深度学习语义分割篇——FCN原理详解篇
Posted 秃头小苏
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深度学习语义分割篇——FCN原理详解篇相关的知识,希望对你有一定的参考价值。
🍊作者简介:秃头小苏,致力于用最通俗的语言描述问题
🍊往期回顾:目标检测系列——开山之作RCNN原理详解 目标检测系列——Fast R-CNN原理详解
目标检测系列——Faster R-CNN原理详解🍊近期目标:写好专栏的每一篇文章
🍊支持小苏:点赞👍🏼、收藏⭐、留言📩
没想到今天是创作两周年,必须浅浅更新一篇⛳⛳⛳
深度学习语义分割篇——FCN原理详解篇
写在前面
在过往的博客中,我已经介绍了几种经典神经网络(VGG、GoogleNet、Resnet等等)在图像分类上的应用,这些都是非常基础却重要的内容,大家务必要掌握,不了解的可以进入个人主页搜索了解详情。🌼🌼🌼在目标检测方面,我有讲解过yolo系列的原理,点击☞☞☞了解详情。但是yolo代码部分还没有出过相关教程,看看后面是否有时间吧!!!🌼🌼🌼此外,目标检测方面我也详细的介绍了Rcnn的一系列原理及Faster rcnn的源码解析,链接如下:
- 目标检测系列——开山之作RCNN原理详解 🍁🍁🍁
- 目标检测系列——Fast R-CNN原理详解 🍁🍁🍁
- 目标检测系列——Faster R-CNN原理详解 🍁🍁🍁
- 还不懂目标检测嘛?一起来看看Faster R-CNN源码解读 🍁🍁🍁
对于语义分割自己也一直没有详细了解过,最近也是学习了一下语义分割的开山之作——FCN网络,全称为Fully Convolutional Networks for Semantic Segmentation 。我先来说说我以前对语义分割网络的主观认识,那就是一个字难,正常的学习路线是先图像分类,接着是目标检测,最后才是语义分割。如果你看过上文提到的Faster Rcnn源码的话,你会发现其理解起来还是很难的,而且代码量也非常的大。这样一来,我自然会认为语义分割的代码是恐怖级别的,但是通过我这几天的学习,我发现不管是FCN的原理还是代码都是相对简单的【只针对FCN,其它语义分割网络还没学习,因此也不清楚它们的难度如何】。说这个就是想告诉大家不要害怕语义分割,它远没有想象中的那么难!!!🍦🍦🍦
各位准备好了嘛,我们将一起搭上语义分割号列车,启航!!!🚆🚆🚆
语义分割概念
我想来看这部分内容的读者应该已经对语义分割的概念有所了解了,大家也别嫌我啰嗦,我还是打算给大家来辨析辨析什么物体分类,什么是目标检测,什么是语义分割以及什么是实例分割。物体分类很好理解啦,就是给出一张狗的图片,计算机把这张图片的类别辨别为狗,给出一张猫的图片,计算机把这张图片的类别辨别成猫。下面主要来看看目标检测、语义分割和实例分割的区别,如下图所示:

