论文笔记 & R 笔记:imputeTS: Time Series Missing ValueImputation in R
Posted UQI-LIUWJ
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了论文笔记 & R 笔记:imputeTS: Time Series Missing ValueImputation in R相关的知识,希望对你有一定的参考价值。
0 摘要
imputeTS 包专门研究单变量时间序列插补。它提供了多种最先进的插补算法实现以及用于时间序列缺失数据统计的绘图函数。虽然插补通常是一个众所周知的问题,并且被 R 包广泛覆盖,但找到能够填补单变量时间序列中缺失值的包更加复杂。其原因在于,大多数插补算法依赖于属性间相关性,而单变量时间序列插补则需要使用时间依赖性。本文介绍了 imputeTS 包及其提供的算法和工具。此外,它简要概述了 R 中的单变量时间序列插补。
1 introduction
从工业 (Billinton et al., 1996) 到生物学 (Bar-Joseph et al., 2003)、金融 (Taylor, 2007) 到社会科学 (Gottman, 1981),几乎每个领域都测量了不同的时间序列数据。虽然记录的数据集本身可能不同,但一个常见问题是缺失值。许多分析方法需要预先用合理的值替换缺失值。在统计学中,这种替换缺失值的过程称为插补(imputation)。
因此,时间序列插补是插补研究领域的一个特殊子领域。最流行的技术,如多重插补 (Rubin, 1987)、期望最大化 (Dempster et al., 1977)、最近邻 (Vacek 和 Ashikaga, 1980) 和 Hot Deck (Ford, 1983) 依赖于属性间相关性来估计值对于缺失的数据。由于单变量时间序列不具有多个属性,因此这些算法不能直接应用。有效的单变量时间序列插补算法需要使用时间间相关性。
在 CRAN 上有几个包解决了多变量数据的插补问题。最受欢迎和成熟的(除其他外)是 AMELIA,MICE、VIM和missMDA。然而,由于这些包是为多变量数据插补而设计的,因此它们不适用于单变量时间序列。
imputeTS是 CRAN 上唯一专门用于单变量时间序列插补并包含多种算法的软件包。尽管如此,还有一些其他的包包括插补函数作为其核心包功能的补充。最值得注意的是zoo和预测forecast。这两个软件包还提供了一些高级时间序列插补函数。 spacetime (Pebesma, 2012)、timeSeries (Rmetrics Core Team et al., 2015) 和 xts (Ryan and Ulrich, 2014) 包也应该提到,因为它们包含一些非常简单但快速的时间序列插补方法。有关 R 中可用时间序列插补包的更广泛概述,另请参见 (Moritz et al., 2015)。在本技术报告中,我们评估了 R 中几个单变量插补函数在不同时间序列上的性能。
本文的结构如下: Overview imputeTS package 概述了 imputeTS 包中包含的所有特性和功能。接下来是提供的不同功能的使用示例。本文以结论部分结束
2 Overview imputeTS package
imputeTS 包可以在 CRAN 上找到,它是一个易于使用的包,它为“单变量、等间距、数字时间序列”提供了多个实用程序。
单变量意味着随着时间的推移只有一个属性被观察到。这导致在时间上的连续点 t1, t2, t3, ... tn 上进行一系列单个观察 o1, o2, o3, ... on。
等间距意味着,连续数据点之间的时间增量相等,即 |t1 - t2| = |t2 - t3| = ... = |tn−1 - tn|。数字意味着观察是可测量的数量,可以描述为一个数字。
在本节的第一部分,给出了关于所有可用函数和数据集的一般概述。
3.1 general overview
如表 1 所示,除了几种插补算法实现之外,该软件包还包括绘图函数和数据集。插补算法可以分为相当简单但快速的方法(如均值插补),和需要更多计算时间的更高级算法,如结构模型上的卡尔曼平滑。【注:部分paper中的方法已经过时,见第四章】
