谈谈如何设计好网站的URL
Posted 程序员大咖
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了谈谈如何设计好网站的URL相关的知识,希望对你有一定的参考价值。
👇👇关注后回复 “进群” ,拉你进程序员交流群👇👇
URL设计,这是一个非常重要但是往往容易给忽略的部分,也比较少架构师会去关注或者重视。在整个系统架构中,有时候一个好的URL设计对整个系统会起到一个好的作用。
URI和URL及URN
URL大家都比较熟悉,其他两个词就比较陌生了。URI、URL和URN是识别、定位和命名互联网上的资源的标准途径。1989年Tim Berners-Lee发明了互联网(World Wide Web)。WWW被认为是全球互连的实际的和抽象的资源的集合–它按需求提供信息实体–通过互联网访问。实际的资源的范围从文件到人,抽象的资源包括数据库查询。
因为要通过多样的方式识别资源(人的名字可能相同,然而计算机文件只能通过唯一的路径名称组合访问),所以需要标准的识别WWW资源的途径。为了满足这种需要,Tim Berners-Lee引入了标准的识别、定位和命名的途径:URI、URL和URN。
URI:Uniform Resource Identifier,统一资源标识符
URL:Uniform Resource Locator,统一资源定位符
URN:Uniform Resource Name,统一资源名称
在这个体系中的URI、URL和URN是彼此关联的。URI的范畴位于体系的顶层,URL和URN的范畴位于体系的底层。这种排列显示URL和URN都是URI的子范畴。
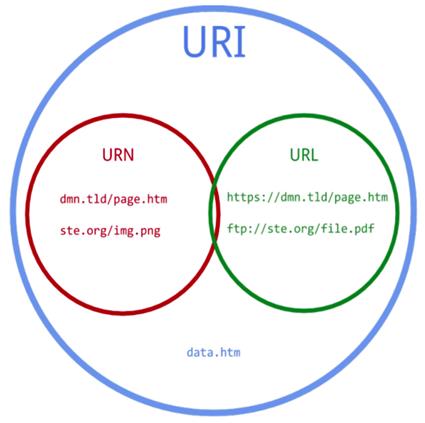
URI可被视为定位符(URL),名称(URN)或两者兼备。统一资源名(URN)如同一个人的名称,而统一资源定位符(URL)代表一个人的住址。换言之,URN定义某事物的身份,而URL提供查找该事物的方法。
用于标志唯一书目的ISBN系统是一个典型的URN使用范例。例如,ISBN 0-486-27557-4无二义性地标志出莎士比亚的戏剧《罗密欧与朱丽叶》的某一特定版本。为获得该资源并阅读该书,人们需要它的位置,也就是一个URL地址。在类Unix操作系统中,一个典型的URL地址可能是一个文件目录,例如file:///home/username/RomeoAndJuliet.pdf。该URL标志出存储于本地硬盘中的电子书文件。因此,URL和URN有着互补的作用。
URL
URL是Internet上用来描述信息资源的字符串,主要用在各种WWW客户程序和服务器程序上。采用URL可以用一种统一的格式来描述各种信息资源,包括文件、服务器的地址和目录等。
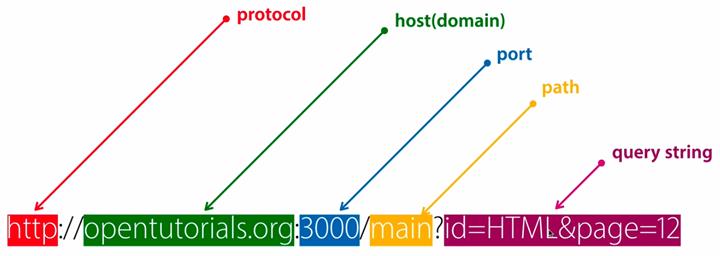
URL的格式由下列三部分组成:
协议(或称为服务方式)
存有该资源的主机IP地址(有时也包括端口号)
主机资源的具体地址。如目录和文件名等
第一部分和第二部分之间用”://”符号隔开,第二部分和第三部分用”/”符号隔开。第一部分和第二部分是不可缺少的,第三部分有时可以省略。
目前最大的缺点是当信息资源的存放地点发生变化时,必须对URL作相应的改变。因此人们正在研究新的信息资源表示方法。
URN
URN(统一资源名称)是标准格式的URI,指的是资源而不指定其位置或是否存在。这个例子来自RFC3986:urn:oasis:names:specification:docbook:dtd:xml:4.1.2
URN与URL之间仍存在重大区别:
URN对一项资源予以持久性的识别。