从上图可以看出,目标检测只会把物体用方框框出来,也会识别出类别(图中未画)。语义分割则会顺着物体的边缘把物体标出来,同样会识别出类别,语义分割可以看成是更加精细的目标检测。实例分割中的实例指的是个体,我们从图中可以发现,实例分割中的不同三人用不同颜色表示,即识别出每一个个体,实例分割可以看成更加精细的语义分割。
相信大家通过上图和相关解释已经明白了物体分类、目标检测、语义分割和实例分割的区别。那么接下来我将为大家详细的讲讲语义分割的开山之作——FCN。
FCN网络整体结构✨✨✨
我们先来看看FCN的整体结构,如下图所示:
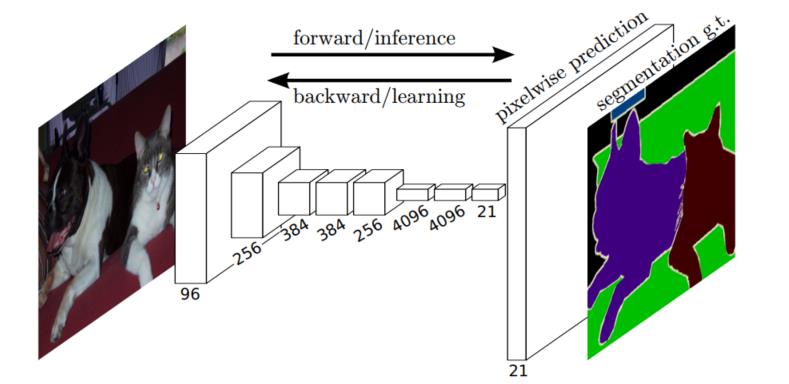
大家看到上图的第一反应是什么呢?反正我看到是有点惊讶的,惊讶于语义分割的网络竟然如此简单,不知道大家有没有和我一样的感受呢!🥕🥕🥕
虽然简单,但我们还是要来解释一下,特别要注意理解语义分割的思想。首先,输入是一张RGB三通道的图片,然后会输入特征提取网络提取特征,上图的特征提取网络为AlexNet。(对AlexNet不熟悉的可以点击☞☞☞了解详情)需要注意的是传统AlexNet的后三层为全连接层,而FCN中采用的是卷积层,这样将全连接层换成卷积层可以适应不同尺度的图片。现在看来,这种转化你可能觉得不足为奇,但是大家请注意,这篇文章是2015发表的,那时候有这种思想还是非常可贵的。我们注意到,在特征提取网络的最后一个特征图的通道数是21,这个21是很有讲究的喔,它对应着我们要分类的类别总数,包括背景。论文中使用的是VOC数据集,一个有20个前景类别和一个背景共21个类别数。接着我们会将刚刚得到的chanel=21的特征图进行上采样,将其尺寸变为原始输入图像大小【注:通道数还是21】。最后我们会和语义分割的标注图像(GT)计算损失,最终,这个21通道的原图大小的特征图的每个像素都有21个通道,即有21个值,我们取最大的一个值,其索引对应的类别就是该像素的所属类别!!!🍄🍄🍄
FCN的整体结构就为大家介绍到这里,相信大家心中还是存有疑惑,特别是最后一部分,不用担心,下文我会详细的为大家讲述FCN的细节。🍵🍵🍵
FCN细节理解✨✨✨
在FCN的论文中,主要给出了三种FCN的结构,分别是FCN-32,FCN-16,FCN-8s,如下图所示:
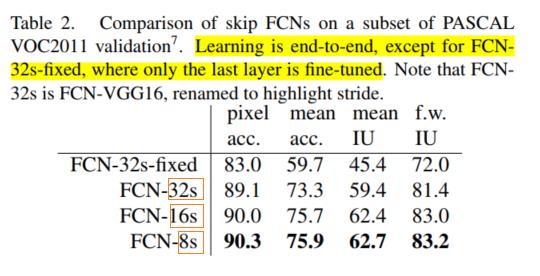
上图的几种网络的backbone都是基于VGG16网络的。【注:FCN-32s-fixed不是end-to-end,这里就不讨论了 】
大家是不是对上图的32s、16s和8s不是很理解呢,这个表示的是最后上采样的倍数。我也会在下文详细为大家介绍FCN的这三种结构,届时大家就会理解了。
FCN-32s结构
上文说过,这几个结构的backbone都是基于VGG16的,因此大家需要对VGG16有一点的认识,不清楚的点击☞☞☞了解详情。【注:在FCN整体结构时使用的是AlexNet,这里为VGG16,大家注意一下就好】