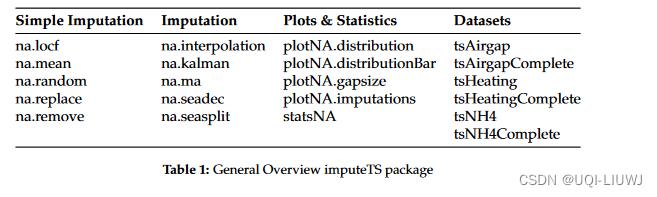
总体而言,该软件包旨在支持用户在时间序列中替换缺失值的完整过程。
此过程首先使用 statsNA 函数和 plotNA.distribution、plotNA.distributionBar、plotNA.gapsize 的图分析缺失值的分布。
在下一步中,可以使用几种算法选项之一进行实际插补。
最后,可以使用 plotNA.imputations 函数可视化插补结果。
此外,该软件包包含三个数据集,每个数据集都有一个有缺失值和没有缺失值的版本,可用于测试插补算法。
3.2 Plots & Statistics function
可以在表 2 中找到有关可用绘图和统计函数的概述。为

statsNA 函数计算输入数据的几个缺失数据统计。这包括缺失值的总体百分比、缺失值的绝对数量、数据不同部分的缺失值数量、最长的连续 NA 序列和连续 NA 的出现。
plotNA.distribution 函数可视化时间序列中 NA 的分布。这是使用标准时间序列图完成的,其中缺少数据的区域被涂成红色。这使用户能够第一眼看到大多数缺失值在序列中的位置。
plotNA.distributionBar 函数为用户提供了相同的见解,但设计用于非常大的时间序列。这对于具有 1000 个或更多观测值的时间序列是必要的,因为不可能将每个观测值绘制为单个点。
plotNA.gapsize 函数通过显示时间序列中最常见的 NA 间隙大小来提供有关连续 NA 的信息。
plotNA.imputations 函数被指定用于在应用插补算法后对结果进行目视检查。因此,新估算的观测值以与系列其余部分不同的颜色显示。
3.3 imputation functions
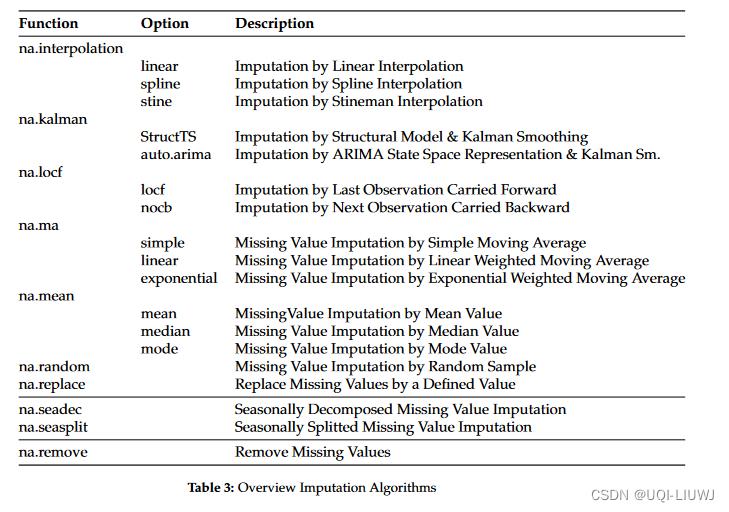
为方便起见,类似的算法可在一个函数名称下作为参数选项使用。例如linear、spline和 stine都包含在 na.interpolation 函数中。
na.mean、na.locf、na.replace、na.random 函数都很简单快速。相比之下,na.interpolation、na.kalman、na.ma、na.seasplit、na.seadec 是更高级的算法,需要更多的计算时间。
na.remove 函数是一种特殊情况,因为它只删除所有缺失值。因此,它并不是真正的插补函数。应该小心处理,因为删除观察可能会破坏序列的时间信息。
na.seasplit 和 na.seadec 函数也是例外。这些执行季节性拆分/分解操作作为预处理步骤。
纵观所有可用的插补方法,无法指出单一的总体最佳方法。插补性能总是非常依赖于输入时间序列的特征。即使用平均值进行插补有时也是一种合适的方法。
对于具有强烈季节性的时间序列,通常 na.kalman 和 na.seadec / na.seasplit 表现最好。
一般来说,对于大多数时间序列,na.kalman、na.interpolation 和 na.seadec 中的一种算法将产生最佳结果。
同时,对于大多数输入时间序列,na.random、na.mean、na.locf 将处于较低端的准确度。
3.4 Datasets
从表 4 中可以看出,所有三个数据集都有缺失数据的版本和完整版本。提供的时间序列被指定为单变量时间序列插补的基准数据集。它们使用户能够快速比较和测试插补算法。如果没有这些数据集,测试时间序列插补算法的过程将需要手动删除某些观察结果。
基准数据简化了这一点:插补算法可以直接应用于具有缺失值的数据集版本,然后可以与之后的完整数据集版本进行比较。
由于指定了时间序列,研究人员可以使用这些来将他们的算法与其他算法进行比较

在这些数据集上达到的 RMSE 或 MAPE 值是易于引用和比较的易于理解的结果。然而,使用这些固定数据集比较算法只能是衡量算法总体表现如何的第一个指标。特别是对于非常短的 tsAirgap 系列(只有 13 个 NA 值)随机幸运猜测会显着影响结果。一个完整的基准将包括:“不同的缺失数据百分比”、“不同的数据集”、“用于缺失数据模拟的不同随机种子”。