URL主要为资源标识路径。路径可能随着时间的推移发生改变,原因有二:首先,可于特定URL获取的资源可能发生改变(互联网上的内容变更非常频繁)。另外,资源可能被移至其它定位,也可能同时出现在多个定位。因此,URL往往并不具有唯一性或持久性。
因此,URL与URN的设计相似,宗旨不同。
URN的设计旨在确保与现行标准标识符系统(例如ISSN或任何其它新标准系统)具有互操作性。因此,URN拥有与标识符系统挂钩的命名空间,有别于其它持久性标识符系统(例如DOI前缀并不代表任何标识符系统,而是指明提供标识符的相关组织) 。URL与URI则完全不考虑传统标识符系统。因此,一项期刊的URN基于其ISSN号,URN:ISSN 命名空间则适用ISSN相关规则。相反的,期刊主页的URL往往与ISSN号无关。
URN的结构
URN采用URI语法。
URN:NID:NSS
因此,URN至少包括三个部分:
URN:URN首先标注URN方案Scheme
NID:于IANA(互联网号码分配机构)注册的命名空间标识符
NSS:NSS(命名空间特定字符串)予以精确标识
ISSN与URN
ISSN是最早接受URN方案的书目标识符,以期通过标准方式在互联网上进行使用和表达。每一个ISSN号都可根据以下语法以URN形式予以表达:
URN:ISSN:xxxx-xxxx
urn:issn:xxxx-xxxx
UrN:IsSn:xxxx-xxxx
xxxx-xxxx即转化为URN的ISSN号,例如:urn:issn:1234-1231
建议将URN:ISSN记录于可获取的网络资源(例如在线发布的报刊等)的嵌入元数据中。以html文件为例,URN:ISSN应录入于HEAD部分:
META NAME="Identifier" SCHEME="URN:ISSN" CONTENT="1234-1231"
URI
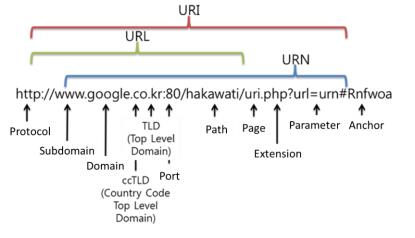
URI是以某种统一的(标准化的)方式标识资源的简单字符串,一般由三部分组成:
访问资源的命名机制
存放资源的主机名
资源自身的名称,由路径表示
统一资源标志符URI就是在某一规则下能把一个资源独一无二地标识出来。URL是URI的子集。
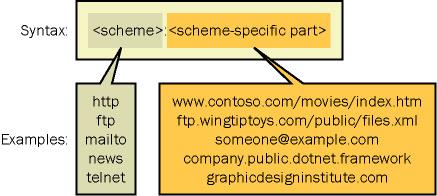
典型情况下,这种字符串以scheme开头,语法如下:
有的URI指向一个资源的内部。这种URI以”#”结束,并跟着一个anchor标志符(称为片断标志符)。
相对URI不包含任何命名规范信息。它的路径通常指同一台机器上的资源。相对URI可能含有相对路径(如:“..”表示上一层路径),还可以包含片断标志符。
URI的常见问题
难以输入,URI不必要的冗长
莫明其妙的大写字母
不常见的标点符号
在纸介质上显示很困难,一些字符在纸上打印出来不容易辨认
主机和端口的问题除了scheme-specific部分,domain和port也可能给用户带来困惑。
不成熟的技术:Data URI
Data URI是由RFC 2397定义的一种把小文件直接嵌入文档的方案。通过如下语法就可以把小文件变成指定编码直接嵌入到页面中:
data:[<MIME-type>][;base64],<data>
MIME-type:指定嵌入数据的MIME。其形式是[type]/[subtype]; parameter,比如png图片对应的MIME是image/png。parameter可以用來指定附加的信息,更多情況下是用于指定text/plain和text/htm等的文字编码方式的charset参数。默认是text/plain;charset=US-ASCII。
base64:声明后面的数据的编码是base64的,否则数据必须要用百分号编码(即对内容进行urlencode)。