为方便大家阅读,这里贴出VGG16网络结构图,如下图所示:
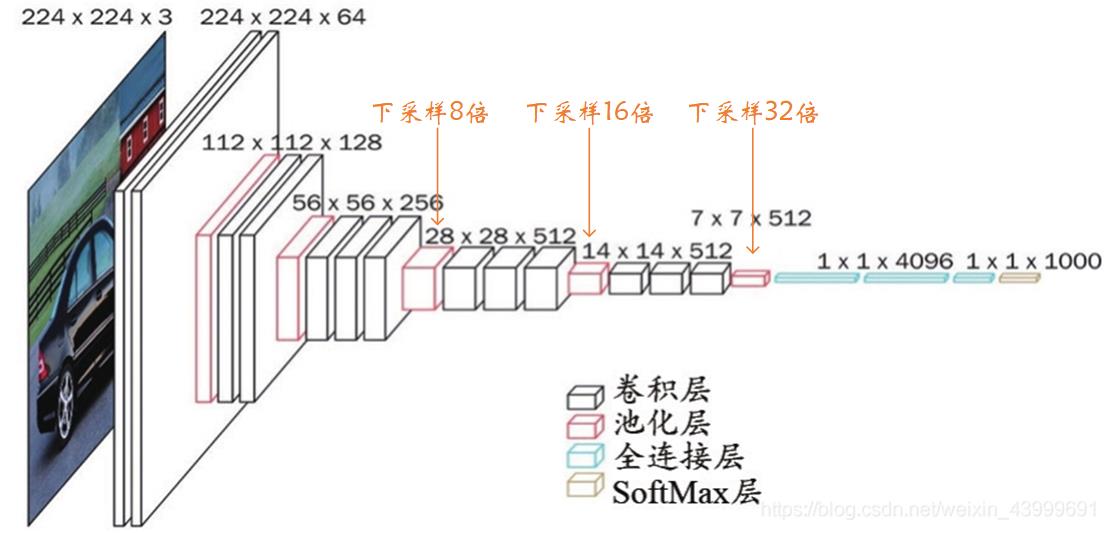
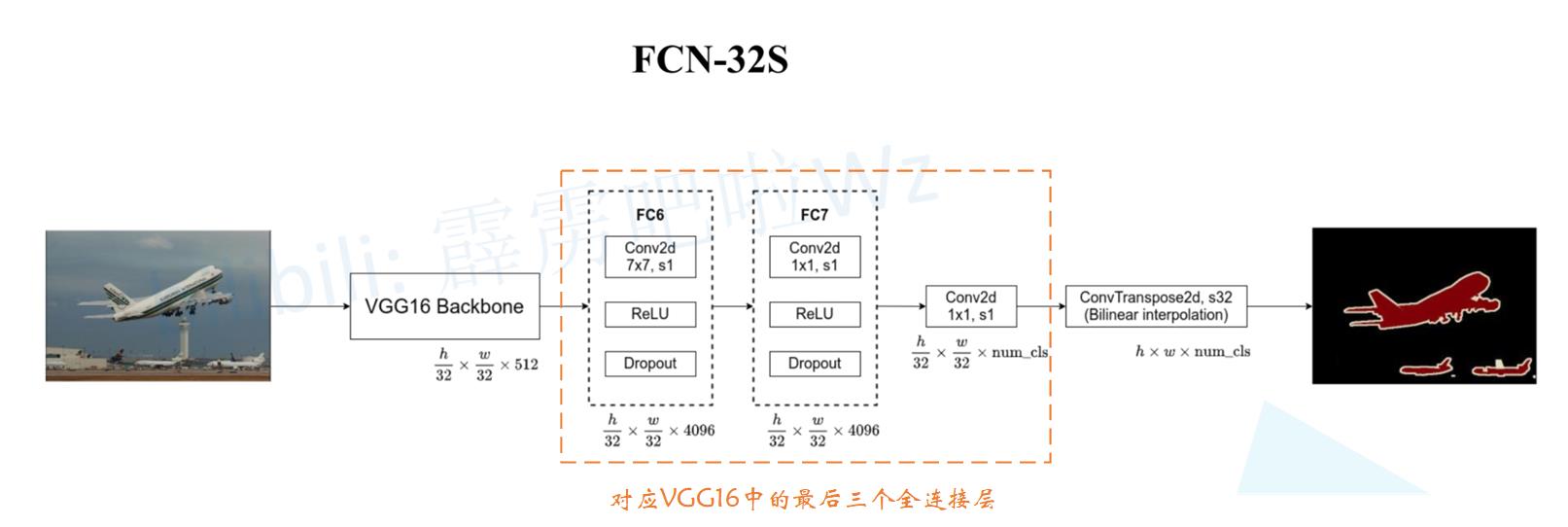
有了VGG16网络的基础,看FCN-32就非常简单了,如下图所示:
图片来自B站霹雳吧啦Wz
现对上图做相关解释。首先一张任意大小的图片经过VGG16下采样了32倍,此时特征图尺寸为 h 32 × w 32 × 512 \\frach32×\\fracw32×512 32h×32w×512,这部分对应着VGG16网络中的卷积层。 接着我们来看上图黄色虚线框住的三个卷积层,其对应着VGG16网络中最后三个全连接层,这样做的原因上文已经说过了,是为了使网络可以适应不同尺寸的输入,这部分结束后特征图的尺寸变为 h 32 × w 32 × n u m _ c l s \\frach32×\\fracw32×num\\_cls 32h×32w×num_cls ,其中 n u m _ c l s num\\_cls num_cls为语义分割的总类别数,对于VOC数据集来说, n u m _ c l s = 21 num\\_cls=21 num_cls=21。🌵🌵🌵
最后我们会经过一个上采样,如使用转置卷积或双线性插值算法进行上采样,将刚刚得到的特征图还原为 h × w × n u m _ c l s h×w×num\\_cls h×w×num_cls尺寸。【对转置卷积不了解的可以看此篇文章转置卷积部分了解详情。】
到这里,其实整个FCN网络就介绍完了,现在来说说FCN的损失是如何计算的。先来看看我们的真实值(GT)是什么,其是一张张P模式的图片,有关图片的P模式,可以点击本文中附录–>VOC语义分割标注了解详情。相信你看了附录中的解释,你已经知道了GT是一张张单通道的图片,其尺寸为 h × w × 1 h×w×1 h×w×1。刚刚由VGG网络得到的输出尺寸为 h × w × n u m _ c l s h×w×num\\_cls h×w×num_cls,我们会根据GT和得到的输出计算出损失LOSS,大致过程如下:
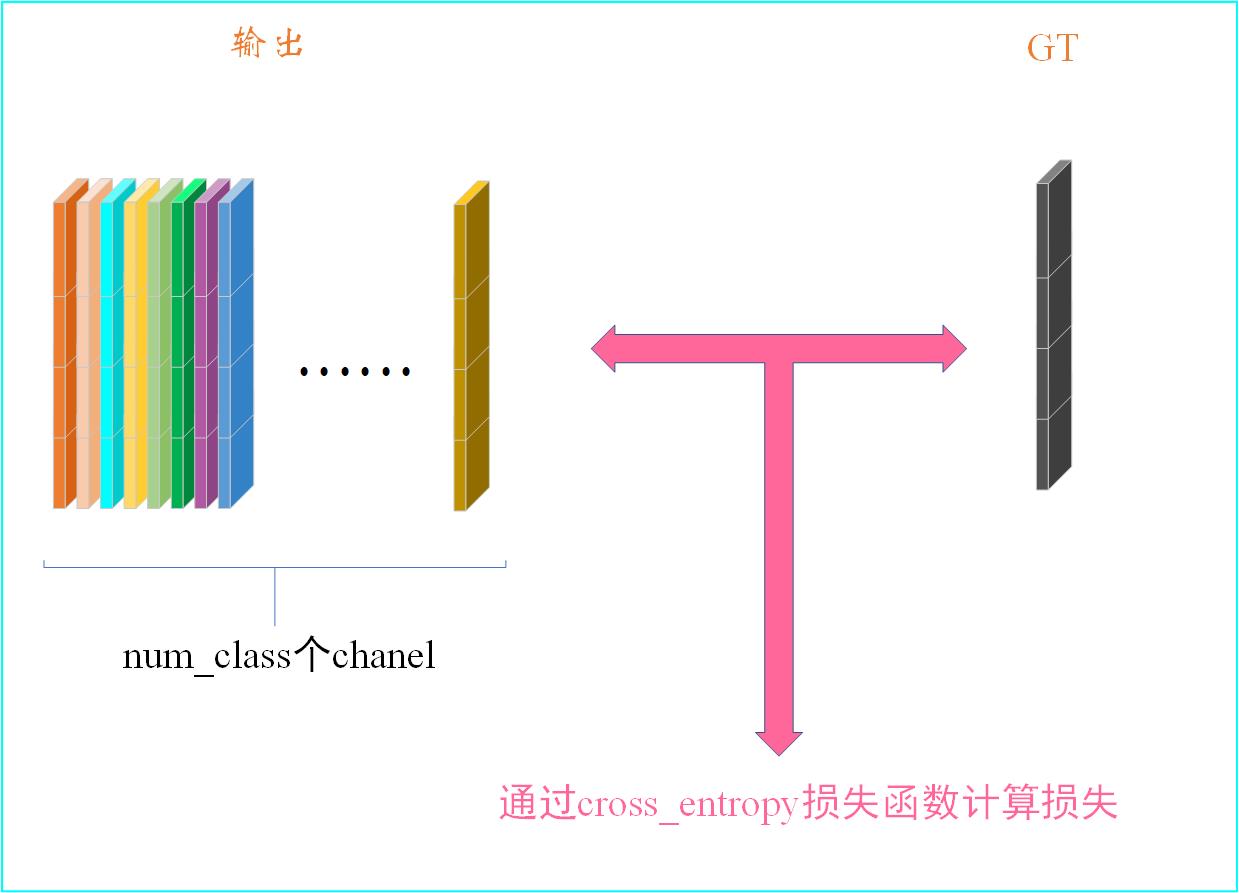
上文我没有给出cross_entropy的具体是怎么做的,大家这里先不用着急,在下一篇FCN代码实战中我会通过代码详细的为大家讲解这个cross_entropy函数。这里我还想强调一点——损失函数的构造是我们实现程序功能的重要一环,它决定了输出的走向,即输出不断的拟合GT,当我们的网络训练的足够好时,网络的输出就和GT足够的接近!!!🌸🌸🌸
FCN-16s结构
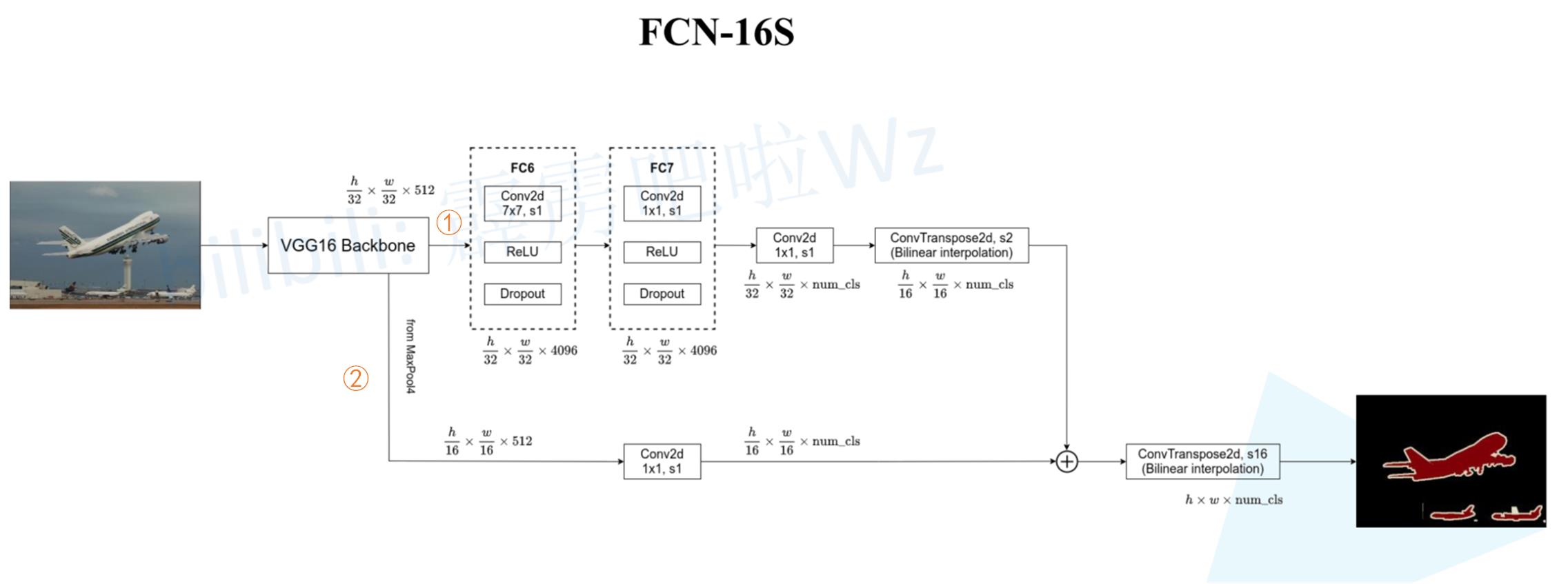