总体而言,tsAirgap 提供了一个相对较小的时间序列,tsNH4 提供了一个中等时间序列,tsHeating 提供了一个大时间序列。 tsHeating 和 tsNH4 都是传感器数据,而 tsAirgap 是计数数据
3.4.1 tsAirgap
tsAirgap 时间序列有 144 行,不完整版本包括 14 个 NA 值。它代表了从 1949 年到 1960 年的每月国际航空公司乘客总数,是时间序列分析文献中常用的例子。
最初称为“AirPassengers”或“airpass”,此版本重命名为“tsAirgap”,以提高与完整系列的区别(gap 表示引入了 NA)。
强趋势、强季节性行为使 tsAirgap 序列成为时间序列插补的一个很好的例子。
如前所述,为了使用该系列来比较插补算法结果,提供了两个时间系列。一个没有缺失值的系列(tsAirgapComplete),可用作ground truth。另一个带有 NA 的系列,可以在其上应用插补算法 (tsAirgap)。
3.4.2 tsNH4
tsNH4 时间序列有 4552 行,不完整版本包括 883 个 NA 值。它表示从 30.11.2010 - 16:10 到 01.01.2011 6:40 以 10 分钟为步长测量的废水系统中的 NH4 浓度。
如前所述,为了使用该序列来比较插补算法结果,提供了两个时间序列。一个没有缺失值的系列(tsNH4Complete),可用作ground truth。另一个带有 NAs (tsNH4) 的系列,可以应用插补算法。
请注意,由于时间序列有很多观察结果,一些更复杂的算法(如 na.kalman)需要一些时间才能完成。
3.4.3 tsHeating
tsHeating 时间序列有 606837 行,不完整版本包括 57391 个 NA 值。它表示从 18.11.2013 - 05:12:00 到 13.01.2015 15:08:00 以 1 分钟为单位测量的供暖系统的供应温度。
如前所述,为了使用该系列来比较插补算法结果,提供了两个时间系列。一个没有缺失值的系列 (tsHeatingComplete),可用作ground truth。另一个带有 NAs (tsHeating) 的系列,可以在其上应用插补算法。
请注意,由于它是一个非常大的时间序列,一些更复杂的算法(如 na.kalman)可能需要长达几天的时间才能在标准硬件上完成。
4 使用举例
要开始使用 imputeTS 包,请从 CRAN 安装稳定版本或从 GitHub (https://github.com/SteffenMoritz/imputeTS) 安装开发版本。特此推荐 CRAN 的稳定版本。
4.1 imputation algorithm
所有的插补算法都以相同的方式使用。输入必须是数字时间序列或数字向量。作为输出,将返回所有缺失值都被估算值替换的输入数据版本。这是一个小例子,展示如何使用插补算法。 (所有插补函数都以 na.'algorithm name' 开头)
为此,我们首先需要创建一个缺少数据的示例输入系列。
library(imputeTS)
x <- ts(c(1, 2, 3, 4, 5, 6, 7, 8, NA, NA, 11, 12))在这个时间序列上,我们可以应用不同的插补算法。我们从使用 na.mean 开始,它将 NA 替换为平均值。
na.mean(x) #Time Series: #Start = 1 #End = 12 #Frequency = 1 # [1] 1.0 2.0 3.0 4.0 5.0 6.0 7.0 8.0 5.9 5.9 11.0 12.0注:在后续的R版本中,将使用na_mean()而不是paper里面的na.mean()
大多数功能还具有提供更多算法(相同算法类别)的附加选项。在下面的示例中,可以看到 na.mean 也可以使用 option="median" 调用,它将 NA 替换为中位数。
na_mean(x,option='median') #Time Series: #Start = 1 #End = 12 #Frequency = 1 # [1] 1.0 2.0 3.0 4.0 5.0 6.0 7.0 8.0 5.5 5.5 11.0 12.0
