新型冠状病毒数据可视化分析
Posted ZSYL
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了新型冠状病毒数据可视化分析相关的知识,希望对你有一定的参考价值。
新型冠状病毒数据可视化分析
导言

如何成为Python数据分析师?
荀子曰:不积跬步,无以至千里;不积小流,无以成江海。
要成为合格的数据分析师需要多加练习,再牛的数据分析师不练习也会逐渐落伍
孔子曰:工欲善其事,必先利其器。
数据分析工具、可视化工具可以帮助我们快速的进步
主席曰:自己动手,丰衣足食
数据分析看起来很酷,但是学好数据分析不容易。看了老师的代码以后,还是要自己动手演练才能真
正掌握,要不然就是看老师炫技了。
学习目标

学习内容

效果展示

代码与数据分享
Github 地址 https://github.com/huangkai31/ncovanalysis

数据分析常用库 Pandas 简介


数据可视化库 Seaborn 简介

地理可视化库 Folium 简介

1. 建立开发环境
1.1 安装 Folium
# 安装 folium
# ! pip install folium --user
1.2 导入 pandas 等需要的库
# 导入pandas 等
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# 忽略警告信息
import warnings
warnings.filterwarnings('ignore')
import folium
# 设置中文字体 kesci 专用代码
plt.rcParams['font.sans-serif'].insert(0, 'Microsoft YaHei')
print('成功建立开发环境')
成功建立开发环境
2. 使用 pandas 读取并处理数据
# 读取疫情数据,查看基本情况
df = pd.read_csv('./data/COVID-19/DXYArea.csv')
df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 27521 entries, 0 to 27520
Data columns (total 11 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 provinceName 27521 non-null object
1 cityName 27521 non-null object
2 province_confirmedCount 27521 non-null int64
3 province_suspectedCount 27521 non-null int64
4 province_curedCount 27521 non-null int64
5 province_deadCount 27521 non-null int64
6 city_confirmedCount 27521 non-null int64
7 city_suspectedCount 27521 non-null int64
8 city_curedCount 27521 non-null int64
9 city_deadCount 27521 non-null int64
10 updateTime 27521 non-null object
dtypes: int64(8), object(3)
memory usage: 2.3+ MB
df.head()
| provinceName | cityName | province_confirmedCount | province_suspectedCount | province_curedCount | province_deadCount | city_confirmedCount | city_suspectedCount | city_curedCount | city_deadCount | updateTime | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 浙江省 | 温州 | 1075 | 0 | 190 | 0 | 448 | 0 | 71 | 0 | 2020-02-09 15:37:28.105 |
| 1 | 浙江省 | 杭州 | 1075 | 0 | 190 | 0 | 165 | 0 | 41 | 0 | 2020-02-09 15:37:28.105 |
| 2 | 浙江省 | 宁波 | 1075 | 0 | 190 | 0 | 146 | 0 | 13 | 0 | 2020-02-09 15:37:28.105 |
