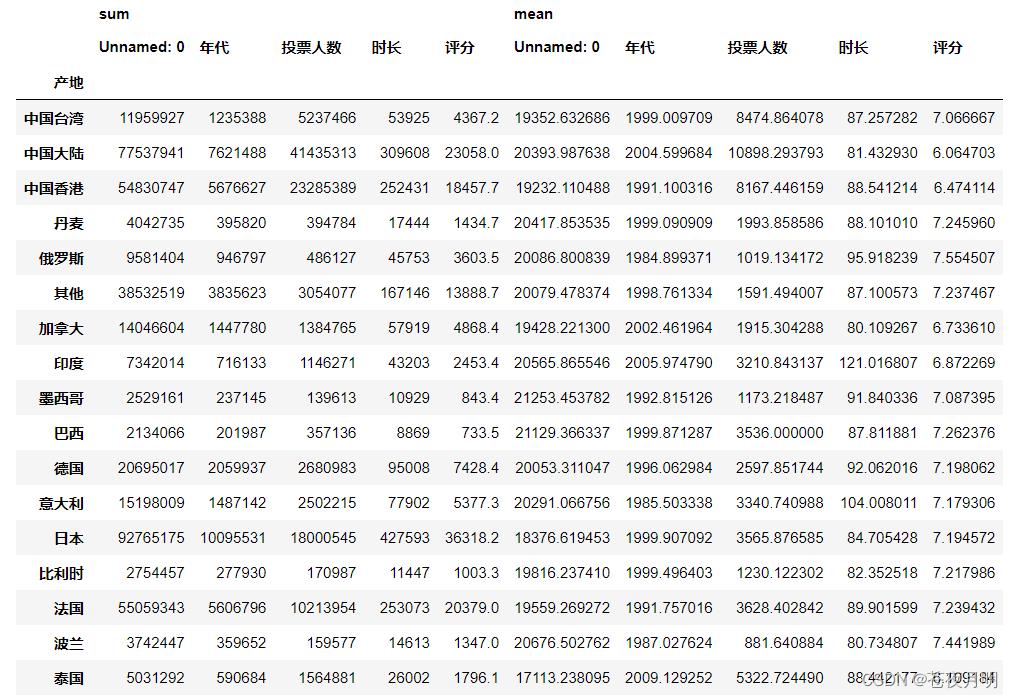
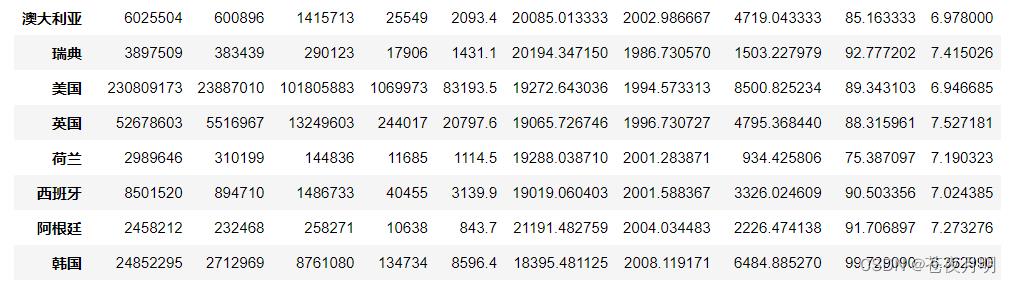
总和数据
加入 margins = True ,可以在下方显示一些总和数据
pd.pivot_table(df,index = ['产地'],aggfunc = [np.sum,np.mean],fill_value = 0,margins = True)

透视表过滤
table = pd.pivot_table(df,index = ['年代'],values = ['投票人数','评分'],aggfunc = '投票人数':np.sum,'评分':np.mean,fill_value = 0)
type(table)

结论:数据透视表是 DataFrame
所以数据透视表和DataFrame的操作都是一样的。
取前五行数据
table.head()
# 或
table[:5]
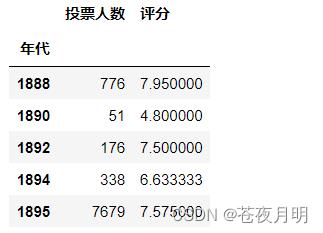
取1994年的数据
table[table.index == 1994]

根据电影评分做降序排列,看前10条数据
table.sort_values(by = '评分',ascending = False).head(10)
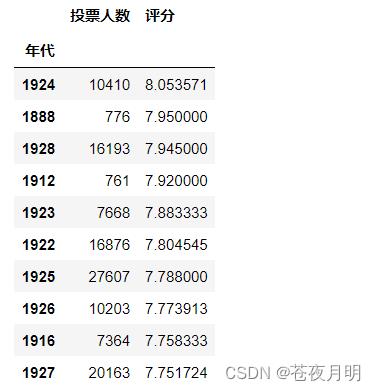
按照多个索引进行汇总
pd.pivot_table(df,index = ['产地','年代'],values = ['投票人数','评分'],aggfunc = '投票人数':np.sum,'评分':np.mean,fill_value = 0)

层次化索引结构,先按产地分类,再按年代分类。
PS:层次化索引结构下篇细讲。
作业
(1)读取上次作业保存的数据
df = pd.read_excel(r'D:\\数据分析\\酒店数据.xlsx')
(2)查看评分数据的格式,并排序
df.评分.dtype

df.sort_values(by = '评分')
(3)对酒店评分排序,评分相同按价格排序
df.sort_values(by = ['评分','价格'])
(4)求价格的均值、方差、最大值、最小值、和
# 均值
df.价格.mean()
# 方差
df.价格.var()
# 最值
df.价格.max()
df.价格.min()
# 和
df.价格.sum()
(5)计算评分,评分人数的相关系数和协方差
# 相关系数
df[['评分','评分人数']].corr()

# 协方差
df[['评分','评分人数']].cov()

(6)查看类型和地区的数量,统计各个类型和地区的数量(类型和地区的种类)
# 查看数量
len(df.类型)
len(df.地区)
# 种类
len(df.类型.unique())
len(df.地区.unique())
(7)用数据透视表,汇总各个地区和类型的评分,价格的均值和标准差
pd.pivot_table(df,index = ['地区','类型'],values = ['评分','价格'],aggfunc = '评分':np.mean,'价格':np.std,fill_value = 0)
以上是关于Python 数据分析 —— Pandas ②的主要内容,如果未能解决你的问题,请参考以下文章