通过可视化运维配置,实现故障秒级自愈
Posted 北京智和信通
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了通过可视化运维配置,实现故障秒级自愈相关的知识,希望对你有一定的参考价值。
急促的告警铃声响彻寂静的夜晚。对运维人来说,晚间值守耗费更大的精力,往往一个简单的磁盘使用率告警通知,就不得不爬起来进行处理,毕竟告警无小事,对于小问题,运维人也不能心存侥幸心理。虽然有着值班人员和团队的支撑,但频繁的告警还是让运维人员精疲力竭,如何让系统的稳定性提高,减轻一线人员的工作量,减轻一线人员的压力?通过智能运维,实现故障自愈将成为不可避免的选择。
故障自愈是提升企业网络系统可用性和降低故障处理的人力投入,实现故障自愈从"人工处理"到"无人值守"的变革。通过实时发现告警,进行预诊断分析,判断告警类型和级别,如果是一般告警,平台进行自动恢复,如果是严重复杂告警则通过告警通知、运维工单等形式通知运维管理人员,进行人工处理。
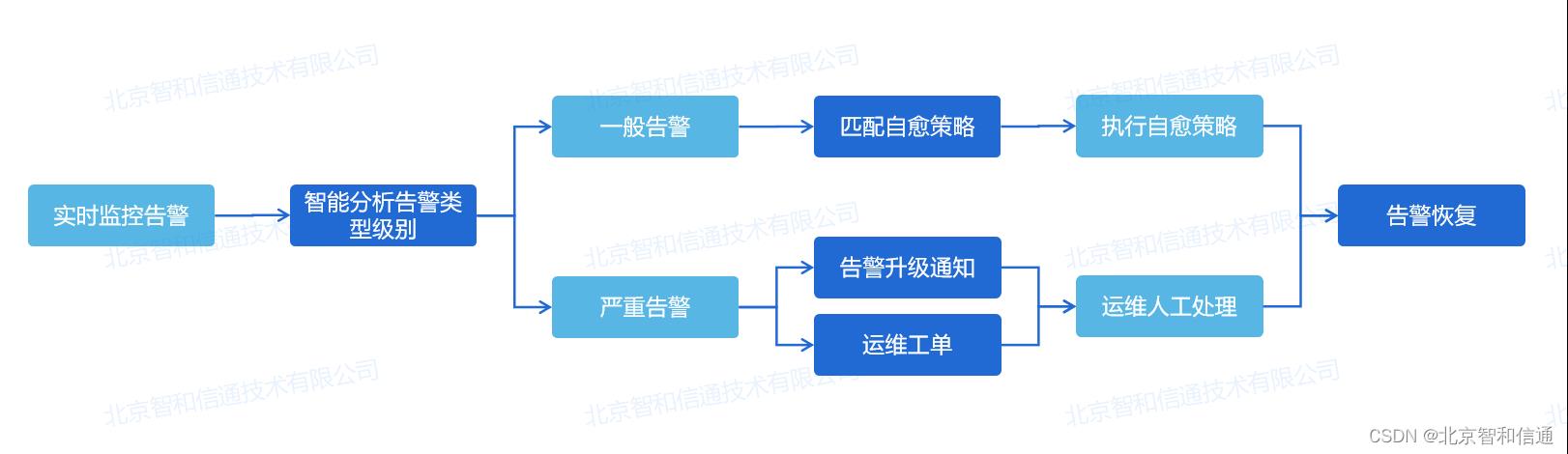
针对运维中对故障自愈能力的需求,北京智和信通在实时监控告警的基础上,搭载可视化运维配置模块,通过赋予用户自定义编辑故障自愈策略的能力,实现无需针对告警进行手动处置,只需预编排告警处理流程,平台根据场景自动触发,从而做到故障自愈。
在故障自愈方案中,核心是匹配用户应用场景的故障自愈策略,一个符合用户需求的策略,将为用户节约80%的故障处理时间。因此,北京智和信通提供可视化编排工具,支持以拖拽的方式快速简单的完成作业流程的配置,将复杂的运维工作和任务转变为一致的,可复用的、可度量和有效的工作流,实现自动化运维。通过拖拽流量编排能力,灵活定制自动化运维场景,运维操作过程和结果均可视化呈现,并在策略中不限作业流程配置数量,全面满足不同运维需求,通过高性能作业流量并发执行,解决告警批量处置的难题。
实时监控,秒级告警
提供7*24小时稳定不间断监控网络,最小故障监视间隔可达到5秒。北京智和信通故障自愈方案支持多种告警机制,自定义配置告警阀值,从众多的事件和状态中,系统将零散的状态信息,总结成为当前工作状态,并产生告警,支持快速标示已经执行操作的告警,迅速定位告警设备。
告警管理,风暴抑制