| 3 | 浙江省 | 台州 | 1075 | 0 | 190 | 0 | 138 | 0 | 27 | 0 | 2020-02-09 15:37:28.105 |
| 4 | 浙江省 | 金华 | 1075 | 0 | 190 | 0 | 53 | 0 | 13 | 0 | 2020-02-09 15:37:28.105 |
2.1 按省份统计确诊人数
# 按省份统计确诊人数
province_confirmedCount = df.groupby('provinceName').province_confirmedCount.agg('max')
province_confirmedCount
provinceName
上海市 293
云南省 140
内蒙古自治区 54
北京市 326
吉林省 78
四川省 386
天津市 90
宁夏回族自治区 45
安徽省 779
山东省 435
山西省 115
广东省 1120
广西壮族自治区 195
新疆维吾尔自治区 45
江苏省 468
江西省 740
河北省 206
河南省 1033
浙江省 1075
海南省 128
湖北省 27100
湖南省 838
澳门 2
甘肃省 79
福建省 250
西藏自治区 1
贵州省 96
辽宁省 105
重庆市 446
陕西省 208
青海省 18
黑龙江省 307
Name: province_confirmedCount, dtype: int64
2.2 读取城市坐标数据
# 读取城市坐标数据
coord = pd.read_csv('./data/COVID-19/china_coordinates.csv',
names=['postcode', 'city', 'lon', 'lat'])
coord.head(10)
| postcode | city | lon | lat | |
|---|---|---|---|---|
| 0 | 110000 | 北京市 | 116.395645 | 39.929986 |
| 1 | 110101 | 东城区 | 113.612838 | 37.857865 |
| 2 | 110102 | 西城区 | 113.612838 | 37.857865 |
| 3 | 110105 | 朝阳区 | 116.521695 | 39.958953 |
| 4 | 110106 | 丰台区 | 116.258370 | 39.841938 |
| 5 | 110107 | 石景山区 | 116.184556 | 39.938867 |
| 6 | 110108 | 海淀区 | 116.239678 | 40.033162 |
| 7 | 110109 | 门头沟区 | 115.795795 | 40.000893 |
| 8 | 110111 | 房山区 | 115.862836 | 39.726753 |
| 9 | 110112 | 通州区 | 116.740079 | 39.809815 |
2.3 合并城市坐标数据与省份疫情数据
# 合并城市坐标数据 与 省份疫情数据
coord['confirm'] = coord['city']
coord['confirm'] = coord['confirm'].map(province_confirmedCount.to_dict() )
coord.head()
| postcode | city | lon | lat | confirm | |
|---|---|---|---|---|---|
| 0 | 110000 | 北京市 | 116.395645 | 39.929986 | 326.0 |
| 1 | 110101 | 东城区 | 113.612838 | 37.857865 | NaN |
| 2 | 110102 | 西城区 | 113.612838 | 37.857865 | NaN |
| 3 | 110105 | 朝阳区 | 116.521695 | 39.958953 | NaN |
| 4 | 110106 | 丰台区 | 116.258370 | 39.841938 | NaN |
2.4 清洗数据,去掉空值
# 清洗数据,去掉空值
df_prov = coord.dropna()
df_prov
| postcode | city | lon | lat | confirm | |
|---|---|---|---|---|---|
| 0 | 110000 | 北京市 | 116.395645 | 39.929986 | 326.0 |
| 17 | 120000 | 天津市 | 117.210813 | 39.143930 | 90.0 |