Data URI的优点:
减少HTTP请求数,没有了TCP连接消耗和同一域名下浏览器的并发数限制。
对于小文件会降低带宽。虽然编码后数据量会增加,但是却减少了http头,当http头的数据量大于文件编码的增量,那么就会降低带宽。
对于HTTPS站点,HTTPS和HTTP混用会有安全提示,而HTTPS相对于HTTP来讲开销要大更多,所以Data URI在这方面的优势更明显。
可以把整个多媒体页面保存为一个文件。
Data URI的缺点:
无法被重复利用,同一个文档应用多次同一个内容,则需要重复多次,数据量大量增加,增加了下载时间。
无法被独自缓存,所以其包含文档重新加载时,它也要重新加载。
客户端需要重新解码和显示,增加了点消耗。不支持数据压缩,base64编码会增加1/3大小,而urlencode后数据量会增加更多。
不利于安全软件的过滤,同时也存在一定的安全隐患。
转换工具:Data URI Generator
优秀的URI不会改变
什么样的URI称得上优秀的URI?优秀的URI就是不需要改变的URI。是什么迫使URI做出改变?不改变的是URI:改变的是人。理论上人们没有什么原因去改变URI,但是在实际运行中却存在着成百上千的原因。从理论上讲,域名的所有者拥有该域名下的所有URI。理论上您域名下的所有URI是完全由您控制的,所以你是可以按照自己喜欢的方式使URI变得稳定。迫使一个文件地址消失的原因是域名过期或服务器没有在继续运行。这就是为了会有这么多改来改去的链接。其中的一部分是由于缺乏远见导致的。下面是您可以听到的一些原因。
为了使网站更好,我们刚改版了网站。
我们有大量过期的、保密的、无效的文档需要进行区分。
我们发现不得不移动文件。
我们曾经使用的是一个CGI脚本,现在我们使用的是一个二进制程序。
我不认为URI是需要持久的,需要持久的那是URN。
当你在服务器上修改了URI,你不会知道还有多少人会使用旧的URI。他们可能把你的链接发布到了其他网站上,他们可能把你的链接存为了书签。他们可能把你的URI告诉了别人。当一些人点击链接,但是发现链接无法打开的时候,他们就会对网站拥有者失去信心。他们会因为不能完成自己想要的目标而沮丧。
我该怎么去设计URI?
使一个URI可以持续2年、20年、200年,这是一个网站管理员的责任。这需要思想、组织和承诺。一般来说URI改变时因为文档里的一些信息发生了改变,这和URI的设计至关重要的。文件的创建日期这是不会改变的。这对分离旧的系统和新的系统非常有用。这能很好的让你开始设计一个URI。即使这个文件会被多次修改,但是他还是只会有一个创建日期。唯一例外的是一个网页是故意“最新”的,例如频道的首页。
http://www.example.com/money/moneydaily/latest/
此URI不需要日期的主要原因是此页面时不断更新的,如果你需要者页面的存档,存档地址可以是
http://www.example.com/money/moneydaily/1998/981212.moneyonline.html
(这个URI看上去不错,除了”98″和“.html”有些多余)
哪些信息需要被抛弃?
在使用日期以后,把任何信息放入URI都有可能带来问题。
作者的名字:著作权可能会因为版本的修改而改变,比如团队里的某些人离开使事务被转手。
标题:这个是非常棘手的,他总是现在看起来非常合适,但是过些时间久需要改变。
状态:如”old”,”new”,”latest”等,文件很可能会改变状态。
访问权限:一个文件的访问权限可能会因为情况而改变,不要将文档放在”public”、”team”下。
文件扩展名:即使是”.html”也有可能会改变。
程序机制:如”cgi”和”exec”
磁盘名称:这个也有用使用的!