上节介绍了FCN-32s的结构,这节将来讲解FCN-16s的结构。32s和16s表示最后上采样的倍数分别为32倍和16倍。FCN-16s的结构如下图所示:
图片来自B站霹雳吧啦Wz
大家看到这个结构不知道是不是有点熟悉,我感觉有点像特征金字塔(FPN)结构,利用了不同尺度的信息,熟悉FPN的我觉得就非常好理解上图了。
我也来简要的解释一下,首先我们通过VGG后会分成①和②两条路,①路径和FCN-32s大致相同,只是在上采样时只将原图尺寸扩大了两倍,由 h 32 × w 32 × n u m _ c l s \\frach32×\\fracw32×num\\_cls 32h×32w×num_cls 变成 h 16 × w 16 × n u m _ c l s \\frach16×\\fracw16×num\\_cls 16h×16w×num_cls 。②路径的输入是VGG网络下采样16倍时的输出,尺寸为 h 16 × w 16 × 512 \\frach16×\\fracw16×512 16h×16w×512,然后经过一个1×1的卷积核将通道数变成与①相同的通道数,即 n u m _ c l a s s num\\_class num_class。①和②完成后,会将两步的结果相加然后再进行上采样,此时上采样的倍数为16,这样我们就得到了我们FCN-16s的输出了!!!🌸🌸🌸
FCN-8s结构
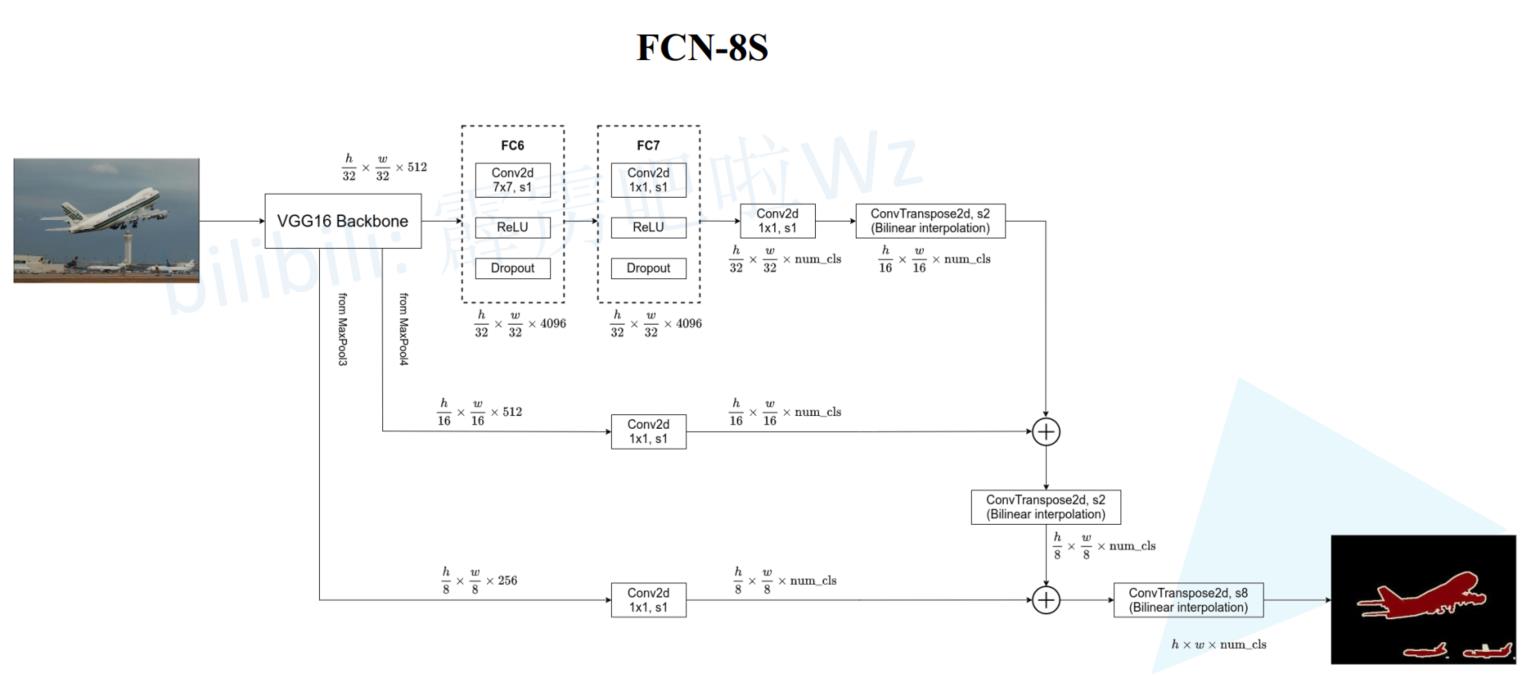
明白了FCN-32s和FCN-16s的结结构,再来看FCN-8s的结构就更简单了。此时用到了VGG网络三个下采样倍数(32倍、16倍、8倍)的输出,其结构如下图所示:
图片来自B站霹雳吧啦Wz
关于FCN-8s的结构我就不带大家一点点分析了,相信你看懂了FCN-32s和FCN-16s再看FCN-8s会毫无压力!!!🌸🌸🌸
小结
FCN的理论部分就为大家介绍到这里了,这部分我觉得大家理解起来应该还是蛮简单的,唯一的难点可能就在损失函数那部分,关于这点,我会在下一篇代码实战中为大家详细解释,同时帮助大家理解FCN的更多细节。🌾🌾🌾
论文下载地址
FCN论文下载 🥝🥝🥝
参考链接
FCN网络结构详解(语义分割) 🍁🍁🍁
附录
VOC语义分割标注✨✨✨
这个部分我来为大家讲讲VOC语义分割的标注,这部分文件存储在VOC2012/SegmentationClass文件夹下,部分内容如下:

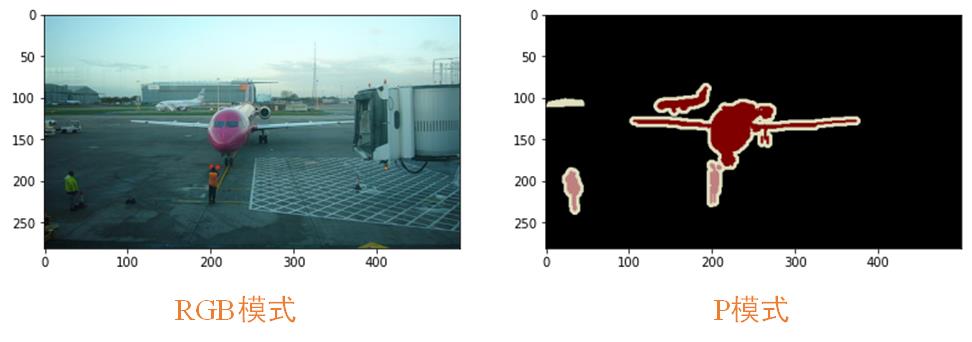
可以看到,这部分文件的格式是png格式。它们图像的模式是P模式,即调色板模式,是单通道的图像。单通道的图像??这明明是彩色的啊,怎么会是单通道的图像??我相信你一定有这样的疑问,我们直接用实验来说话。