虽然 na.interpolation 和所有其他插补函数的使用方式相同,但产生的结果可能不同。如下图所示,对于这个系列,线性插值给出了更合理的结果。
na_interpolation(x) #Time Series: #Start = 1 #End = 12 #Frequency = 1 # [1] 1 2 3 4 5 6 7 8 9 10 11 12
对于比本例中更长和更复杂的时间序列(具有趋势和季节性),尝试 na.kalman 和 na.seadec 总是一个好主意,因为这些函数通常会产生最佳结果。这些函数的调用方法与所有其他插补函数一样简单。
这是应用于 tsAirgap(在 2.2.4 中描述)时间序列的 na.kalman 函数的使用示例。从图 1 中可以看出,na.kalman 为这个系列提供了非常好的结果,其中包含强烈的季节性和强烈的趋势。【注意:paper中的示例已经过时】
imp<-na_kalman(tsAirgap) ggplot_na_imputations(tsAirgap,imp,tsAirgapComplete)
4.2 plotNA.distribution
此函数可视化时间序列中缺失值的分布。因此,绘制了时间序列,并且每当值为 NA 时,背景的颜色就会不同。这提供了一个很好的概述,在时间序列中大部分缺失值都出现在其中。【注:paper中的方法也已经失效】
ggplot_na_distribution(tsAirgap)
4.3 plotNA.distributionBar
此函数还可视化时间序列中缺失值的分布。这是作为条形图完成的,如果时间序列太大而无法绘制,这将特别有用。时间间隔的多个观测值被组合在一起并表示为条形。对于这些间隔,将显示有关缺失值数量的信息。【注:paper中的方法也已经过时】
ggplot_na_intervals(tsHeating,20)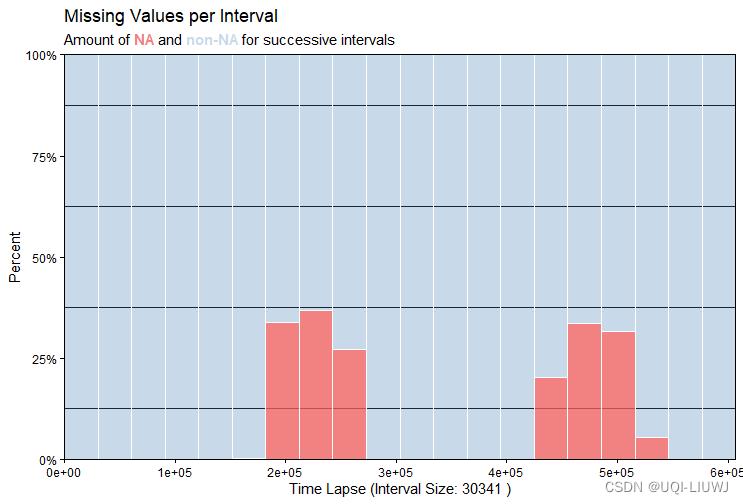
如图 3 的 x 轴所示,tsHeating 系列具有超过 600.000 个观测值,是一个非常大的时间序列。虽然 tsAirgap 系列中的缺失值(144 个观测值)可以使用 plotNA.distribution 可视化(即现在可使用的ggplot_na_distribution),但这肯定不适用于 tsHeating。绘图区域中没有足够的空间容纳 600.000 个连续的观察/点。
plotNA.distributionBar 函数解决了这个问题(即现在的ggplot_na_intervals)。多个观测值按间隔分组在一起。示例中的参数定义应该使用 20 个间隔。这意味着图 3 中的每个区间代表大约 30.000 个观测值。前五个间隔是完全蓝色的,这意味着不存在缺失值。这意味着从观察 1 到观察 150.000,数据中没有缺失值。在系列的中间和结尾有几个区间,每个区间都有大约 40% 的缺失数据。这意味着在这些间隔中,30.000 次观察中有 12.000 次是 NA。总而言之,该图能够很好但粗略地概述非常大的时间序列中的 NA 分布
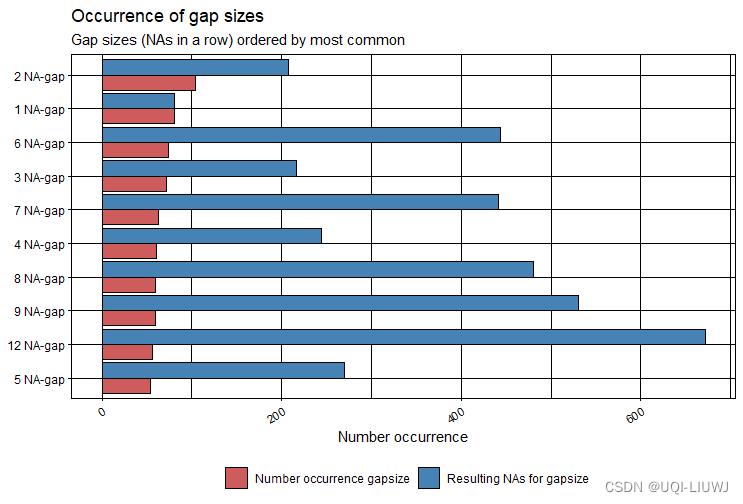
4.4 plotNA.gapsize
此绘图函数可用于可视化不同 NA 间隙(一行中的 NA)在时间序列中出现的频率。该函数将此信息显示为排名。此排名可以按占总 NA 的间隙大小(数量出现间隙大小 * 间隙长度)或仅按间隙大小的出现次数排序。【注:paper方法已过时】
ggplot_na_gapsize(tsHeating)
4.5 plot NA.imputations
该图可用于可视化时间序列的估算值。估算值(填充的 NA 空白)以与其他值不同的颜色显示。
【注意:paper中的示例已经过时】
imp<-na_kalman(tsAirgap)
ggplot_na_imputations(tsAirgap,imp,tsAirgapComplete) 
4.6 statsNA
statsNA 函数打印有关单变量时间序列中缺失值分布的汇总统计信息。以下是关于它提供的信息的简短说明:
• 时间序列的长度 时间序列中的观察数量(包括 NA)
• 缺失值的数量 时间序列中缺失值的数量
• 缺失值的百分比 缺失值的百分比时间序列
