深度学习中的优化算法之AdaGrad
Posted fengbingchun
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深度学习中的优化算法之AdaGrad相关的知识,希望对你有一定的参考价值。
之前在https://blog.csdn.net/fengbingchun/article/details/123955067 介绍过SGD(Mini-Batch Gradient Descent(MBGD),有时提到SGD的时候,其实指的是MBGD)。这里介绍下自适应梯度优化算法。
AdaGrad:全称Adaptive Gradient,自适应梯度,是梯度下降优化算法的扩展。AdaGrad是一种具有自适应学习率的梯度下降优化方法。它使参数的学习率自适应,对不频繁的参数执行较大的更新,对频繁的参数执行较小的更新(It adapts the learning rate to the parameters, performing larger updates for infrequent and smaller updates for frequent parameters)。因此,它非常适合处理稀疏数据。AdaGrad可大大提高SGD的鲁棒性。如下图所示,截图来自:https://arxiv.org/pdf/1609.04747.pdf

在SGD中,我们每次迭代对所有参数进行更新,因为每个参数使用相同的学习率。而AdaGrad在每个时间步长(every time step)对每个参数使用不同的学习率。在SGD和MBSD中,对于每个权值(each weight)或者说对于每个参数(each parameter),学习率的值都是相同的。但是在AdaGrad中,每个权值都有不同的学习率。在现实世界的数据集中,一些特征是稀疏的(大部分特征为零,所以它是稀疏的),而另一些则是密集的(dense,大部分特征是非零的),因此为所有权值保持相同的学习率不利于优化。
AdaGrad的主要优点之一是它消除了手动调整学习率的需要。AdaGrad在迭代过程中不断调整学习率,并让目标函数中的每个参数都分别拥有自己的学习率。大多数实现使用学习率默认值为0.01,开始设置一个较大的学习率。
AdaGrad的主要弱点是它在分母中累积平方梯度:由于每个添加项都是正数,因此在训练过程中累积和不断增长。这反过来又导致学习率不断变小并最终变得无限小,此时算法不再能够获得额外的知识即导致模型不会再次学习。Adadelta算法旨在解决此缺陷。
以下是与SGD不同的代码片段:
1.在原有枚举类Optimization的基础上新增AdaGrad:
enum class Optimization
BGD, // Batch Gradient Descent
SGD, // Stochastic Gradient Descent
MBGD, // Mini-batch Gradient Descent
SGD_Momentum, // SGD with Momentum
AdaGrad // Adaptive Gradient
;2.为了每次运行与SGD产生的随机初始化权值相同,这里使用std::default_random_engine
template<typename T>
void generator_real_random_number(T* data, int length, T a, T b, bool default_random)
// 每次产生固定的不同的值
std::default_random_engine generator;
std::uniform_real_distribution<T> distribution(a, b);
for (int i = 0; i < length; ++i)
data[i] = distribution(generator);
3.为了对数据集每次执行shuffle时结果一致,这里有std::random_shuffle调整为std::shuffle:
//std::srand(unsigned(std::time(0)));
//std::random_shuffle(random_shuffle_.begin(), random_shuffle_.end(), generate_random); // 每次执行后random_shuffle_结果不同
std::default_random_engine generator;
std::shuffle(random_shuffle_.begin(), random_shuffle_.end(), generator); // 每次执行后random_shuffle_结果相同4.calculate_gradient_descent函数:
void LogisticRegression2::calculate_gradient_descent(int start, int end)
switch (optim_)
case Optimization::AdaGrad:
int len = end - start;
std::vector<float> g(feature_length_, 0.);
std::vector<float> z(len, 0), dz(len, 0);
for (int i = start, x = 0; i < end; ++i, ++x)
z[x] = calculate_z(data_->samples[random_shuffle_[i]]);