通过对告警机制以及阀值的设置,第一时间获取准确的告警信息,快速定位告警设备,提升告警处理效率,极大的降低了因设备故障给企业带来的损失。包括事件过滤机制、故障事件上报机制、故障事件呈现过滤、故障事件入库过滤、故障事件确认等处理机制,有效避免误报和漏报。
智能流程,全面管理告警
可实现快速的故障定位,能一步定位到发生故障的源头设备,及时处理好故障,有效地预防故障发生。支持以拓扑图的方式回放历史告警下的设备告警变化、拓扑图和链路告警变化,支持快进、后退等播放操作。

多渠道告警通知,实现无错漏
故障可以通过界面颜色、告警列表、Email、钉钉、企业微信等方式发出通知,告警可以向上逐步追溯,按照从全局→网络→设备→资源的管理习惯来组织故障显示。
自动化告警应急处置,实现快速自愈
以网络状态监控、设备性能监测为基础,结合网络流量侦测功能,动态发现网络故障。智能判断告警类型及级别,自动触发预设的故障处置流程,复杂告警指派工单专人处理,常规告警触发安全策略全自动处理。
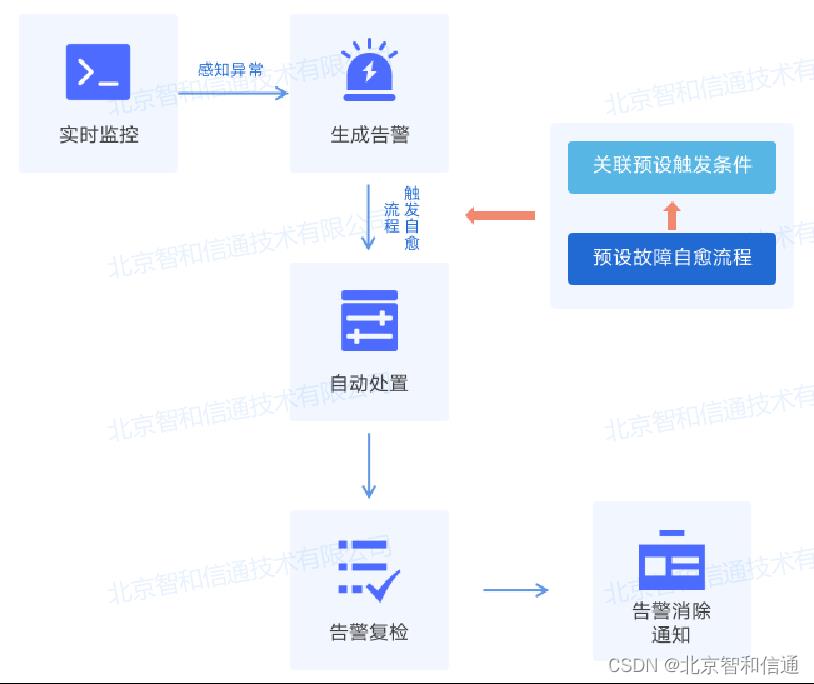
故障自愈方案针对运维过程中的可用性场景,覆盖故障发现、问题定位、自愈策略等各个阶段。同时针对运维需求管理场景,提供网络拓扑、监控、自动化运维、设备控制、资产监管、数据分析、可视化展示、日志分析、运维工单、流量监测等能力,并将其以“积木式”的开发方式进行结合,在实际应用中根据用户的需求场景灵活组合,实现全方位智能安全运维。
中间件运维之故障自愈
1. 目前中间件容器节点故障、机器资源不足(磁盘大小、内存大小、cpu)等问题时有发生,接入自动化运维后可快速的处理集群异常问题。
2. 以前处理问题需要人工介入,人力成本较大,运维流程缺乏规范。
2. 可视化,运维流程可视化、平台化,做到可追踪,可回溯。
3. 自动化,容器重建,进程启停,部分指标通过根因分析实现故障自愈。
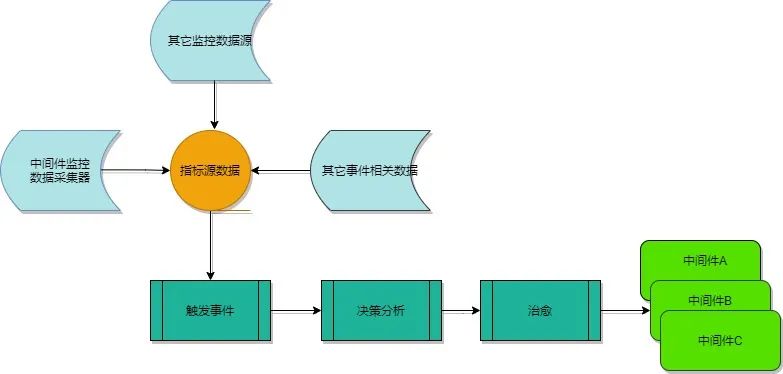
故障自愈的监控数据采集模块,周期性将采集到的各实例指标数据上报给处理器,处理器通过调用元数据模块获取匹配规则、故障自愈处理流。匹配异常数据成功并生成运维事件,再经过事件收敛过滤以确保没有大批量相同属性(如同业务、机房等),最后执行对应编排的自愈处理流,运维事件恢复,发送通知,业务恢复正常。
通过拉取实例监控数据、多指标聚合检测识别出异常,并触发故障自动化流程。
