Grid R-CNN 算法笔记
Posted AI之路
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Grid R-CNN 算法笔记相关的知识,希望对你有一定的参考价值。
论文:Grid R-CNN
论文链接:https://arxiv.org/abs/1811.12030
代码链接:https://github.com/STVIR/Grid-R-CNN
代码链接2:https://github.com/open-mmlab/mmdetection
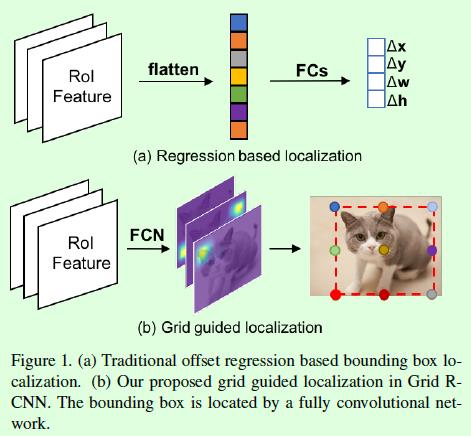
这篇目标检测论文发表在CVPR2019,整体上是将two-stage类型的目标检测算法中的位置回归支路用基于关键点检测的支路来代替从而取得更好的实验结果,如图Figure1所示。比较有吸引力的点自然就是基于关键点检测,论文发表的背景正好是CornerNet提出没多久的时候,CornerNet将关键点预测引入目标检测算法从而实现在没有anchor的情况下准确预测目标框位置的目标,但是Grid RCNN还是基于anchor来实现的,因此算是比较有特点的算法。
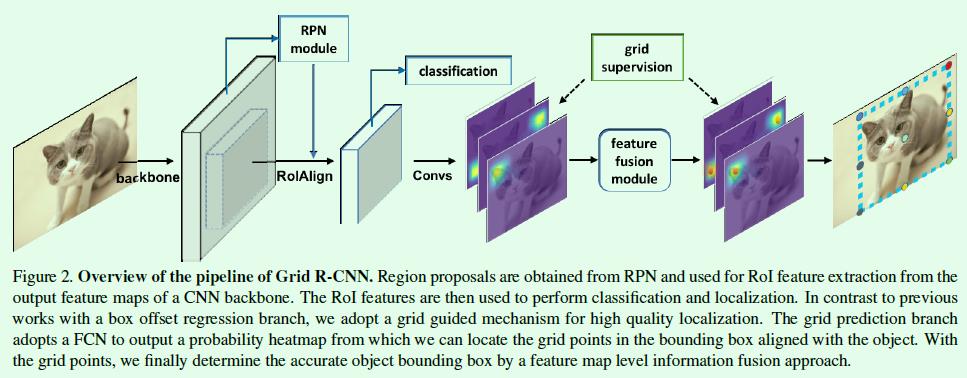
显然,Grid RCNN是基于anchor的two-stage算法,RPN部分的训练和Faster RCNN一样,但是检测部分采用基于关键点的预测来确定目标框的位置,因此很像是结合了Faster RCNN和CornerNet的产物,网络的整体框架如Figure2所示。和CornerNet中采用两个关键点不同,Grid RCNN采用了更多的预测点(默认是9个关键点),这是为了避免单个预测点预测不准带来的效果下降,反正不会对速度造成太大的影响,所以能利用更多的信息当然更好。
Grid RCNN的主体部分还是和Faster RCNN类似,只不过RoI Pooling用精度更高的RoI Align代替,RoI Align后得到的特征图尺寸设计为14×14。分类支路和Faster RCNN算法是一致的,但是关键点预测支路(grid branch)稍有不同。关键点支路包含dilated卷积层和反卷积层,最后得到9组heatmap,大小是56×56,也就是进行了2次上采样,个人认为这样做其实是和关键点的准确预测密切相关的,没有这样的上采样操作,出来的关键点位置误差会比较大,毕竟网络没有设计误差回归支路,因此这部分信息丢失了就很难弥补回来。
另外,因为回归操作变成了基于heatmap的每个点的分类操作,因此损失函数也相应修改成了二值交叉熵损失函数,用来判断heatmap上每个点的正负类别。
联想CornerNet,除了预测关键点外,还需要一个分支用来判断哪些关键点是属于同一个目标框的,但是Grid R-CNN不需要这个过程,因为Grid R-CNN是基于RoI来做的,每个RoI只和一个目标框关联,所以不需要判断。
