故障自愈,无人值守,百度在AIOps方向上的运维实践 | 电击程序猿
Posted 一零二四学院
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了故障自愈,无人值守,百度在AIOps方向上的运维实践 | 电击程序猿相关的知识,希望对你有一定的参考价值。

本期嘉宾:百度运维技术经理 曲显平
演讲会议:部分内容选自 1024学院旗下品牌iTechClub主办·华南区第六届互联网技术精英高峰论坛
整理编辑:小猿
运维一直是个繁重的活,并且随着公司规模的增大,运维压力直线提升。
有一张大饼图揭示了运维的工作时间都消耗在哪里:
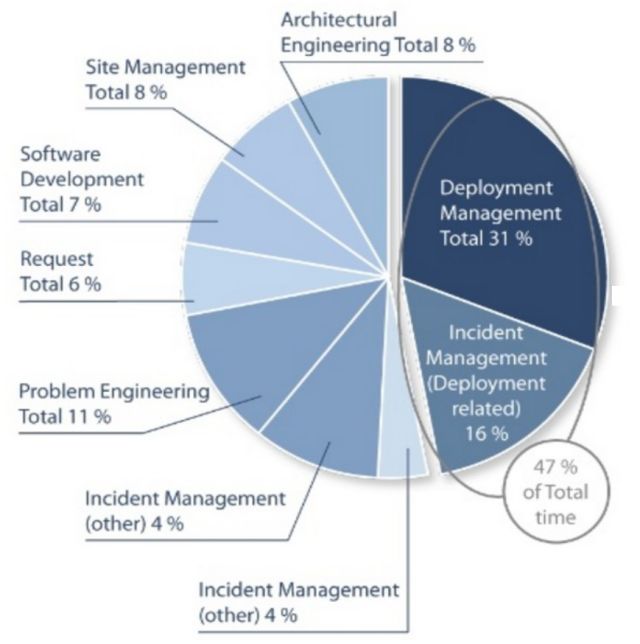
可以看见,47%的时间消耗在两项工作中:
1.执行实际的部署工作。
2.修复与部署工作有关的问题。
这一方面是日益增长的庞大业务线问题,一方面是研发和运维日益严重的隔阂问题,剩下的就是手动运维到自动运维的转化问题。
就业务复杂度而言,单以百度来说,就包括七大业务线:搜索,广告,地图,金融,云,无人车,AI,且每条业务线都很重要,相关的运维平台需要大量的单独对接和开发。

而研发和运维的低效率沟通就更古怪了。长期以来,双方所属部门不同,日常工作的侧重点不同,使用的经费也不同,导致一堵无形的壁垒出现在中间。但最终大家发现,不管基于何种目的,只要配合不默契最后的结果都一样:项目失败。
最后在自动化运维的问题上,大家有一个普遍的错觉:我们就是自动化运维。但实际上根据调查,在运维情境中,61%的企业使用脚本完成的工作占比低于10%。
而手动输入指令这件事有多要命呢?请看下方的面条图:
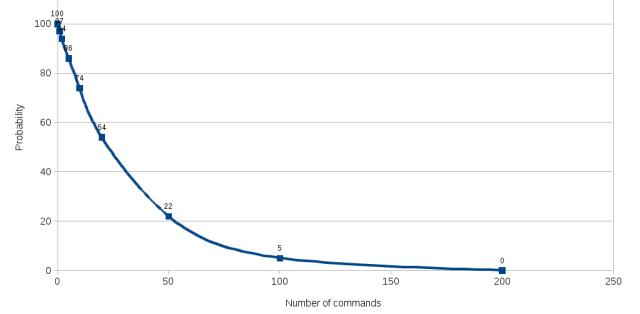
仅仅手动输入五条命令,成功率就跌到了86%,手动输入200条命令,成功率约等于0%。
所以现代运维的问题主要可以归结为一句话:活儿多嘴笨还手残。