为方便做对照,我们使用VOC2012/JPEGImages中的三通道图片2007_000032.jpg 和VOC2012/SegmentationClass中的2007_000032.png图片做对比,首先,我们分别载入两种图片并显示一下,代码如下:
img2 = Image.open('D:/数据集/VOC/VOCtrainval_11-May-2012/VOCdevkit/VOC2012/JPEGImages/2007_000032.jpg')
img3 = Image.open('D:/数据集/VOC/VOCtrainval_11-May-2012/VOCdevkit/VOC2012/SegmentationClass/2007_000032.png')
plt.imshow(img2)
plt.imshow(img3)
img2为RGB模式图片(左),img3为P模式图片(右),如下图:
接着我们可以使用.mode方法打印看看图像的模式是否是我们所说的RGB和P,代码如下:
print("image2:",img2.mode)
print("image3:",img3.mode)
结果:

可以看到,确实和我们所说的一样,它们一个是RGB模式,一个是P模式!!!最后我们来看看最重要的一点,即RGB模式是三通道的图像,而P模式是单通道的图像,代码如下:
# 将PIL格式的图像转化为numpy格式
img2_np = np.array(img2)
# 打印img2的尺寸
print("image2_shape:",img2_np.shape)
img3_np = np.array(img3)
print("image3_shape:",img3_np.shape)
结果:
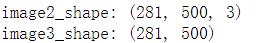
实验为证,现在我想大家是能够接受这样的一个事实了叭。【记住喔,这个对理解FCN还是很重要的】
这里只为大家证明我们使用的VOC标注信息是P模式的通道的图像,关于图像的P模式感兴趣的大家自行查阅资料。
我想大家肯定还是非常好奇,为什么单通道的图片可以是彩色的。这里我简单的说两句,它其实是有一个调色板的,单通道的图片有0-255个灰度值,每一个灰度值就是一个索引,会在调色板中找到对应的颜色,下图展示了调色板中0-4的颜色,一共有0-255个。

看上图就非常好理解了,比如P模式某个像素灰度值为0,则它会在调色板中找0对应的颜色,即[0, 0, 0],为黑色,即P模式下所有灰度值为0像素颜色都是黑色。需要注意的是调色板中的不同索引对应的颜色是可以修改的,如我们将灰度值0的调色板由[0, 0, 0]修改成[255,255,255],则现在P模式下所有灰度值为0像素颜色都为白色。🍑🍑🍑
如若文章对你有所帮助,那就🛴🛴🛴

深度学习语义分割网络介绍对比-FCN,SegNet,U-net DeconvNet
前言
在这里,先介绍几个概念,也是图像处理当中的最常见任务.