预测框的坐标点最终都要映射到输入图像上才能得到最终的预测框位置,这部分可以通过公式1计算得到,主要是坐标映射和偏移计算。Px和Py表示RoI的左上角点在输入图像中的坐标位置,wo表示预测特征图的大小(默认是56),wp表示RoI的大小(默认是14),因此加号右边的式子是将56×56特征图上的坐标值映射到14×14特征图上的操作,最终加上相对原图的偏移量Px或Py就得到最终的结果。其实这里的坐标映射还是存在误差的(相加后得到的基本上都不是整数,因此会有取整操作),这部分偏差如果可以通过一个分支进行回归(类似anchor-free的目标检测算法那样做),也许预测效果会更好。
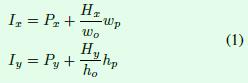
在inference阶段,得到heatmap后关于9个关键点的确定比较直接:每个heatmap中概率最大的那个点就是预测的关键点位置,因此9个heatmap就可以得到9个关键点。再接下来就是关于如何基于这9个关键点确定预测框的位置,这部分通过公式2介绍得非常清楚,简单而言就是通过指定点的加权求和得到预测框的边界信息。公式2中的xl、yu、xr和yb分别表示预测框的左上角点坐标和右下角点坐标,pj表示第j个关键点(grid point)的概率值(也就是用概率值来表示权重),(xj, yj)表示第j个关键点的坐标,E1到E4表示预测框的4条边所包含的关键点。举个例子:左上角点的横坐标xl可以通过预测框左边边框的3个关键点的横坐标通过各自的概率加权计算得到。
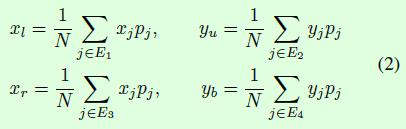
到此,Grid RCNN的主体思想基本上介绍完了,除此之外,Grid RCNN还包含了2个优化点用于提高模型效果。
第一个优化点是关于特征融合的(grid points feature fusion),特征融合是为了使得每个heatmap都能包含更多的特征信息。从前面的介绍和Figure2的网络结构图可以看出输出的heatmap数量默认是9个,当我们要对第一个heatmap做特征融合操作时,就将剩下8个heatmap中的某几个经过变换后添加到第一个heatmap上得到融合后的heatmap,如公式3所示,Fi表示第i个heatmap,也就是待融合的对象,Tj->i表示变换操作(文中是由一些卷积层构成的),Si表示用来融合的heatmap集合,融合操作采用相加计算得到,因此重点就变成了Si的选择了。
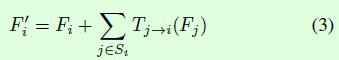
在这篇文章中,特征融合时选择的heatmap是基于对应Grid之间的距离来定的,也就是Si集合,融合操作包含2个阶段。第一阶段的融合设置的Grid距离是1,如Figure3左图所示,假设Fi是左上角点对应的heatmap,那么此时Si就包含2个grid(紫色箭头对应的2个起始点)对应的heatmap。第二阶段的融合设置的Grid距离是2,如Figure3右图所示,这一阶段将融合3个grid(紫色箭头对应的3个起始点)对应的heatmap。最终左上角点对应的heatmap将融合5种heatmap(每种heatmap可能融合不止一次)的变换结果得到最终的heatmap,其他8个关键点对应的heatmap融合也是类似。
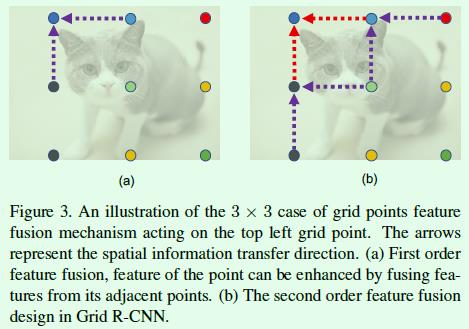
特征融合的实验结果可以看Table2,效果上有一些提升。
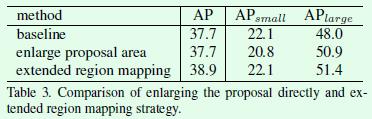