按文章主题进行分类
这是非常危险的操作。通常情况下,你URI中的文档分类是按你正在进行的工作进行区分的。这就可能带来隐患,你从事的领域可能会在今后发生变化。在W3C,我们期望吧“MarkUp”修改为“Markup”,后来又期望修改为“HTML”,我们不能保证现在的命名在以后是否适用。
按主题分类这是一个非常理想的分类方案,包括把整个互联网进行分类一样,这是一个非常不错的解决办法,但是从长远看存在着严重的缺陷。每个人对语言中的每个聚类的主题词都有不同的理解,网络之间的主题关系,并不是像树型那么简单。事实上,当你在你的URI中绑定分类时,未来你很有可能去改变这个分类,到时候URI就需要跟随着改变。
在URI中使用主题进行分类的一个原因是你需要一个名称作为URI的一个部分来组织内容,比如内容细分,通常来说在日期存在(日期在左边)的情况下还是非常安全的,1998/pics可以理解为,我们在1998年的照片。而不是照片中1998年我们在做什么。
不要忘记你的域名
请记住,这不仅适用于URI“路径”,同时也使用与服务器名称。在域名中无论代表公司,或文件状态,或访问级别,或者安全级别划分,要非常非常小心,特别是在使用多个域名访问一个文件的时候,不要忘记,你可以在服务器端使用重定向。
URL即UI
尽管APP和小程序在替代WEB网站。但WEB网站最终难以被完全替代。未来的很多年,URL还将成为用户界面的一部分。所以一个可用性好的网站需要:
一个容易记忆及拼写的域名
简短的URL网址
容易输入的URL
可视化的URL结构
用户可以删除URL最后的一层到达上级目录
URL保持不变
用户不需要像服务器一样了解每个URL,事实上更多的人是通过大概的印象访问网站的:
很多人会在没有访问网站前猜测网站的域名,所以你最好使用公司名称或品牌作为域名
更多的人更喜欢记住网站名而不是将网站添加到书签,所以最好注册一个易于拼写的域名
在用户将你的URL通过邮件告知别人时,保证你的URL要少于78个字符,因为如果URL过程可能会造成换行
如果很多人通过输入那么最好使用简短的URL
不要再URL中大下写混用,因为很多人会忽视大小写,但是部分服务器不会
在服务器上进行拼写检查来减少由于拼写错误造成的问题
来自第三网站的外链对流量很重要,所以在生成你的URL的时候要考虑到易于传播。
保证所有的URL都是持续可以访问的,且链向的页面不做改变。
不要把文件的URL改来改去, 保证同一个文件前后只有一个URL。
很多人考虑是否.COM域名是否要比.CN(国别域名)要好?是的,很多人已经习惯了域名以.COM结尾。这是由于早期由美国人开发的浏览器会自动补全.COM(现在苹果的iPad上默认也有.COM按钮),基于这种情况,我的建议是:
如果网站是英文的或国际性最好使用.com域名
如果网站使用的是其他语言可以使用国别域名代替
如果网站内容是区域性的,无所谓使用哪种域名
国别域名相比.COM域名主要优势是,还有很多可以注册的简短的、易记的域名。
从长远的发展来看,需要大量的名称(按照人类语言习惯)来识别世界上每个实体。新的顶级域名会不断出现,但由于旧的用户习惯,旧的浏览器或软件还是会存在很多年,所以好的域名还是会影响很多年。
怎样设计一个好的URL
URL是网站UI的一部分,因此,可用的网站应该满足这些URL要求:
简单,好记的域名
简短(short)的URL
容易录入的URI
URL能反应站点的结构
URL是可以被用户猜测和hack的(也鼓励用户如此)
永久链接
记住下面四句话,你就知道应该设计什么样的URL了。
URL应当是用户友好的
URL应当是可读的
URL应当是可预测的
URL应当是统一的
网址根目录(level section)是非常珍贵的
对于任何一个URL而言,它最用价值的方面是在他的根目录(level section),我的观点是她必须在你写任何代码前确定下来,他会确定你网站最后是怎么组织起来的。当你想建立新的站点的时候,一定要想好哪些根目录的网址是需要保留的。
命名空间是一个非常有用的拓展网址方案
命名空间是一个建立容易记忆的良好网址结构的方案。那命名空间是什么意思呢?下面是一个例子:
https://github.com/pallets/flask/issues
在上面的URL中,pallets/flask是命名空间。为什么这个是有用的?因为任何跟在命名空间后面的部分都将成为level section。在可以在任何<user>/<repo>后面跟上/issues或/wiki来生成页面。
为了命名空间的通用性,保持命名空间的简洁,不要将内容加在前面或后面,类似/feature/<user>/<repo>或/<user>/<repo>/feature.