- 语义分割(semantic segmentation)
- 目标检测(object detection)
- 目标识别(object recognition)
- 实例分割(instance segmentation)
语义分割
首先需要了解一下什么是语义分割(semantic segmentation).
语义分割,简单来说就是给定一张图片,对图片中的每一个像素点进行分类
比如说下图,原始图片是一张街景图片,经过语义分割之后的图片就是一个包含若干种颜色的图片,其中每一种颜色都代表一类.

图像语义分割是AI领域中一个重要的分支,是机器视觉技术中关于图像理解的重要一环.
有几个比较容易混淆的概念,分别是目标检测(object detection),目标识别(object recognition),实例分割(instance segmentation),下面来一一介绍.
目标检测
目标检测,就是在一张图片中找到并用box标注出所有的目标.
注意,目标检测和目标识别不同之处在于,目标检测只有两类,目标和非目标.
如下图所示:

目标识别
目标识别,就是检测和用box标注出所有的物体,并标注类别.
如下图所示:

实例分割
实例分割,对图像中的每一个像素点进行分类,同种物体的不同实例也用不同的类标进行标注.
下图展示了语义分割和实例分割之间的区别:
中间是实例分割,右图是语义分割.

PASCAL VOC
PASCAL VOC是一个正在进行的,目标检测,目标识别,语义分割的挑战.
这里是它的主页,这里是leader board,很多公司和团队都参与了这个挑战,很多经典论文都是采用这个挑战的数据集和结果发表论文,包括RCNN,FCN等.
关于这个挑战,有兴趣的同学可以读一下这篇论文
FCN
FCN,全卷积神经网络,是目前做语义分割的最常用的网络.
Fully convolutional networks for semantic segmentation 是2015年发表在CVPR上的一片论文,提出了全卷积神经网络的概念,差点得了当前的最佳论文,没有评上的原因好像是有人质疑,全卷积并不是一个新的概念,因为全连接层也可以看作是卷积层,只不过卷积核是原图大小而已.
FCN与CNN
在一般的卷积神经网络中,一般结构都是前几层是卷积层加池化,最后跟2-3层的全连接层,输出分类结果,如下图所示:
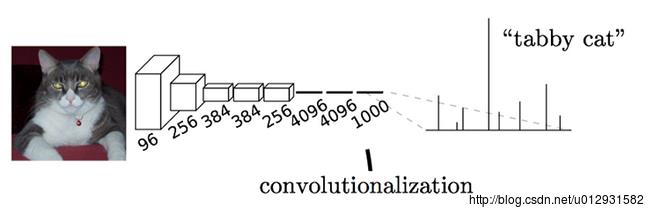
这个结构就是AlexNet的结构,用来进行ImageNet中的图片分类,最后一层是一个输出为1000*1向量的全连接层,因为一共有1000个类,向量中的每一维都代表了当前类的概率,其中tabby cat的概率是最大的.
而在全卷积神经网络中,没有了全连接层,取而代之的是卷积层,如下图所示:

最后一层输出的是1000个二维数组,其中每一个数组可以可视化成为一张图像,图中的每一个像素点的灰度值都是代表当前像素点属于该类的概率,比如在这1000张图像中,取出其中代表tabby cat的概率图,颜色从蓝到红,代表当前点属于该类的概率就越大.
可以看出FCN与CNN之间的区别就是把最后几层的全连接层换成了卷积层,这样做的好处就是能够进行dense prediction.
从而可是实现FCN对图像进行像素级的分类,从而解决了语义级别的图像分割(semantic segmentation)问题。与经典的CNN在卷积层之后使用全连接层得到固定长度的特征向量进行分类(全联接层+softmax输出)不同,FCN可以接受任意尺寸的输入图像,采用反卷积层对最后一个卷积层的feature map进行上采样, 使它恢复到输入图像相同的尺寸,从而可以对每个像素都产生了一个预测, 同时保留了原始输入图像中的空间信息, 最后在上采样的特征图上进行逐像素分类。

FCN语义分割
在进行语义分割的时候,需要解决的一个重要问题就是,如何把定位和分类这两个问题结合起来,毕竟语义分割就是进行逐个像素点的分类,就是把where和what两个问题结合在了一起进行解决.
在前面几层卷积层,分辨率比较高,像素点的定位比较准确,后面几层卷积层,分辨率比较低,像素点的分类比较准确,所以为了更加准确的分割,需要把前面高分辨率的特征和后面的低分辨率特征结合起来.
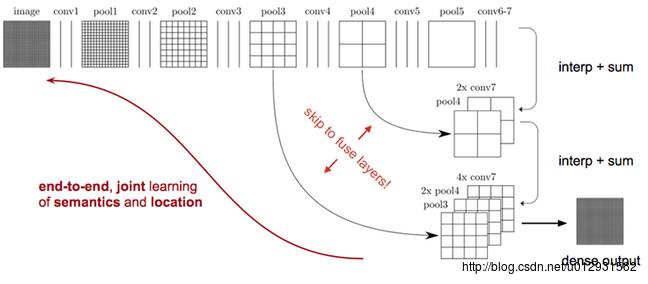
如上图所示,对原图像进行卷积conv1、pool1后原图像缩小为1/2;之后对图像进行第二次conv2、pool2后图像缩小为1/4;接着继续对图像进行第三次卷积操作conv3、pool3缩小为原图像的1/8,此时保留pool3的featureMap;接着继续对图像进行第四次卷积操作conv4、pool4,缩小为原图像的1/16,保留pool4的featureMap;最后对图像进行第五次卷积操作conv5、pool5,缩小为原图像的1/32,然后把原来CNN操作中的全连接变成卷积操作conv6、conv7,图像的featureMap数量改变但是图像大小依然为原图的1/32,此时进行32倍的上采样可以得到原图大小,这个时候得到的结果就是叫做FCN-32s.