在这种情况下最先出现的是DevOps, 很多人提起DevOps喜欢立刻吐出一堆工具链,比如puppet,Docker,Redmine,Jenkins,Zabbix等等,但实际上DevOps是一个方法论,自动化运维只是其中的一部分。
本质上,DevOps是为了解决掉通往敏捷开发路上的一切障碍,打破相关各部门的沟通壁垒,全自动化运维部署。
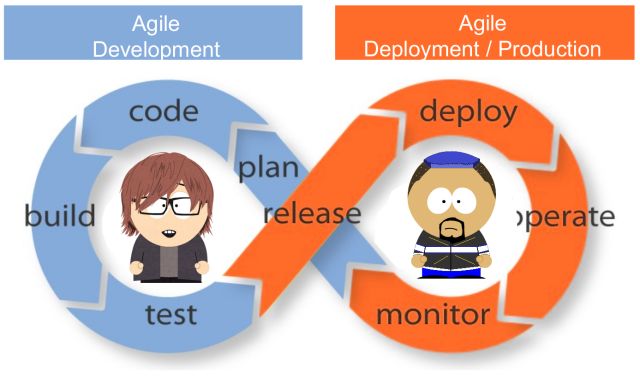
简单点说,主要是打破研发和运维的沟通壁垒:
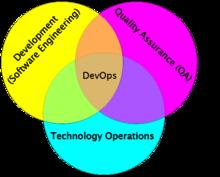
说全一点,是解决开发、运维、QA三方的沟通问题:
那么DevOps有用吗?有用,有大用,据一份第三方统计机构调查3200位从业人员以后的信息显示:
组建了DevOps团队以后,代码部署频率提高了46倍,但变更失败率却降到了之前的五分之一。
但这种事你始终要多留一个心眼来看,DevOps是一个方法论,而不是一套确实的开源工具,更不是哈利波特的魔杖,具体执行起来的效果肯定会有优劣之分。
而且但凡可以归结为一个方法论的东西,就存在相当的模糊性,从许多从业者甚至说不准DevOps的概念这点就可见一斑。

不然百度也不会再加上一套SRE体系与其互补。
SRE是谷歌率先提出来的概念,全称是Site Reliability Engineer (网站可靠性工程师),要求更高更直接,就是要求你既会开发,又懂运维。
得咧您呐,就您自己干吧,只要不是精神分裂,应该不存在什么沟通问题。
SRE一般都是从研发工程师转行的,唯一目的就是保证网站不宕机。但这种复合型人才的招聘难度也很大,涉及到职位赋能时大家更懵,如果使用SRE体系,中小企业基本就可以说拜拜了,反正你也招不到人。