| 33 | 130000 | 河北省 | 115.661434 | 38.613840 | 206.0 |
| 214 | 140000 | 山西省 | 112.515496 | 37.866566 | 115.0 |
| 345 | 150000 | 内蒙古自治区 | 114.415868 | 43.468238 | 54.0 |
| 461 | 210000 | 辽宁省 | 122.753592 | 41.621600 | 105.0 |
| 575 | 220000 | 吉林省 | 126.262876 | 43.678846 | 78.0 |
| 645 | 230000 | 黑龙江省 | 128.047414 | 47.356592 | 307.0 |
| 787 | 310000 | 上海市 | 121.487899 | 31.249162 | 293.0 |
| 804 | 320000 | 江苏省 | 119.368489 | 33.013797 | 468.0 |
| 913 | 330000 | 浙江省 | 119.957202 | 29.159494 | 1075.0 |
| 1015 | 340000 | 安徽省 | 117.216005 | 31.859252 | 779.0 |
| 1136 | 350000 | 福建省 | 117.984943 | 26.050118 | 250.0 |
| 1231 | 360000 | 江西省 | 115.676082 | 27.757258 | 740.0 |
| 1343 | 370000 | 山东省 | 118.527663 | 36.099290 | 435.0 |
| 1496 | 410000 | 河南省 | 113.486804 | 34.157184 | 1033.0 |
| 1673 | 420000 | 湖北省 | 112.410562 | 31.209316 | 27100.0 |
| 1788 | 430000 | 湖南省 | 111.720664 | 27.695864 | 838.0 |
| 1925 | 440000 | 广东省 | 113.394818 | 23.408004 | 1120.0 |
| 2065 | 450000 | 广西壮族自治区 | 108.924274 | 23.552255 | 195.0 |
| 2191 | 460000 | 海南省 | 109.733755 | 19.180501 | 128.0 |
| 2192 | 460000 | 海南省 | 109.733755 | 19.180501 | 128.0 |
| 2219 | 500000 | 重庆市 | 106.530635 | 29.544606 | 446.0 |
| 2220 | 500000 | 重庆市 | 106.530635 | 29.544606 | 446.0 |
| 2258 | 510000 | 四川省 | 102.899160 | 30.367481 | 386.0 |
| 2458 | 520000 | 贵州省 | 106.734996 | 26.902826 | 96.0 |
| 2555 | 530000 | 云南省 | 101.592952 | 24.864213 | 140.0 |
| 2700 | 540000 | 西藏自治区 | 89.137982 | 31.367315 | 1.0 |
| 2781 | 610000 | 陕西省 | 109.503789 | 35.860026 | 208.0 |
| 2898 | 620000 | 甘肃省 | 102.457625 | 38.103267 | 79.0 |
| 2999 | 630000 | 青海省 | 96.202544 | 35.499761 | 18.0 |
| 3051 | 640000 | 宁夏回族自治区 | 106.155481 | 37.321323 | 45.0 |
| 3079 | 650000 | 新疆维吾尔自治区 | 85.614899 | 42.127001 | 45.0 |
2.5 步骤总结
- 安装 Folium : pip install folium --user
- 导入 pandas 等需要的库
- 使用 pandas 读取并处理数据 :
read_csv- 分组聚合计算:
groupby, agg to_dict , map , dropna
3. Folium 进行基于地理的数据可视化展示
3.1 读取json地理信息文件
# 读取json文件
import json