过滤型检测匹配,只跟数据本身有关,时间窗口设定没有要求,数据来一条处理一条。达到设定的异常阈值时触发运维事件。此检测方案过于粗暴,对于一些监控数据存在瞬时突刺现象也会触发误运维,若频繁自愈会影响中间件稳定性。此方案一般用于告警触发,用作运维触发存在一定风险。
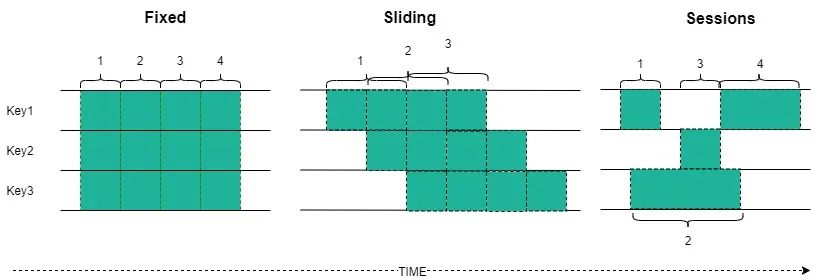
固定窗口(fixed windows):设置一个固定的时间长度,实时统计窗口时间内的数据。通常情况会根据key做一些Partition划分,这样可以做一些并发处理,加速计算。
滑动窗口(sliding windows):设置一个窗口长度和滑动长度,如果滑动长度小于窗口的长度,那么就出现一部分窗口会互相覆盖,部分数据存在重复计算;如果窗口长度等于执行周期,那么就是固定窗口的模式;如果窗口长度小于执行周期,就是抽样的计算了。
会话窗口(session windows):针对的是具体的某个事件,比如特定的人看的视频集合等。会话要等待的数据是不确定什么时候到来的,窗口永远是不规整的。
结论:周期性监控数据可以看作相对规律且无穷的数据,故而前两种窗口模式做流式计算比较适合。
基于计算时间的窗口处理问题是非常简单的,只要关注窗口内的数据就可以了,数据完整性也不用操心。但是实际的数据里肯定带有事件时间,这个时间的数据通常在分布式系统中也是无序的,要是系统出现某些点的延迟,那么得到的结果其准确性就大大降低了。基于事件时间对于业务准确性有很明显的好处,但是也有很明显的缺点,因为数据延迟,在分布式系统很难说这段时间内,数据已经完整了。
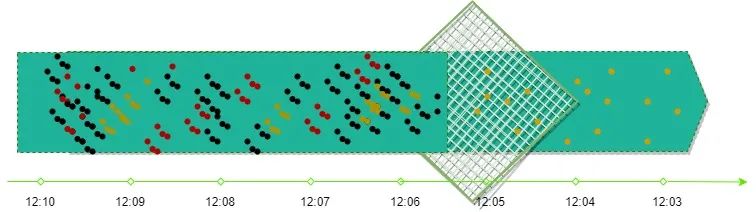
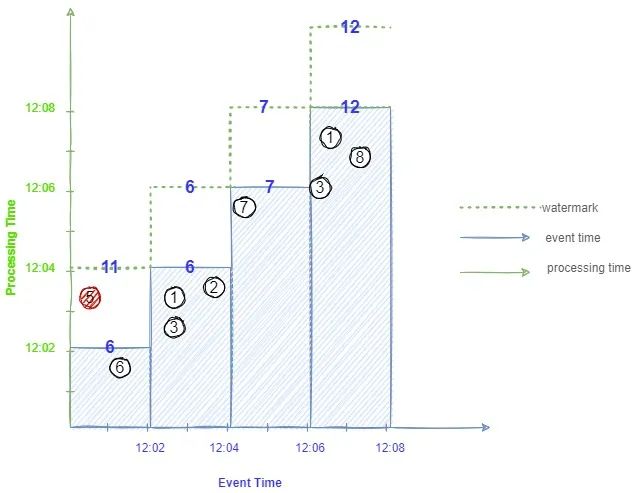
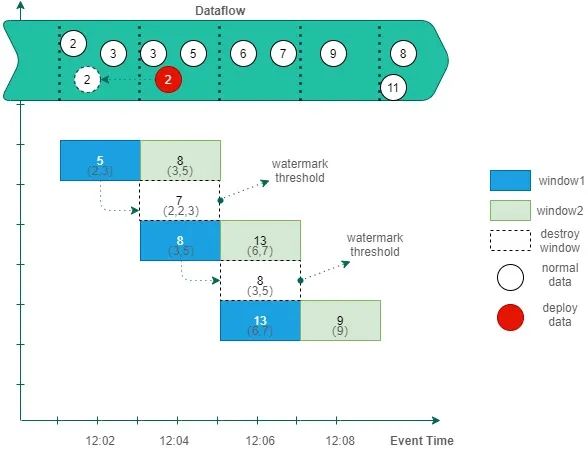
显然无论窗口给的多大,永远无法保证,符合窗口内事件时间的数据一定能够准时到达,利用watermarks (水位线)可以解决什么时候认为数据结束关闭窗口进行计算的问题。如下图:
设定固定窗口2分钟聚合计算,得到的4个窗口聚合结果分别是6、6、7、12,但在第一个窗口12:02聚合结束后,其实该窗口数据在12:03才算完整完整,故而得到的结果不准确,引入watermark可得到正确的聚合结果11。这里的watermark表示多长时间以前的数据将不再更新,也就是说每次窗口聚合之前会进行watermark的计算,首先判断这次聚合窗口最大事件时间,然后加上所能忍受的延迟时间就是watermark,当一组数据或新接收的数据事件时间大于watermark时,则该数据不会更新,可弹出窗口内的数据进行计算且在内存中不再维护该组数据的状态。
中间件监控数据周期性上报数据量不是很大,分布式系统中对于轻量级流可以考虑利用redis做实时聚合,并实现滚动窗口触发。
如上图所示,设定匹配的窗口大小为2分钟,允许数据
最大延迟时间为2分钟,则watermark = 窗口时间的最大值+2,通过往redis缓存实时聚合两个窗口结果即可完成窗口持续滚动,当事件时间大于window1窗口的watermark threshold 时间时,立即弹出window1窗口给process处理器判断是否超过异常阈值,若超过则产生运维事件等待自愈,同时将第二个窗口window2的数据移动至第一个窗口window1中,从而实现持续滚动效果。
总结:滚动窗口占用缓存空间较少,聚合速度快,不足地方可能存在匹配不精准,如果设置窗口时间较大,聚合结果到达配置阈值的数据刚好位于两个窗口相连的数据集中,此时是不会触发运维事件的,其次多指标(一个监控指标对应一个固定窗口)匹配运维事件时,会存在多窗口到达水位线后的弹出时间对不齐的情况,可能存在永远匹配不上的情况。这个时候还需增加窗口之间匹配等待来解决该问题。基于滑动窗口方式可解决以上两个问题。
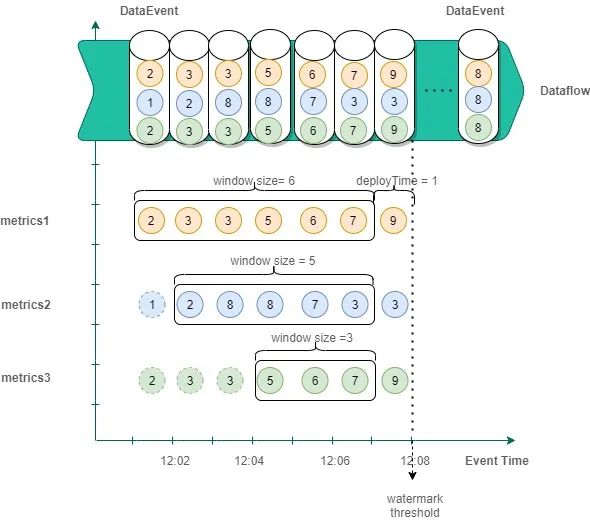
多指标滑动窗口; DataEvent为某个实例监控数据,每分钟上报一次或多次,数据包含3个指标项metrics1、metrics2、metrics3,若配置三个指标项周期聚合结果超过设定阀值则触发运维事件,其周期窗口大小分别为6分钟、5分钟、3分钟,滑动窗口时间1分钟,允许最大延迟时间为1分钟,则在12:08分后同时弹出三个窗口数据进行聚合匹配运维事件规则。同时窗口向前移动,不再参与统计的数据则可不在缓存中维护,如上图带虚线的指标项数据。
相同事件在短时间内多次发生,自愈事件可能会发生并行执行或在短时间内多次触发。自愈往往会涉及到容器或者服务重启,频繁自愈影响集群稳定性,对此可设置一个静默时间对事件做收敛,静默时间未过不再往自愈服务发送事件。