在这种情况下,百度开始了更高阶的运维方案实践之路:AIOps。
AIOps,也就是基于算法的IT运维(Algorithmic IT Operations),是由Gartner定义的新类别,源自业界之前所说的ITOA(IT Operations and Analytics)。
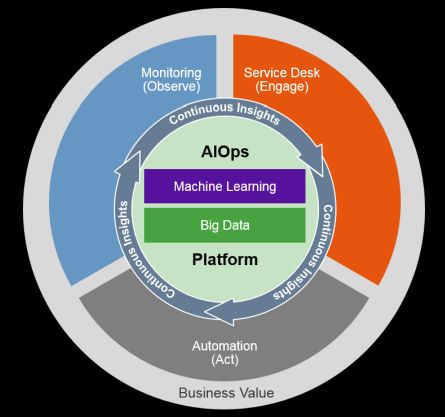
目前百度团队对AIOps的应用主要有四个方面:故障管理,变更管理,容量管理,服务咨询。
核心包括三个方面:运维知识库,运维开发框架,运维策略算法平台。
在构建AIOps之前,百度将问题场景归纳在四个象限之中:
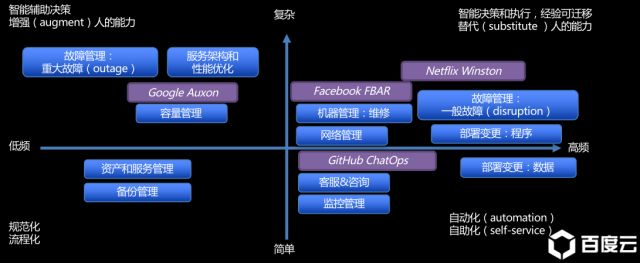
类似全网宕机等重大故障,虽然问题复杂,但属于低频问题;像监控管理、部署变更类工作,虽然问题并不复杂,但发生频率很高。
站在运维的角度上,优先考虑解决高频、简单的应用场景,因为这种问题虽然往往简单,危害低,但是却消耗了大量的人力。(老板想的正好相反,并叫你到办公室来一趟)
基于对问题场景的理解,百度首先规划了庞大的运维数据网络,即三个核心之一的运维知识库。
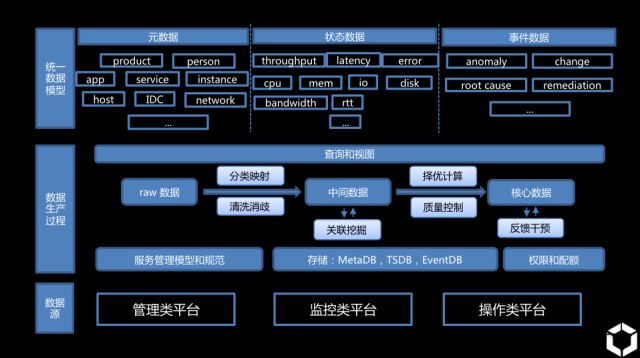
从图中可以看出,运维数据主要分三大类。
第一类是元数据,元数据可以理解为针对任何一个个体单位的数据,这个个体可以是一个产品,一个人,一个APP,一个网络,等等。
第二类数据是状态数据,这些数据是传统运维最关注的部分,涉及硬盘,内存,cpu的使用情况等。
第三类数据叫做事件数据,是最难归纳的数据,包括一些告警、紧急方案等等。它相当于基于运维的理解,归纳出的逻辑数据。该数据的准确与否,直接影响整个系统的行为。
就像我们曾经在过去的文章中反复提到的一样,没有数据的AI开发都是扯淡,百度整理这套数据总共耗费了四年有余。

准确的归纳出运维的指标数据是一件相当困难的事,数据必须完整又足够描绘出整套运维框架,这是AI版的“0和1”。
建筑在运维知识库(运维数据)之上的,才是完整的运维开发框架:
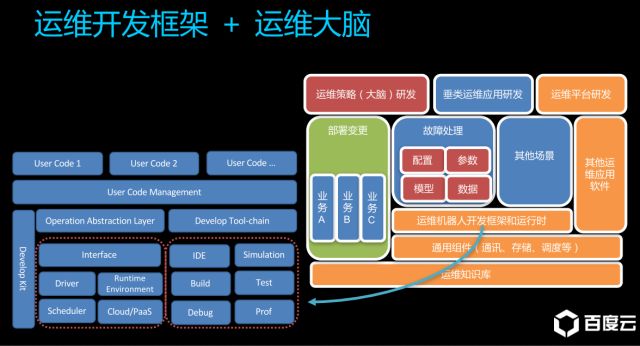
在这张令人眼花缭乱的架构图中,有两项工作最困难,却又是我们最熟悉的。
1.模块的抽象和封装
在所谓的OPAL(operation abstraction layer)部分,所需要的还是大量的完整的封装工作,可以说自打有模块化开发的概念,良好的抽象封装在架构设计上就一直是个绕不开的弯。
复杂的交流,复杂的接口,本质上都是抽象和封装的不完善。
比如你说你想吃胡同东头的山东大蒜拌意大利面,同伴说想吃西头的牛肉汉堡沾东北大酱,然后你们开始为了吃法而争论不休。
其实正确的说法是:“我饿了,吃饭吧。”