with open(r'./data/COVID-19/100000_full.json', encoding='utf-8') as f:
json_data = json.load(f)
3.2 使用 folium 绘制中国轮廓图
3.3 使用 folium 根据疫情数据绘制图表
# 绘制地图 : location 地图中心位置坐标(纬度lat, 经度lon), zoom_start 地图放大系数
map = folium.Map(location=[39.929986, 116.395645], zoom_start=4)
# 取对数解决色彩条不均衡问题
df_prov['logconfirm'] = np.log(df_prov['confirm'])
folium.Choropleth(
name='疫情热图', # 名称
geo_data=json_data, # 数据文件
data=df_prov.set_index(df_prov.city), # 数据集
columns=['city', 'logconfirm'], # 列名称
key_on='feature.properties.name', # 匹配geo_data 中的属性值
fill_color='Reds', # 色彩配置
# bins = [0, 100, 500, 1000, 10000, 30000] # 数据区间范围
).add_to(map)
# 将确诊人数增加到地图上
for d in df_prov.itertuples():
folium.Marker(
location=[d.lat, d.lon],
icon=folium.Icon(color='red') if d.confirm > 1000 else
(folium.Icon(color='orange') if d.confirm >
100 else folium.Icon(color='blue')),
tooltip=" {} 确诊 {} 例".format(d.city, int(d.confirm))
).add_to(map)
map

3.4 步骤总结
- 使用 folium 绘制中国轮廓图
Choropleth: key_on参数- 取对数解决数据分布问题
- 使用 folium 根据疫情数据绘制图表
- Marker
- itertuples
4. Pandas+Seaborn 进行时序分析与可视化展示
4.1 转换为时序数据
# 转换为时序数据
df['updateTime'] = pd.to_datetime(df['updateTime'])
df.index = pd.DatetimeIndex( df['updateTime'])
df.info()
<class 'pandas.core.frame.DataFrame'>
DatetimeIndex: 27521 entries, 2020-02-09 15:37:28.105000 to 2020-01-24 03:50:31.353000
Data columns (total 11 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 provinceName 27521 non-null object
1 cityName 27521 non-null object
2 province_confirmedCount 27521 non-null int64
3 province_suspectedCount 27521 non-null int64
4 province_curedCount 27521 non-null int64
5 province_deadCount 27521 non-null int64
6 city_confirmedCount 27521 non-null int64
7 city_suspectedCount 27521 non-null int64
8 city_curedCount 27521 non-null int64
9 city_deadCount 27521 non-null int64
10 updateTime 27521 non-null datetime64[ns]
dtypes: datetime64[ns](1), int64(8), object(2)
memory usage: 2.5+ MB
4.2 取出各个省份每天的数据
# 取出各个省份每天的数据
df_provconfirm = df[ ['provinceName', 'province_confirmedCount'] ].groupby([df.index.date, 'provinceName']).first()