• 分箱的统计数据 拆分成箱的缺失值的数量/百分比
• 最长的 NA 间隙 时间序列中最长的连续缺失值系列(一行中的 NA)
• 最频繁的间隙大小 最频繁出现的缺失值系列在时间序列中
• 占大多数 NA 的间隙大小 占时间序列中总体缺失值最多的连续缺失值系列
• 概览 NA 系列 概览每个连续缺失值系列出现的频率
statsNA(tsAirgap)
''
[1] "Length of time series:"
[1] 144
[1] "-------------------------"
[1] "Number of Missing Values:"
[1] 13
[1] "-------------------------"
[1] "Percentage of Missing Values:"
[1] "9.03%"
[1] "-------------------------"
[1] "Number of Gaps:"
[1] 11
[1] "-------------------------"
[1] "Average Gap Size:"
[1] 1.181818
[1] "-------------------------"
[1] "Stats for Bins"
[1] " Bin 1 (36 values from 1 to 36) : 4 NAs (11.1%)"
[1] " Bin 2 (36 values from 37 to 72) : 1 NAs (2.78%)"
[1] " Bin 3 (36 values from 73 to 108) : 5 NAs (13.9%)"
[1] " Bin 4 (36 values from 109 to 144) : 3 NAs (8.33%)"
[1] "-------------------------"
[1] "Longest NA gap (series of consecutive NAs)"
[1] "3 in a row"
[1] "-------------------------"
[1] "Most frequent gap size (series of consecutive NA series)"
[1] "1 NA in a row (occurring 10 times)"
[1] "-------------------------"
[1] "Gap size accounting for most NAs"
[1] "1 NA in a row (occurring 10 times, making up for overall 10 NAs)"
[1] "-------------------------"
[1] "Overview NA series"
[1] " 1 NA in a row: 10 times"
[1] " 3 NA in a row: 1 times"
''4.7 结论
数据缺失是各种数据中非常常见的问题。但是,在单变量时间序列的情况下,大多数标准算法和 R 包中的现有函数都不能应用。
本文介绍了 imputeTS 包,它提供了一组专门针对此任务量身定制的算法和工具。使用示例时间序列,我们说明了所提供函数的易用性和优势。简单的算法以及更复杂的算法都可以以同样简单和用户友好的方式应用。提供的功能使 imputeTS 包成为在需要完全没有缺失值的进一步分析步骤之前对时间序列进行预处理的不错选择。即将推出的软件包版本的未来研发计划包括添加额外的时间序列算法选项以供选择
以上是关于论文笔记 & R 笔记:imputeTS: Time Series Missing ValueImputation in R的主要内容,如果未能解决你的问题,请参考以下文章
论文阅读笔记 | 目标检测算法——Libra R-CNN算法
安卓zoo for zotero && WebDAV 自动同步论文笔记
《Sparse R-CNN:End-to-End Object Detection with Learnable Proposals》论文笔记
论文笔记之:DeepCAMP: Deep Convolutional Action & Attribute Mid-Level Patterns