查询字符串对排序和过滤非常的有用
网站都有一些查询字符串,很多网站使用多个查询字符串。他们通常使用同一的模式来对页面或内容进行排序或过滤(sort=alpha&dir=desc),他们可以是URL更加简单和易记。
需要记住的是,在URL上没有带任何查询字符串时需要显示一个不同的页面。
非ASCII字符出现在网址中
非 ASCII字符不但难以输入,而且还难以记忆。URL是为人设计的,不是为搜索引擎设计的。在URL中堆砌关键词的手法,并不罕见,比如下面的URL:这样的URL在Google 2003年修改算法前对SEO很有效,但是一些SEO教程上现在还是叫你将关键词写入URL。他们错了,忽略他们。
除此之外,你还需要记住以下两点:
下划线很不好,请在URL中使用中划线。
在URL中使用一些短的、通俗的词,如果一段URL中有中划线会特殊的字符,那它可能有些长。
URL是为人使用的,也是为人设计的。
一个URL就是一个协议
一个URL是一个协议,你需要让他保存做够长的时间。一旦有人点击了你的URL,他们就是和你签署有了一个协议,他们期望下次再打开这个网址的时候看到同样的内容。在你的URL公布出去以后,不要轻易的去修改它,如果你真的迫不得已要去修改它,那么请对原来的URL做跳转。
任何页面都需要有个URL
在理想的情况下,每个单独的页面都需要一个URL,这个URL在复制到别的浏览器的时候要还可以访问。事实上这样做是完全不可能的,直到新的HTML5浏览器历史记录javascript API的出现,这里有两种方法:
onReplaceState:这个方法取代了浏览器历史记录中的URL,使URL留下后退按钮。
onPushState:这个方法能push一个新的URL到浏览器历史记录,用来更换浏览器中的历史堆栈。
这两个新的方法可以改变浏览器中的访问历史,有了这个新的特征,我们需要为页面设计后退页面。在使用前需要问自己:这个动作是否需要产生新的内容或用不同的方法显示相同的内容。
生成新的内容:你应该使用onPushState(如分页链接)
用不同的方法显示相同的内容:你应该使用onReplaceState(如排序了过滤)
通过自己的判断,想想你需要实现怎样的效果。
链接需要看上去像个链接
很多生成链接的方法如<a>、<button>,如果你点击它们它们会打开新的页面,当你将鼠标放在<a>标签时,你的浏览器状态栏就会告诉你URL地址是什么。在使用onReplaceState和onPushState时不要破坏这样的规则。
POST后的网站需要转向
过去很多开发人员喜欢生成不能再次使用的URL,这种URL也称为Post-specific URLs,当你提交一个表单的时候你不会发现地址栏中的URL会发生任何变化,当你将复制URL重新打开后却得到一个错误的页面。这样的URL本身没有任何错误,他们的主要作用是进行重定向和在API中使用,并不应该给用户使用。
一定要短
为了URI能被方便的录入,写下,拼写和记忆,URI 要尽可能的短,根据w3c 提供的参考数据,一个URI的长度最好不要超过80个字节(这并非一个技术限制,经验和统计提供的数据),包括schema和host,port等。
大小写策略
URI的大小写策略要适当,要么全部小写,要么首字母大写,应避免混乱的大小写组合,在Unix 世界,文件路径队大小写是敏感的,而在Windows 世界,则不对大小写敏感。
允许URL管理URL映射
管理员可以重新组织服务器上的文件系统结构,而无需改动URI,这就需要URI和真实的服务器文件系统结构之间有一个映射机制。而不是生硬的对应。这种映射机制可以通过如下技术手段实现:
Aliases,别名,Apache上的目录别名,IIS上的虚拟目录
Symbolic links,符号链接,Unix世界的符号链接
Table or database of mappings,数据库映射,URI和文件系统结构的对应关系存储在数据库中。
标准的重定向
管理员可以简单的通过修改HTTP 状态代码来实现服务器文件系统结构变更之后的URL兼容,可以利用的HTTP Status Code有:
301 Moved Permanently ([RFC2616] section 10.3.2)
302 Found (undefined redirect scheme, [RFC2616] Section 10.3.3)
Temporary Redirect ([RFC2616] Section 10.3.8)
用独立的URI
技术无关的URI
提供动态内容服务时,应使用技术无关的URI。即URI不暴露服务器端使用的脚本语言,平台引擎,而这些语言,平台,引擎的变化也不会导致URI的变更。因此,sevelet,cgi-bin之类的单词不应该出现在URI 中。
提供静态内容服务时,应当隐去文件的扩展名取而代之的技术是content-negotiation, proxy, 和URI mapping
身份标志和Session机制
使用标准的身份认证机制,而不是每个用户一个特定的URI