df_provconfirm.head()
| province_confirmedCount | ||
|---|---|---|
| provinceName | ||
| 2020-01-24 | 云南省 | 5 |
| 内蒙古自治区 | 2 | |
| 北京市 | 36 | |
| 吉林省 | 3 | |
| 四川省 | 15 |
4.3 计算并绘制全国确诊病例总数线形图
# 对数据进行按天汇总 sum
# unstack 讲省份由索引变为列
# fillna 填充空值
# sum 按行(axis=1)求和 (汇总)
# plot.line 绘制线形图
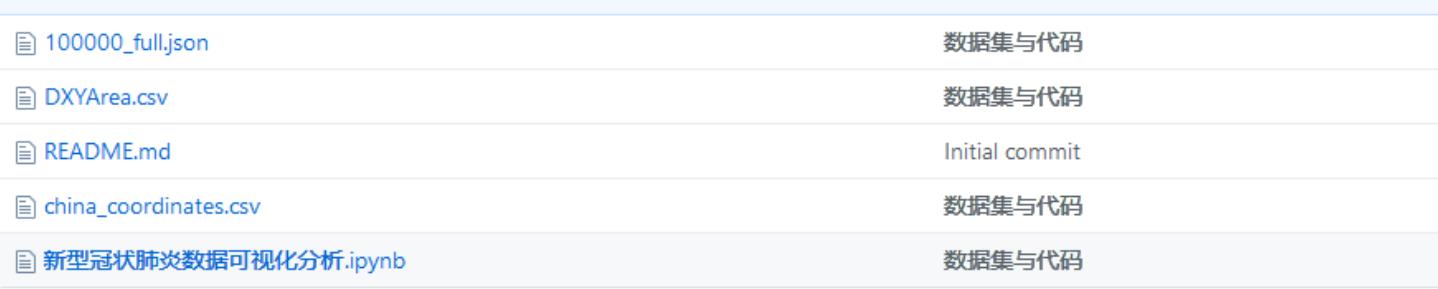
df_provconfirm.unstack().fillna(value=0).sum(axis=1).plot.line(figsize=(20,8), marker='o')
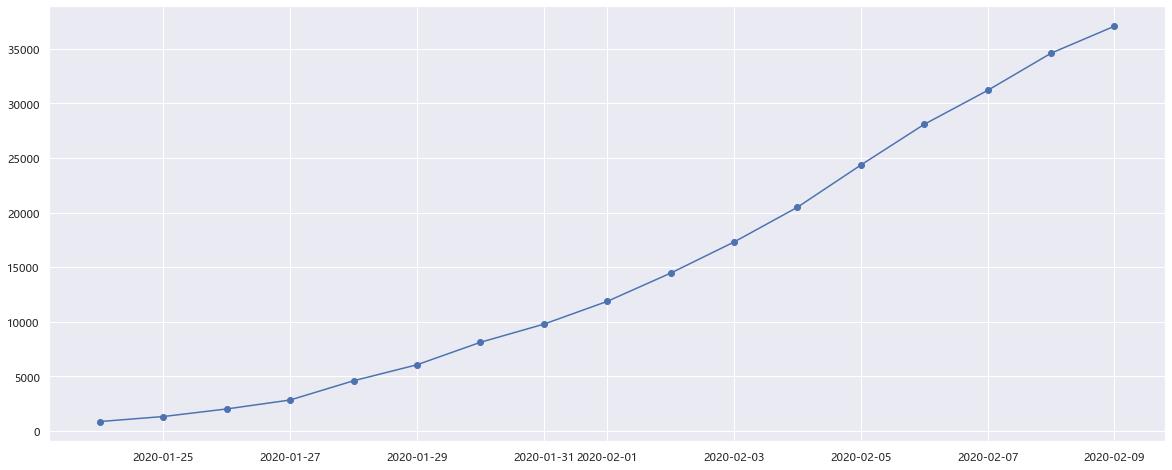
# 使用 seaborn
sns.set()
plt.figure( figsize=(20, 8))
sns.lineplot(data=df_provconfirm.unstack().fillna(value=0).sum(axis=1), marker = 'o' )
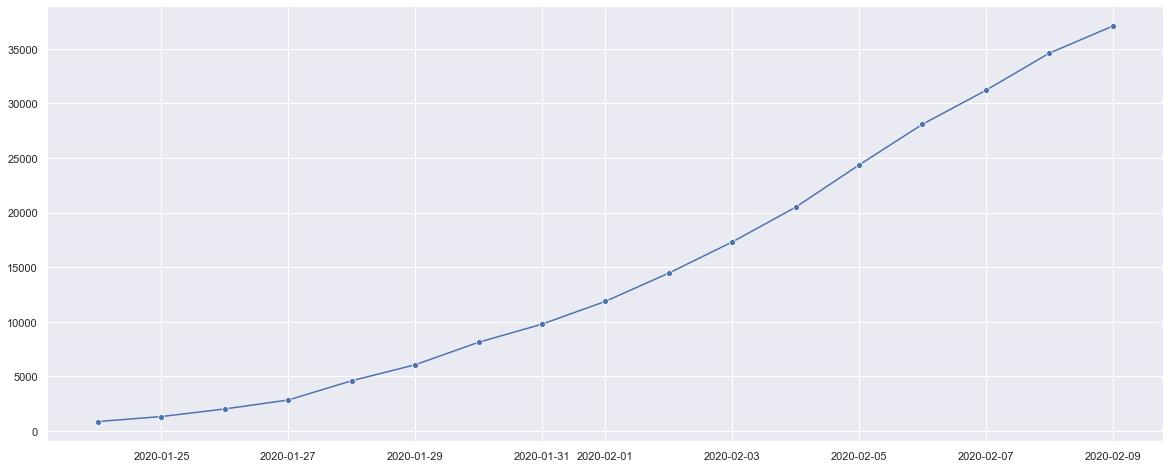
4.4 计算并绘制全国确诊病例增长线形图
df_totalconfirm = df_provconfirm.unstack().fillna(value=0).sum(axis=1)
df_totalconfirm.head()
2020-01-24 866.0
2020-01-25 1324.0
2020-01-26 2019.0
2020-01-27 2838.0
2020-01-28 4601.0
dtype: float64
pd.DataFrame( [df_totalconfirm, df_totalconfirm.diff()]).T.fillna(value=0)\\
.plot.line(figsize=(20,8), marker='o', subplots=True)
4.5 绘制湖北省确诊病例与增长趋势线形图
湖北省数据
# 湖北省数据
df_hubei = df_provconfirm.unstack()[ [('province_confirmedCount', '湖北省')] ].sum(axis=1)
pd.DataFrame( [df_hubei, df_hubei.diff()]).T.fillna(value=0)\\
.plot.line(figsize=(20,8), marker='o', subplots=True)
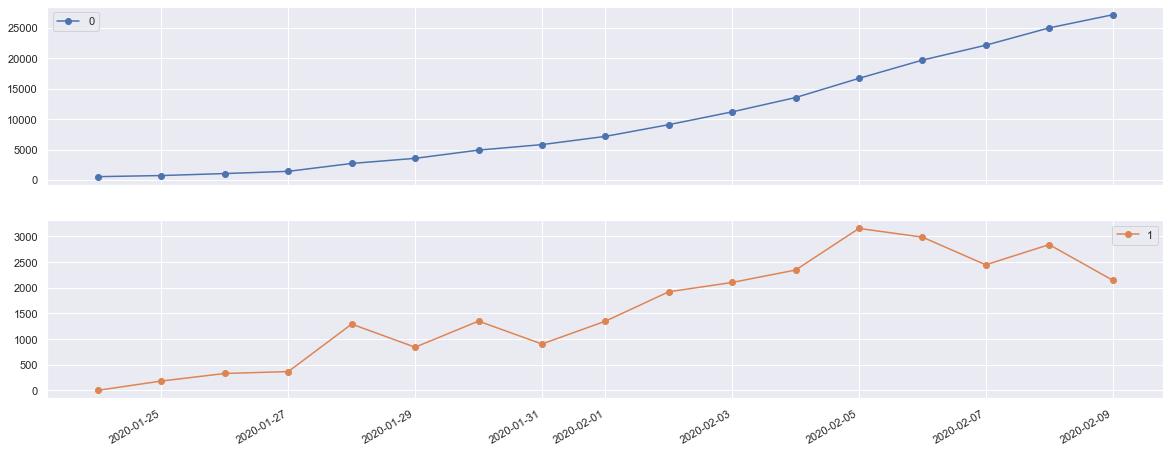
4.6 绘制非湖北省确诊病例与增长趋势线形图
# 非湖北省数据
df_nhubei = df_provconfirm.unstack().drop(('province_confirmedCount', '湖北省'), axis=1 ).fillna(value=0).sum(axis=1)
pd.DataFrame( [df_nhubei, df_nhubei.diff()]).T.fillna(value=0)\\
.plot.line(figsize=(20,8), marker='o', subplots=True)
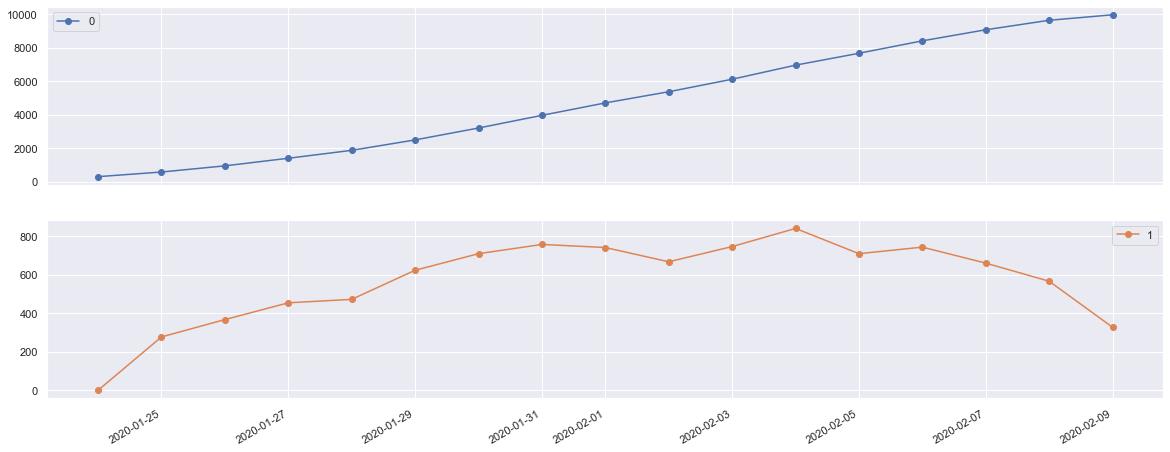
4.7 步骤总结
- 计算并绘制全国确诊病例总数线形图
- 计算并绘制全国确诊病例增长线形图
- 分别绘制湖北省 与 非湖北省确诊病例与增长趋势线形图
groupby, first, sumunstack, fillna, dropTplot
5. Seaborn 绘制热力图展示疫情热点区域
5.1 扩散指数
扩散指数 = 当天新增确诊病例数 相对于前一天的现有病例数的增长率
# 扩散指数 = 当天新增确诊病例数 相对于前一天的现有病例数的增长率
# 城市名称
df['city'] = df['provinceName'] + df['cityName']
# 按日期分组计算每个城市的确诊数量
df_cityconfirm = df[ ['city', 'city_confirmedCount']].groupby([df.index.date, 'city']).first().unstack().fillna(value=0)
# 翻转
df_cityconfirm = df_cityconfirm.T