这个时候可以看出,FCN-32s结果明显非常平滑,不精细. 针对这个问题,作者采用了combining what and where的方法,具体来说,就是在FCN-32s的基础上进行fine tuning,把pool4层和conv7的2倍上采样结果相加之后进行一个16倍的上采样,得到的结果是FCN-16s.
之后在FCN-16s的基础上进行fine tuning,把pool3层和2倍上采样的pool4层和4倍上采样的conv7层加起来,进行一个8倍的上采样,得到的结果就是FCN-8s.
可以看出结果明显是FCN-8s好于16s,好于32s的.

上图从左至右分别是原图,FCN-32s,FCN-16s,FCN-8s.
FCN的优点,能够end-to-end, pixels-to-pixels,而且相比于传统的基于cnn做分割的网络更加高效,因为避免了由于使用像素块而带来的重复存储和计算卷积的问题。
FCN的缺点也很明显,首先是训练比较麻烦,需要训练三次才能够得到FCN-8s,而且得到的结果还是不精细,对图像的细节不够敏感,这是因为在进行decode,也就是恢复原图像大小的过程时,输入上采样层的label map太稀疏,而且上采样过程就是一个简单的deconvolution.
其次是对各个像素进行分类,没有考虑到像素之间的关系.忽略了在通常的基于像素分类的分割方法中使用的空间规整步骤,缺乏空间一致性.
U-net
U-net 是基于FCN的一个语义分割网络,适合用来做医学图像的分割.
下面是U-net 的结构图:
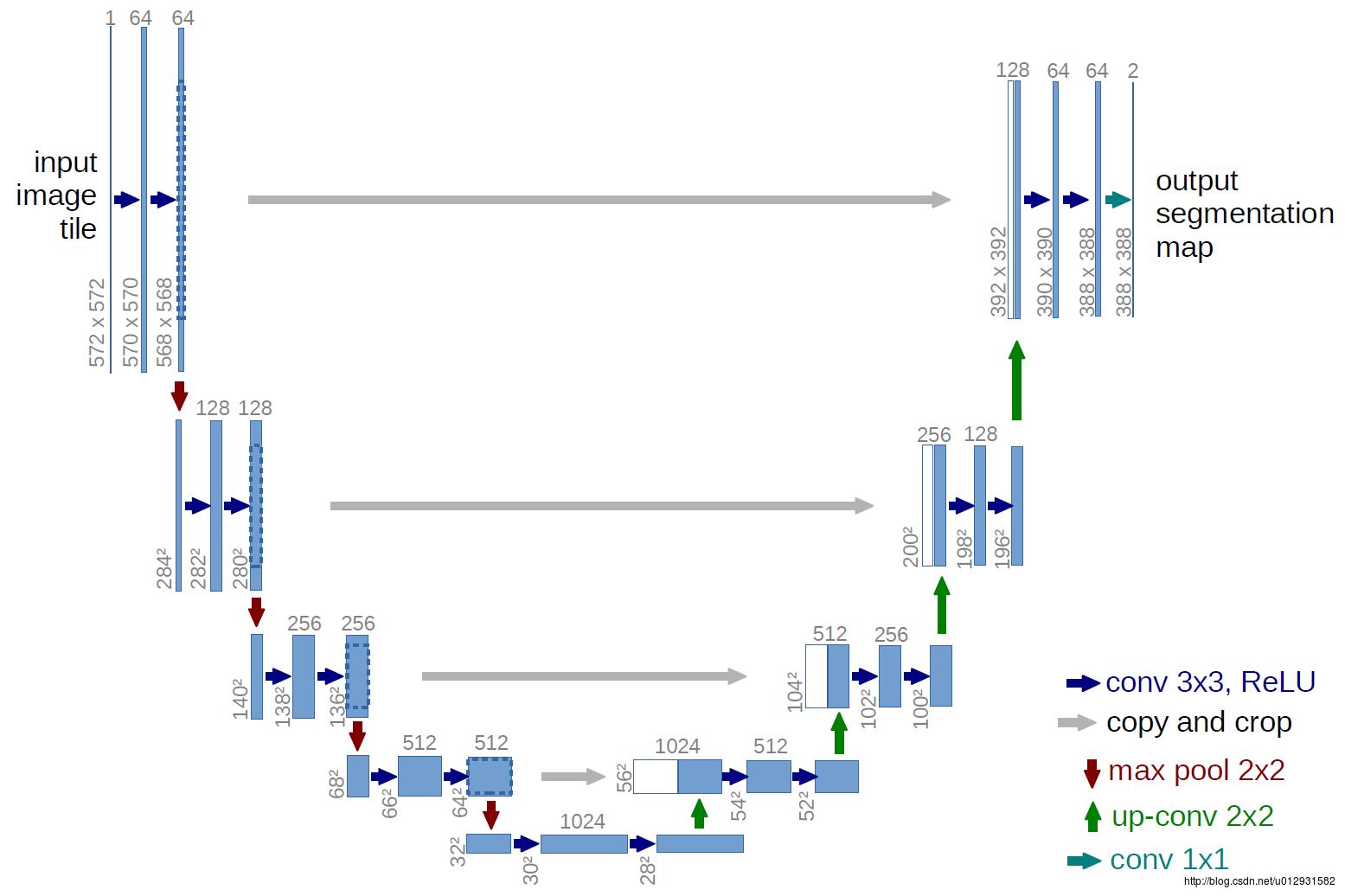
结构比较清晰,也很优雅,成一个U状.
