可搜索加密简要介绍与相关概念
Posted 风间九青
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了可搜索加密简要介绍与相关概念相关的知识,希望对你有一定的参考价值。
本篇博客整理了一些可搜索加密的相关概念。最近一段时间看的论文主要集中在对称可搜索加密的方向,所以涉及这方面的概念会多一些。以后也会陆续更新。继续加油看论文!
1. 可搜索加密
可搜索加密
Searchable Encryption, SE
当数据存储在一个不可信的服务器时,为了让服务器不能够了解到数据内容,需要对数据加密后再存储。为了实现在加密后的数据上进行关键词检索,提出了可搜索加密的思想。
可搜索加密最初的提出者Song等人[1]设想了这样一个场景:假设Alice有一些文档,存储在一个不可信服务器Bob上。因为Bob是不可信的,Alice希望只在Bob上存储加密过的文档。每个文档都可以被分成单词,每个单词可以是等长或者不等长的。因为Alice和服务器Bob之间通信带宽可能比较低,她在对文档进行检索时,希望只获得包含某个特定关键字w的一部分文档。为了达到这个目标,设计了这样一个方案,Bob可以在密文上进行某种计算,并且只返回可能包含关键字w的文档,而无法获得除此之外的其他信息。关键在于,未获得数据拥有者Alice授权的其他用户不能够知道任何关于文件明文的知识。
对称可搜索加密
SE分为两种:对称可搜索加密(Symmetric Searchable Encryption, SSE)和非对称可搜索加密(Asymmetric Searchable Encryption, ASE),后者也称公钥可搜索加密(Public Key Encryption With Searching, PEKS)。两者的区别在于前者使用对称加密算法,加密和解密的密钥一样;后者使用非对称加密算法。
SSE相比于ASE,优势在于计算开销小、算法简单、速度快。通常使用在单用户模型中,检索方和数据拥有者是同一个。
动态可搜索加密
Dynamic Searchable Encryption, DSE
指用户可以动态地对存储在服务器上的密文文档进行更新(update)。更新操作包括两种:添加(add)和删除(delete)。不过需要注意的是,很多方案在实现删除时,并不是真的把要删除的文档从服务器移除了,而只是把删除的文档添加到另一个实例(instance)里,这个实例称作删除实例。
陷门
Trapdoor
在使用了可搜索加密技术的情况下,用户在向服务器提交搜索申请时如果直接提交关键字的明文,就违背了这项技术的初衷:不泄露任何关于明文的消息。因此,SE中并不是直接把关键字提交给服务器,而是对关键字进行“加密”后再提交上去。加密后的关键字是称作陷门,这种在查询关键字时提交的陷门也叫做检索陷门
在动态可搜索加密加密中,还有另一种陷门:更新陷门,是在进行更新操作时提交的陷门。包含了更新操作(add / del,分别指插入和删除),关键字w和文档ind。
穿刺加密
puncturable encryption, PE
是前向安全公钥加密(forward secure public key encryption)的一种变体,可以支持对单个消息的细粒度撤销。核心思想在于使用标记(tag)。消息用一组tag加密,穿刺算法使用某个tag更新密钥,使得新的密钥能够解密所有不包含该tag的密文。
形式化的定义如下:
一个在消息空间M和标记空间T上的穿刺公钥加密方案是一个算法四元组(KeyGen, Encrypt, Puncture, Decrypt),每个算法定义如下:
-
KeyGen(1^λ): 输入安全参数λ,输出公钥PK和最初的密钥
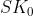 。
。 -
Encrypt(PK, m, t): 输入公钥PK、消息m∈M和标记t∈T,输出对应的密文CT。
-
Puncture(
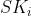 , t): 输入密钥和标记t,输出一个新的密钥
, t): 输入密钥和标记t,输出一个新的密钥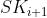 ,它能够解密所有密钥能够解密的,除了那些使用标记t加密的密文。
,它能够解密所有密钥能够解密的,除了那些使用标记t加密的密文。 -
Decrypt(
, CT, t): 输入密钥,密文CT和标记t,解密成功输出明文m,否则输出⊥。
正确性:如果使用没有被标记t穿刺的密钥SK去解密被t加密的消息m,则一定能够输出明文m。
安全性
前向安全
forward privacy / forward security
通俗来说,前向安全是指更新操作不会泄露之前的查询的信息,也就是说,服务器不知道更新的关键字是否在之前被查询过。
形式化的定义来自论文[2],如下图所示:

这个定义意味着,更新时泄露的信息只能严格包含操作类型、文件标识符和文件大小,而没有任何其他的信息。
与之相对的是后向安全。
后向安全
backward privacy / backward security
简单来说,是指如果一个关键字/文档对(w, ind)已经被删除,那么之后的在关键字w上进行的搜索都不能包含这个ind。形式化的定义如下图:

针对后向安全的SE方案很少,大部分方案都专注于前向安全,因为目前来说还没有发现不满足后向安全的方案有什么安全隐患,但不满足前向安全的隐患则很大。
文件注入攻击
file-injection attack
张等人提出的概念[3],是一个相当有效的攻击方式。核心思想在于,连接(link)用户过去提交的搜索令牌和新提交的文件,以此恢复出用户提交的关键字,推测文档内容。具有前向安全也就意味着能够抵抗文件注入攻击。
统计推理攻击
statistical inference attack
Islam等人提出的概念,意味着敌手能够通过统计用户提交的搜索和访问操作,以及其他一些信息——比如关键字搜索返回的文件大小,与公开或已知的数据库进行比对,从中恢复出一些关键信息。这种攻击对方案的安全性要求更高。
一般来说,抵抗统计推理攻击常用的技术是隐藏返回结果(result pattern hiding),这有两种常用的方法:填充(fill)和分区(partition)。填充是指对搜索结果进行填充,让结果看起来一样长;分区则是把文档按照关键字分区,每次返回对应分区的结果。
2. 不经意随机访问机
oblivious read access machine, ORAM
ORAM被提出的目的是为了隐藏用户的访问模式,混淆真实访问和随机访问,从而保护数据安全。它通过将用户的一个访问转换成多个访问,模糊用户具体的访问模式,从而很好地保护访问数据块的位置、数据块请求的顺序、对相同数据块的访问频率、具体的访问方式。用在SE中,意味着可以确保两次访问操作不会产生关联,因此达到了前向安全。ORAM并不是本文的重点,之后如果有使用ORAM的方案,我会再进行详细介绍。可以参考文章ORAM简介_c630843901的博客-CSDN博客和不经意随机访问机研究综述 (jos.org.cn)。
3. 同态加密
Homomorphic Encryption, HE
其实以下几个概念都跟可搜索加密关联不太大,不过有一些相似性,所以也写在这里。
同态加密是允许服务器在密文上进行计算的技术。用户把加密的输入提交到服务器,服务器直接在密文上进行计算后把结果返回给用户,用户解密后可以得到正确答案。
4. 不经意传输
Oblivious Transfer, OT
发送者每次发送两个或多个信息,接收者从中选择一个进行接收。保证发送者无法知道接收者获得了什么消息。
5. 匿踪查询
Private Information Retrieval, PIR
查询方在不泄露查询对象关键词的情况下提交查询,服务器提供与关键词匹配的查询结果,但无法知道结果具体对应哪个查询对象。使用不对称加密、不经意传输等技术。
6. 默克尔树
Merkle Tree or Hash Tree
也称为哈希树,是一种二叉树,这棵树的每个父节点的值都是两个子节点合并之后的哈希,而叶节点的值是原始数据或其哈希值。可以用于快速验证数据。
参考文献
[1] Practical Techniques for Searches on Encrypted Data, D X Song. et al. IEEE Symposium on Security and Privacy, 2000
[2] Forward and Backward Private Searchable Encryption from Constrained Cryptographic Primitives, Bost R. et al. CCS 2017
[3] All Your Queries Are Belong to Us: The Power of File-Injection Attacks on Searchable Encryption, Y. Zhang et al., USENIX Security 2016
关联分析简要介绍
关联分析
概念:
关联分析该方法是以长期重组后保留下来的基因(位点)间连锁不平衡(LD)为基础,在获得群体表型数据和基因型数据之后,采用统计方法检测遗传多态性和性状可遗传变异之间的关联,目标是寻找性状变异的基因组功能型变异(基因位点和标记位点)
关联分析是基于无亲缘关系的病例组和对照组在某一个遗传位点上会出现不同频率而设计的。
关联分析的基础----连锁不平衡
某一群体,不同基因座的的两个基因同时遗传的频率高于预期随机频率的现象。
当位于某一座位上的某个特定基因与另一个座位上的某个基因同时遗传的概率大于群体中因随机分布两个等位基因同时出现的的概率时,就称这两个基因座处于连锁不平衡状态。
例如两个相邻的基因A B, 他们各自的等位基因为a b. 假设A B相互独立遗传,则后代群体中观察得到的单倍体基因型 AB 中出现的P(AB)的概率为 P(A) * P(B).
实际观察得到群体中单倍体基因型 AB 同时出现的概率为P(AB)。 若这两对等位基因是非随机结合的,则P(AB)≠P(A)*P(B)。计算这种不平衡程度的方法为: D = P(AB)- P(A) * P(B).
连锁不平衡分析在连锁不平衡程度的评估、复杂疾病精细定位以及研究人类的历史和迁移中得到了越来越广泛的应用。连锁不平衡又称等位基因关联(allelic association),其原理其实很简单。
假定两个紧密连锁的位点1,2,各有两个等位型(A,a;B,b),那么在同一条染色体上将有四种可能的组合方式:A—B,A—b,a—B,和a—b。
假定等位型A的频率为Pa,B的频率为Pb,那么如果不存在连锁不平衡(如组成单倍型的等位型间相互独立,随机组合)单倍型A—B的频率就应为PaPb。而如果A与B是相关联的,单倍型A—B的频率则应为PaPb+D,D是表示两位点间LD程度的值
疾病与标记相关联的有两种情况:
一,治病基因与标记有很强的连锁不平衡关系。
二,遗传标记本身与遗传标记有关

上位性
一对基因的显性基因的表观受另一对非等位基因的作用,这种非等位基因的抑制或遮掩作用,叫上位性效应。起抑制作用的基因叫上位基因,被抑制的基因叫下位基因
以上是关于可搜索加密简要介绍与相关概念的主要内容,如果未能解决你的问题,请参考以下文章