df_cityconfirm.head()
| 2020-01-24 | 2020-01-25 | 2020-01-26 | 2020-01-27 | 2020-01-28 | 2020-01-29 | 2020-01-30 | 2020-01-31 | 2020-02-01 | 2020-02-02 | 2020-02-03 | 2020-02-04 | 2020-02-05 | 2020-02-06 | 2020-02-07 | 2020-02-08 | 2020-02-09 | ||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| city | ||||||||||||||||||
| city_confirmedCount | 上海市嘉定 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 2.0 | 2.0 | 2.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 上海市嘉定区 | 0.0 | 0.0 | 0.0 | 1.0 | 1.0 | 0.0 | 0.0 | 2.0 | 2.0 | 2.0 | 2.0 | 3.0 | 4.0 | 4.0 | 5.0 | 6.0 | 7.0 | |
| 上海市外地来沪人员 | 0.0 | 0.0 | 0.0 | 23.0 | 33.0 | 47.0 | 51.0 | 62.0 | 73.0 | 74.0 | 79.0 | 81.0 | 86.0 | 89.0 | 93.0 | 96.0 | 97.0 | |
| 上海市奉贤 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 5.0 | 5.0 | 5.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | |
| 上海市奉贤区 | 0.0 | 0.0 | 0.0 | 1.0 | 1.0 | 0.0 | 0.0 | 5.0 | 5.0 | 5.0 | 5.0 | 6.0 | 7.0 | 8.0 | 9.0 | 9.0 | 9.0 |
5.2 计算差额
# 计算差额 按行计算差额 axis=1
df_cityconfirm.diff(axis=1).head()
| 2020-01-24 | 2020-01-25 | 2020-01-26 | 2020-01-27 | 2020-01-28 | 2020-01-29 | 2020-01-30 | 2020-01-31 | 2020-02-01 | 2020-02-02 | 2020-02-03 | 2020-02-04 | 2020-02-05 | 2020-02-06 | 2020-02-07 | 2020-02-08 | 2020-02-09 | ||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| city | ||||||||||||||||||
| city_confirmedCount | 上海市嘉定 | NaN | 0.0 | 0.0 | 0.0 | 1.0 | 1.0 | 0.0 | 0.0 | -2.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 上海市嘉定区 | NaN | 0.0 | 0.0 | 1.0 | 0.0 | -1.0 | 0.0 | 2.0 | 0.0 | 0.0 | 0.0 | 1.0 | 1.0 | 0.0 | 1.0 | 1.0 | 1.0 | |
| 上海市外地来沪人员 | NaN | 0.0 | 0.0 | 23.0 | 10.0 | 14.0 | 4.0 | 11.0 | 11.0 | 1.0 | 5.0 | 2.0 | 5.0 | 3.0 | 4.0 | 3.0 | 1.0 | |
| 上海市奉贤 | NaN | 0.0 | 0.0 | 0.0 | 1.0 | 4.0 | 0.0 | 0.0 | -5.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | |
| 上海市奉贤区 | NaN | 0.0 | 0.0 | 1.0 | 0.0 | -1.0 | 0.0 | 5.0 | 0.0 | 0.0 | 0.0 | 1.0 | 1.0 | 1.0 | 1.0 | 0.0 | 0.0 |
5.3 取出第二行数据 单独计算扩散指数
# 取出第二行数据 单独计算扩散指数
v = df_cityconfirm.values[2]
