多智能体强化学习:多智能体系统
Posted UQI-LIUWJ
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了多智能体强化学习:多智能体系统相关的知识,希望对你有一定的参考价值。
1 多智能体系统
- 多智能体系统 (Multi-Agent System,缩写MAS) 中包含 m 个智能体,智能体共享环境,智能体之间会相互影响。
- 一个智能体的动作会改变环境状态,从而影响其余所有智能体。
1.1 多智能体系统 VS 并行强化学习
- 并行强化学习
- m 个节点并行计算, 每个节点有独立的环境,每个环境中有一个智能体。
- 智能体之间完全独立,不会相互影响。
- 可以看成 m 个单智能体系统 (Single-Agent System , SAS) 的并集
- 多智能体系统
- 只有一个环境,环境中有 m 个相互影响的智能体
- 环境中有 m 个机器人,这属于 MAS 的设定。
- 假如把每个机器人隔绝在一个密闭的房间中,机器人之间不会通信, 那么 MAS 就变成了多个 SAS 的并集。——>此时就是并行强化学习了
1.2 多智能体强化学习 (Multi-Agent Reinforcement Learning, MARL)
让多个智能体处于相同的环境中,每个智能体独立与环境交互,利用环境反馈的奖励改进自己的策略,以获得更高的回报。 在多智能体系统中,一个智能体的策略不能简 单依赖于自身的观测、动作,还需要考虑到其他智能体的观测、动作。1.3 多智能体强化学习的设定
1.3.1 完全合作关系(Fully Cooperative)
智能体的利益一致,获得的奖励相同,有共同的目标。
假设一共有 m 个智能体,它们在 t 时刻获得的奖励分别是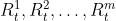 ,在完全合作关系中,他们的奖励是相同的
,在完全合作关系中,他们的奖励是相同的

1.3.2 完全竞争关系 (Fully Competitive)
一方的收益是另一方的损失。 在完全竞争的设定下, 双方的奖励是负相关的:对于所有的 t,有
如果是零和博弈,双方的获得的 奖励总和等于 0 :

1.3.3 合作竞争的混合 (Mixed Cooperative & Competitive)
智能体分成多个群组;组内的智能体是合作关系,它们的奖励相同;组间是竞争关系,两组的奖励是负相关的。1.3.4 利己主义(Self-Interested)
- 系统内有多个智能体;一个智能体的动作会改变环境状态, 从而让别的智能体受益或者受损。利己主义的意思是智能体只想最大化自身的累计奖励, 而不在乎他人收益或者受损。
- 智能体之间有潜在而又未知的竞争与合作关系:一个智能体的决策可 能会帮助其他智能体获利,也可能导致其他智能体受损。
1.3.5 总述四种设定

- 不同设定下学出的策略会有所不同。
- 在合作的设定下,每个智能体的决策要考虑到队友的策略,要与队友做到尽量好的配合,而不是个人英雄主义;这个道理在足球、电子竞技中是显然的。
- 在竞争的设定下,智能体要考虑到对手的策略,相应调整自身策略; 比如在象棋游戏中,如果你很熟悉对手的套路,并相应调整自己的策略,那么你的胜算 会更大。
- 在利己主义的设定下,一个智能体的决策无需考虑其他智能体的利益,尽管一 个智能体的动作可能会在客观上帮助或者妨害其他智能体。
2 多智能体系统的基本概念
2.1 基本符号
| 符号 | 内容 |
| S | 状态 (State) 随机变量 |
| s | 状态的观测值 |
| o |
单个智能体未必能观测到完整状态。
如果单个智能体的观测只是部分状态,我们就用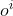 表示第 i
号智能体的不完全观测。 表示第 i
号智能体的不完全观测。
|
| A&a |
每个智能体都会做出
动作
(Action)
。把第
i 号智能体的动作随机变量记作
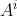 ,把动作的实际观测值记作
,把动作的实际观测值记作
 如果不加上标
i
,则意味着所有智能体的动作的连接
如果不加上标
i
,则意味着所有智能体的动作的连接

|
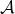 |
把第
i
号智能体的动作空间
(Action Space)
记作  ,它包含该智能体所有可能的动作。
,它包含该智能体所有可能的动作。
整 个系统的动作空间是  两个智能体的动作空间
可能相同,也可能不同。
两个智能体的动作空间
可能相同,也可能不同。
|
| p | 状态转移函数, 下一个时刻的状态 取决于当前时刻状态St,以及所有m个智能体的动作 取决于当前时刻状态St,以及所有m个智能体的动作 |
| R | 奖励 (Reward) 是环境反馈给智能体的数值。把第 i 号智能体的奖励随机变量记作
t时刻的奖励 |
| U | 折扣回报,定义和单智能体类似
|
 ,
,
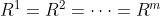

 由状态St和所有智能体的动作
由状态St和所有智能体的动作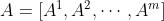 共同决定
共同决定
2.2 策略网络
-
对于
离散控制问题,把第 i 号智能体的策略网络记作:
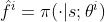
-
的维度等于动作空间的大小

-
- 对于连续控制问题,把第 i 号智能体的策略网络记作:

- 有了这个策略网络,第 i 号智能体就可以基于当前状态 s ,直接计算出需要执行的动作
- 在上面的两种策略网络中,每个智能体的策略网络有各自的参数

- 在有些情况下,策略网络的角色是可以互换的,比如同一型号无人机的功能是相同的,那 么它们的策略网络是相同的
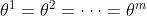
-
在很多应用中,策略网络不能互换。比如在足球机器人的应用中,球员有的是负责进攻的前锋,有的是负责防守的后卫, 还有一个守门员。它们的策略网络不能互换,所以参数各不相同。
- 在有些情况下,策略网络的角色是可以互换的,比如同一型号无人机的功能是相同的,那 么它们的策略网络是相同的
2.3 动作价值函数
智能体i在时刻t的(折扣)回报 依赖于未来所有的状态
依赖于未来所有的状态 和所有智能体未来的动作
和所有智能体未来的动作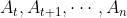
——>t时刻的状态st,t时刻所有智能体的动作
——>这里的E是关于一下这些随即变量求的:
其中动作Ak的概率质量函数为 所有 m 个智能体的策略的乘积:
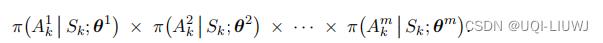
如果系统里有 m 个智能体,那么就有 m 个动作价值函数:
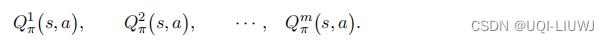
其中第i个智能体的动作价值
并非仅仅依赖于自己当前的动作
与策略
,还依赖于其余智能体的动作和策略


2.4 状态价值函数

其中:

很显然第i号智能体的状态价值依赖于所有智能体的策略:
2.5 多智能体强化学习的困难之处
以上是关于多智能体强化学习:多智能体系统的主要内容,如果未能解决你的问题,请参考以下文章