2.大型测试环境的构建
而在Develop Tool Chain部分,有一个Test,涉及大型测试环境的构建。
这点研发和运维的怨言倒是史无前例的达成了统一。很多公司纠结成本问题,舍不得买服务器构建大型的机房级别的测试环境。
实际上很多线上问题的根源就在这,测试环境和线上环境的差距过大。
这一点 百度做到了。

看的出来,不管我们把AI这个词讲的多么高端,很多基础问题仍然围绕在IT圈说了二十年的东西,数据、抽象、测试环境,这是一条没有捷径的路。
很多人听到AI乐够呛,以为冒出来个黑科技,把坑都绕过去了。实际上这个“黑科技”是帮你在传统大坑后面,挖好了下一个坑,只不过最后到达的地方,天空也更加蔚蓝。
在漫长的基础准备工作后,AIOps终于开花结果,以下是三个百度在AIOps方向上的实践例子:
1.智能故障自愈
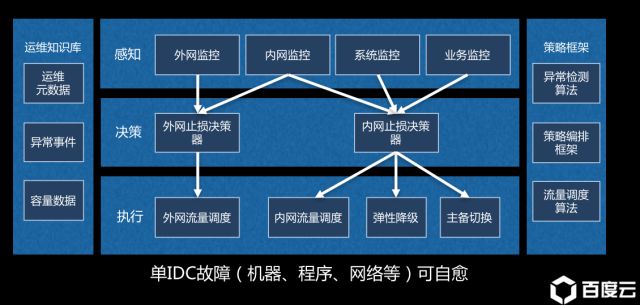
其核心还是运维知识库,由于IDC故障的原因五花八门,归纳异常事件的种类完全是个技术活儿。但在这方面的工作越优秀,也意味着整个系统越智能,据说,谷歌已经可以达到任何一个IDC的故障自愈。
2.无人值守上线
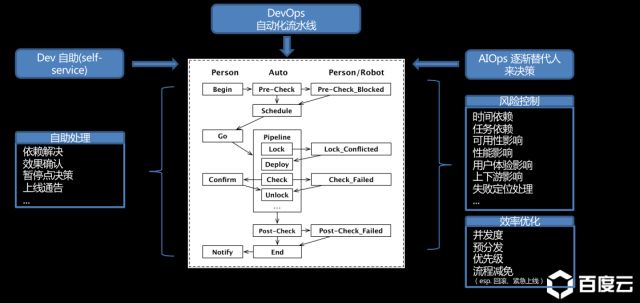
早期可能还是需要人工检验规划结果,目标是慢慢彻底的去人工化。
3.智能客服机器人
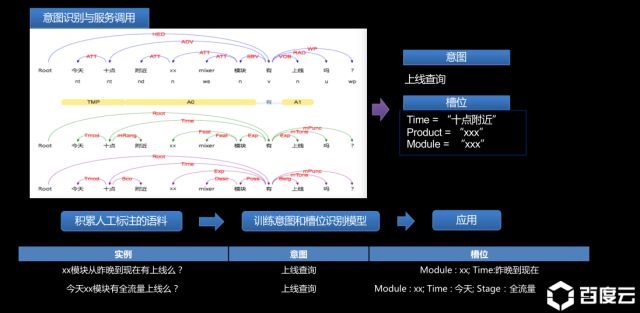
在服务企业内部的智能客服上面,百度在自然语言处理方面有天然的研究优势,而且单独对于运维场景来说,该系统的难度要降低很多。
毕竟运维同学应该不会闲着没事去找智能客服聊骚。
如同AI技术的不断发展一样,AIOps的演化也在不断地进行,从自动化到智能化,这是一个升级蜕变的过程。
但运维同学也不要过于高兴,谁说以后就是“喝着咖啡做运维”了?兴许以后就没有运维了呢?
以上是关于故障自愈,无人值守,百度在AIOps方向上的运维实践 | 电击程序猿的主要内容,如果未能解决你的问题,请参考以下文章