v_diff = df_cityconfirm.diff(axis=1).values[2]
print(10/23) # 手工计算
print(14/33)
0.43478260869565216
0.42424242424242425
# 处理 v_diff, 去掉第一个数值, 在最后增加一个数值(0)
v_diff = v_diff[1:]
v_diff = np.append(v_diff, 0)
v_diff
array([ 0., 0., 23., 10., 14., 4., 11., 11., 1., 5., 2., 5., 3., 4., 3., 1., 0.])
# 计算扩散指数
v_diff / v
array([ nan, nan, inf, 0.43478261, 0.42424242,
0.08510638, 0.21568627, 0.17741935, 0.01369863, 0.06756757,
0.02531646, 0.0617284 , 0.03488372, 0.04494382, 0.03225806,
0.01041667, 0. ])
5.4 计算扩散指数
# 计算扩散指数
df_tmp = df_cityconfirm.diff(axis=1)
df_kuosan = df_cityconfirm.copy()
index = 0
for v in df_cityconfirm.values:
v_diff = df_tmp.values[index]
df_kuosan.values[index] = np.append(v_diff, 0)[1:]/v
index += 1
5.5 数据处理-清除空值
# 进一步处理,清除空值
df_kuosan = df_kuosan.replace([np.inf, -np.inf], np.nan).fillna(value=0)
df_kuosan.head()
| 2020-01-24 | 2020-01-25 | 2020-01-26 | 2020-01-27 | 2020-01-28 | 2020-01-29 | 2020-01-30 | 2020-01-31 | 2020-02-01 | 2020-02-02 | 2020-02-03 | 2020-02-04 | 2020-02-05 | 2020-02-06 | 2020-02-07 | 2020-02-08 | 2020-02-09 | ||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| city | ||||||||||||||||||
| city_confirmedCount | 上海市嘉定 | 0.0 | 0.0 | 0.0 | 0.000000 | 1.000000 | 0.000000 | 0.000000 | -1.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.0 |
| 上海市嘉定区 | 0.0 | 0.0 | 0.0 | 0.000000 | -1.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.500000 | 0.333333 | 0.000000 | 0.250000 | 0.200000 | 0.166667 | 0.0 | |
| 上海市外地来沪人员 | 0.0 | 0.0 | 0.0 | 0.434783 | 0.424242 | 0.085106 | 0.215686 | 0.177419 | 0.013699 | 0.067568 | 0.025316 | 0.061728 | 0.034884 | 0.044944 | 0.032258 | 0.010417 | 0.0 | |
| 上海市奉贤 | 0.0 | 0.0 | 0.0 | 0.000000 | 4.000000 | 0.000000 | 0.000000 | -1.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.0 | |
| 上海市奉贤区 | 0.0 | 0.0 | 0.0 | 0.000000 | -1.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.200000 | 0.166667 | 0.142857 | 0.125000 | 0.000000 | 0.000000 | 0.0 |
5.6 处理索引列
# 处理索引列以上是关于新型冠状病毒数据可视化分析的主要内容,如果未能解决你的问题,请参考以下文章