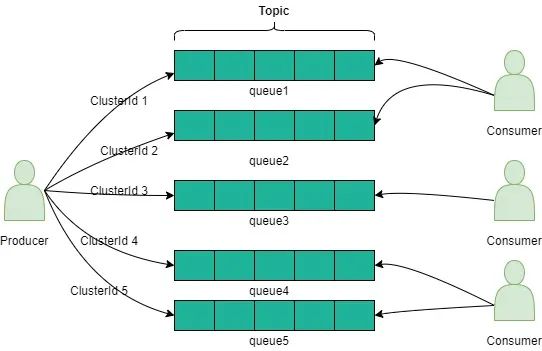
1.同一集群下,集群事件与实例事件互斥,即保证在同一时刻只允许集群中的一个节点进行自愈行为。若集群中的实例都在自愈(如垂直扩容),则会导致集群不可用。同集群实例实现串行化自愈可通过MQ发送端利用集群ID做路由到指定队列上,消费端拉取队列按顺序消费完成。如下图所示:
2.当有新节点添加/下线时,会给节点2分钟的容忍时间,防止由于节点刚刚添加到集群/或下线的不稳定性导致错误自愈。
3.针对自愈解决不了的场景设置自愈次数上限,防止循环自愈,并发通知。
4.历史过期事件过滤,每个事件有过期时间,表示这个事件在发生多久后,会认为过期,事件在决策流程时会先判断是否有效,过期的事件不用再处理。
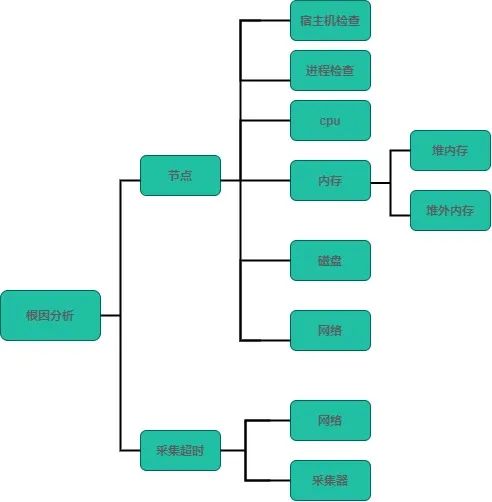
运维事件触发回调进行故障分析,分析根本原因,识别误运维。拉取运维事件对应的根因分析策略,主要利用动态指标+决策树实现自愈,整个分析自愈模块可视化。指标:主要是监控项的指标,如系统负载、cpu使用率、内存使用率、网络I/O、磁盘使用率、系统日志、gc日志等。
利用根因分析及异常结论总结,在元数据模块进行可视化的事件处理流程编排以及决策动作、执行动作的配置,当检测到运维事件发生后,结合事先编排的事件处理流,并执行相关的流程动作,实现服务自愈效果。
通过拉取监控数据,检测匹配异常数据触发运维事件,再结合编排的事件处理流自动完成一些比较繁琐的自愈行为,整个执行流程可视化、串行化。以上仅例举节点异常事件编排,还可编排磁盘清理、扩容等运维场景,同时沉淀故障处理经验形成知识库,回溯过往发生的异常监控数据来提前发现问题,并处理潜在故障。
Carry OPPO 高级后端工程师
目前在OPPO负责中间件自动化运维的研发,关注分布式调度、消息队列、Redis等中间件技术。
以上是关于通过可视化运维配置,实现故障秒级自愈的主要内容,如果未能解决你的问题,请参考以下文章
实现秒级监控MySQL数据库并发
运维太难?说说故障自愈的那些事儿~
故障自愈:解决运维的主要矛盾才能AIOps
故障自愈,无人值守,百度在AIOps方向上的运维实践 | 电击程序猿
作为高效运维人员不得不思考的问题
阿里如何做到百万量级硬件故障自愈?