dz[x] = calculate_loss_function_derivative(calculate_activation_function(z[x]), data_->labels[random_shuffle_[i]]);
for (int j = 0; j < feature_length_; ++j)
float dw = data_->samples[random_shuffle_[i]][j] * dz[x];
g[j] += dw * dw;
w_[j] = w_[j] - alpha_ * dw / (std::sqrt(g[j]) + eps_);
b_ -= (alpha_ * dz[x]);
break;
case Optimization::SGD_Momentum:
int len = end - start;
std::vector<float> change(feature_length_, 0.);
std::vector<float> z(len, 0), dz(len, 0);
for (int i = start, x = 0; i < end; ++i, ++x)
z[x] = calculate_z(data_->samples[random_shuffle_[i]]);
dz[x] = calculate_loss_function_derivative(calculate_activation_function(z[x]), data_->labels[random_shuffle_[i]]);
for (int j = 0; j < feature_length_; ++j)
float new_change = mu_ * change[j] - alpha_ * (data_->samples[random_shuffle_[i]][j] * dz[x]);
w_[j] += new_change;
change[j] = new_change;
b_ -= (alpha_ * dz[x]);
break;
case Optimization::SGD:
case Optimization::MBGD:
int len = end - start;
std::vector<float> z(len, 0), dz(len, 0);
for (int i = start, x = 0; i < end; ++i, ++x)
z[x] = calculate_z(data_->samples[random_shuffle_[i]]);
dz[x] = calculate_loss_function_derivative(calculate_activation_function(z[x]), data_->labels[random_shuffle_[i]]);
for (int j = 0; j < feature_length_; ++j)
w_[j] = w_[j] - alpha_ * (data_->samples[random_shuffle_[i]][j] * dz[x]);
b_ -= (alpha_ * dz[x]);
break;
case Optimization::BGD:
default: // BGD
std::vector<float> z(m_, 0), dz(m_, 0);
float db = 0.;
std::vector<float> dw(feature_length_, 0.);
for (int i = 0; i < m_; ++i)
z[i] = calculate_z(data_->samples[i]);
o_[i] = calculate_activation_function(z[i]);
dz[i] = calculate_loss_function_derivative(o_[i], data_->labels[i]);
for (int j = 0; j < feature_length_; ++j)
dw[j] += data_->samples[i][j] * dz[i]; // dw(i)+=x(i)(j)*dz(i)
db += dz[i]; // db+=dz(i)
for (int j = 0; j < feature_length_; ++j)
dw[j] /= m_;
w_[j] -= alpha_ * dw[j];
b_ -= alpha_*(db/m_);
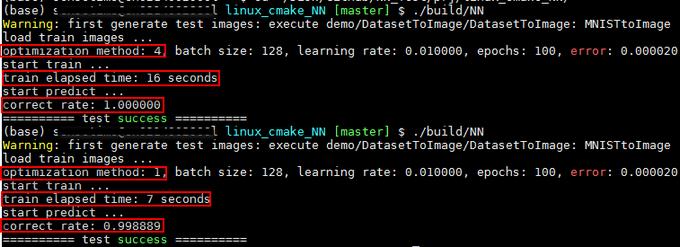
执行结果如下图所示:测试函数为test_logistic_regression2_gradient_descent,多次执行每种配置,最终结果都相同。在它们学习率及其它配置参数相同的情况下,AdaGrad耗时为16秒,而SGD仅为7秒;但AdaGrad的识别率为100%,SGD的识别率为99.89%。
GitHub: https://github.com/fengbingchun/NN_Test
以上是关于深度学习中的优化算法之AdaGrad的主要内容,如果未能解决你的问题,请参考以下文章
深度学习笔记:优化方法总结(BGD,SGD,Momentum,AdaGrad,RMSProp,Adam)
深度学习优化算法大全系列5:AdaDelta,RMSProp
优化算法比较的实验结果比较(BGD,SGD,MBGD,Momentum,Nesterov,Adagrad,RMSprop)