第二个优化点是关于区域映射的(extended region mapping)。我们知道在two-stage算法中第一阶段的目的是得到RoI,然后第二阶段关于目标框的预测将基于第一阶段得到的RoI特征进行,因此就有可能出现Figure4这种情况,也就是真实框(绿色实线框)的部分关键点(7个关键点)在RoI区域(白色实线框)外面,这显然丢失了很多监督信息,难以充分利用数据。
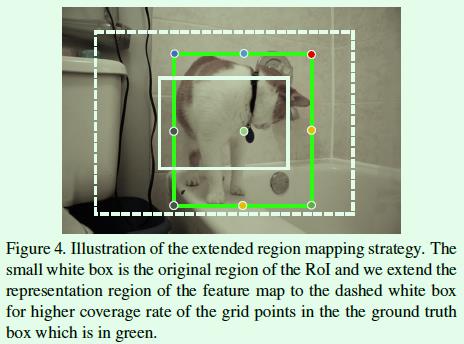
解决这个问题的直接想法是扩大RoI区域并基于扩大后的区域提取RoI特征,但是作者通过实验发现直接扩大RoI的区域不会对最终的效果有提升,于是作者提出了extended region mapping操作,该操作不修改RoI特征,而是将RoI映射后的长宽修改为原来的2倍,也就是Figure4中白色实线框映射为白色虚线框,计算监督信息时是基于白色虚线框,而不是白色实线框。
举个例子,当我们要计算Figure4中白色RoI的监督信息时,是通过计算绿色标注框的9个关键点在白色虚线框内的相对位置实现的,假如绿色标注框的左上角关键点坐标是(300,100),白色虚线框的左上角点坐标是(90, 40),白色虚线框的宽和高分别是(600, 500),那么int((300-90)/600×56)=19,int((100-40)/500×56)=6,也就是说在56×56大小的监督矩阵上,坐标(19, 6)就对应标注框左上角关键点,该点的监督信息就是1,当然实际操作中会将真值点周围一定半径内的点都设置为真值点,也就是论文中提到的5个像素点的由来。假如没有extended region mapping这个过程,那么Figure4中标注框只有2个关键点有监督信息,其他都为0,这样显然是不利于训练的。
对比实验如Table3所示,这里要注意的是直接扩大RoI的面积做预测对尺寸较大的目标还是有所帮助的,但是对于尺寸较小的目标指标下降比较明显,原因基本上就是引入的噪声导致的,而extended region mapping的提升是显而易见的。个人感觉extended region mapping的引入更像是为了解决anchor类型算法带来的必须要解决的问题(基于RoI特征进行预测,而不是全局特征)。其次,extended region mapping的做法就像是:基于关键点部分缺失的特征学习到的heatmap,被强制告诉这个heatmap上存在所有的关键点,学习起来难免有些牵强,相比之下,直接扩大RoI进行特征提取显得更加理所当然,所以这部分也许还有更优雅的解决方案。
实验结果:
Grid RCNN的实验结果还是很棒的,基本上比Mask RCNN的指标还有高一些,而Mask RCNN还利用了目标的分割信息。
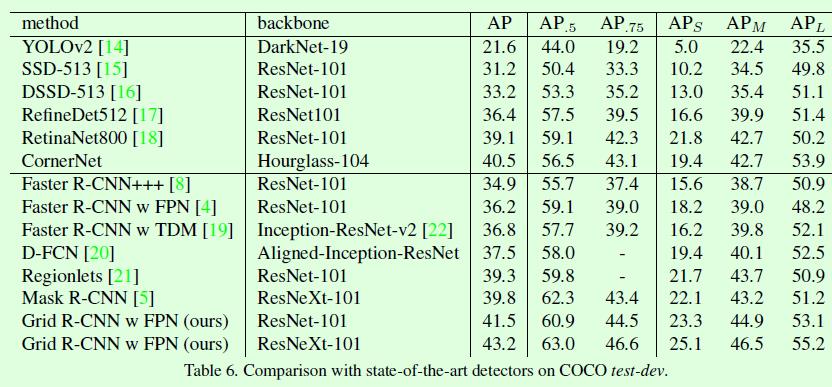
Table7的这个实验比较有意思,作者列举了Grid RCNN算法和Faster RCNN算法对比时,指标提高或降低最多的15个类别,可以看到指标提高较多的类别目标多数具有明显的矩形外形,这样关键点落到目标上的数量就比较多,关键点预测也就比较准。相反,指标降低最多的类别目标多数是圆形或其他不规则图形,这样关键点落在目标上的数量就比较少,关键点预测就不那么准了,这也符合grid的设定。

以上是关于Grid R-CNN 算法笔记的主要内容,如果未能解决你的问题,请参考以下文章