和FCN相比,结构上比较大的改动在上采样阶段,上采样层也包括了很多层的特征.
还有一个比FCN好的地方在于,Unet只需要一次训练,FCN需要三次训练.
我实现了unet的网络结构,代码在: https://github.com/zhixuhao/unet,
是用keras实现的,关于数据集和训练测试,可以参考我这一篇博文: http://blog.csdn.net/u012931582/article/details/70215756
SegNet
SegNet 是一个encoder-decoder结构的卷积神经网络.
这里是官方网站:http://mi.eng.cam.ac.uk/projects/segnet/
SegNet 的结构如下所示:
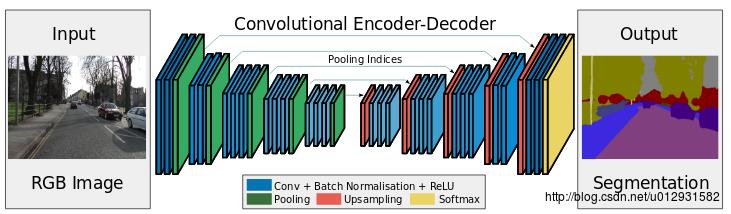
可以看出,整个结构就是一个encoder和一个decoder.前面的encoder就是采用的vgg-16的网络结构,而decoder和encoder基本上就是对称的结构.
SegNet和FCN最大的不同就在于decoder的upsampling方法,上图结构中,注意,前面encoder每一个pooling层都把pooling indices保存,并且传递到后面对称的upsampling层. 进行upsampling的过程具体如下:

左边是SegNet的upsampling过程,就是把feature map的值 abcd, 通过之前保存的max-pooling的坐标映射到新的feature map中,其他的位置置零.
右边是FCN的upsampling过程,就是把feature map, abcd进行一个反卷积,得到的新的feature map和之前对应的encoder feature map 相加.
实验
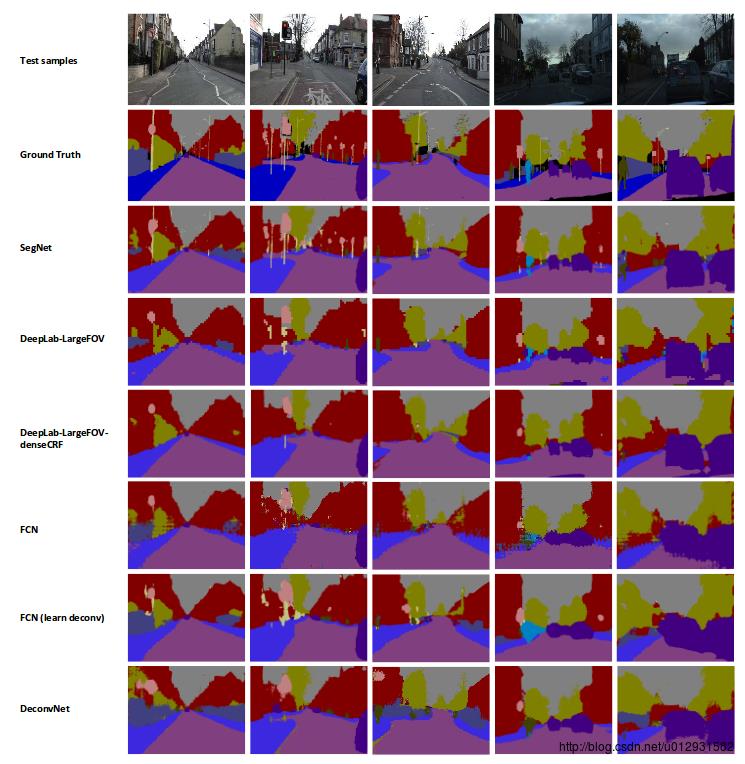
文章中说,他们用了CamVid 这个数据集进行了一下,这个数据集主要是街景图片,总共有11个类,367张训练图片,233张测试图片,是一个比较小的数据集.
下图是分割结果的对比:
DeconvNet
DeconvNet 是一个convolution-deconvolution结构的神经网络,和SegNet非常相似
是一篇2015年ICCV上的文章: Learning Deconvolution Network for Semantic Segmentation
下面是它的结构图:
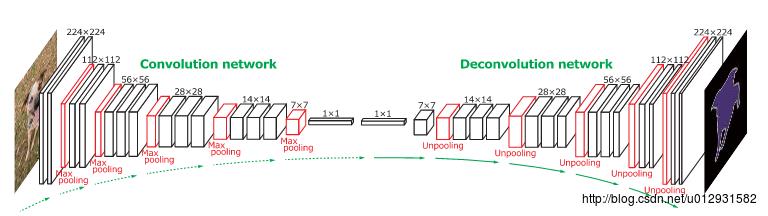
前面的convolution network 和SegNet的encoder部分是一样的,都是采用了VGG16的结构,只不过DeconvNet后面添加了两个全连接层.
在进行upsampling的时候,SegNet和DeconvNet基本上是一致的,都是进行了unpooling,就是需要根据之前pooling时的位置把feature map的值映射到新的feature map上,unpooling 之后需要接一个反卷积层.
总结
可以看出,这些网络的结构都是非常相似的,都是基于encoder-decoder结构的,只不过说法不同,前面是一些卷积层,加上池化层,后面的decoder其实就是进行upsampling,这些网络的最主要区别就是upsampling的不同.
FCN进行upsampling的方法就是对feature map进行反卷积,然后和高分辨率层的feature map相加.
Unet进行upsampling的方法和FCN一样.
DeconvNet进行upsampling的方法就是进行unpooling,就是需要根据之前pooling时的位置把feature map的值映射到新的feature map上,unpooling 之后需要接一个反卷积层.
SegNet进行upsampling的方法和DeconvNet一样.
以上是关于深度学习语义分割篇——FCN原理详解篇的主要内容,如果未能解决你的问题,请参考以下文章
深度学习语义分割网络介绍对比-FCN,SegNet,U-net DeconvNet
深度学习核心技术精讲100篇(五十八)- 如何量化医学图像分割中的置信度?