使用标准的Session机制,而不是把Session ID放在URI中使用
内容变更时使用标准转向:
对变更的内容使用标准的重定向
对删除的资源使用 HTTP 410
提供索引代理:索引策略
Content-Location
Content-MD5
提供适当的缓存信息:
缓存相关的HTTP头
缓存策略
缓存生成内容HTTP HEAD和HTTP GET
总结
URI 是Web UI 的一部分,应当像对待网站Logo 和公司品牌一样对待它
URI 是网站和普通用户之间的唯一接口,应当像对待你的商务电话号码一样对待它
URL中井号的作用
井号在URL中指定的是页面中的一个位置。井号作为页面定位符出现在URL中,浏览器读取这个URL后,会自动将位置滚动至指定区域。
井号后面的数据不会发送到HTTP请求中。井号后面的参数是针对浏览器起作用的而不是服务器端。
任何位于井号后面的字符都是位置标识符。不管第一个井号后面跟的是什么参数,只要是在井号后面的参数一律看成是位置标识符。比如这样一个链接(http://example.com/?color=#fff&;shape=circle),后面跟的参数是颜色和形状,但是服务器却并不能理解URL中的含义。服务器接收到的只是:http://example.com/?color=
改变井号后面的参数不会触发页面的重新加载但是会留下一个历史记录。仅改变井号后面的内容,只会使浏览器滚动到相应的位置,并不会重现加载页面。浏览器并不会去重新请求页面,但是此操作会在浏览器的历史记录中添加一次记录,即你可以通过返回按钮回到上次的位置。这个特性对Ajax来说特别的有用,可以通过设置不同井号值,来表示不同的访问状态,并返回不同的内容给用户。
可以通过javascript使用location.hash来改变井号后面的值。window.location.hash这个属性可以对URL中的井号参数进行修改,基于这个原理,我们可以在不重载页面的前提下创造一条新的访问记录。除此之外,HTML 5新增的onhashchange事件,当#值发生变化时,就会触发这个事件。
Googlebot对井号的过滤机制。默认情况下Google在索引页面的时候会忽略井号后面的参数,同时也不会去执行页面中的javascript。然而谷歌为了支持对Ajax生成内容的索引,定义了如果在URL中使用“#!”,则Google会自动将其后面的内容转成查询字符串_escaped_fragment_的值。比如最新的twitter URL:http://twitter.com/#!/username,Google会自动请求http://twitter.com/?_escaped_fragment_=/username来获取Ajax内容。
实例:Flickr API 中的URL规则
Flickr API中的URL规则非常值得我们学习,下面就来揭开Flickr URL的神秘面纱。
Flickr图片地址
URL主要有下面三类:
http://farmfarm-id.static.flickr.com/server-id/id_secret.jpg
http://farmfarm-id.static.flickr.com/server-id/id_secret_[mstzb].jpg
http://farmfarm-id.static.flickr.com/server-id/id_o-secret_o.(jpg|gif|png)
尺寸字母后缀说明:
| s | small square,小正方形,75×75 |
| t | thumbnail,缩微图,最长边为100 |
| m | small 小图,最长边为240 |
| – | medium,中图,最长边为500 |
| z | medium 640,中等尺寸640,最长边为640 |
| b | large,大图,最长边为1024 |
| o | original image,原始图片,可能是jpg,或是png,或是gif |
注意:原始图片有些不同,他们有自己的密钥,在返回数据中被称为originalsecret,除此之外还包含原始图片格式,被称为originalformat。这些值都会在向API请求原始图片时返回。
以下为图片地址URL示例:
http://farm1.static.flickr.com/2/1418878_1e92283336_m.jpg
farm-id: 1
server-id: 2
photo-id: 1418878
secret: 1e92283336
size: m
Flickr网页地址URL
个人档案及相片页面的URL使用NSID(带@ 符号的数字)或自定义URL(需要设置),可以通过请求flickr.people.getInfo获取自定义URL。不管用户是否设置自定义URL,NSID一直是有效的。所以你可以使用用户ID来进行所有的请求。
你可以非常轻松的创建个人档案、影集、所有照片、个人相片或影集的URL:
http://www.flickr.com/people/user-id/ – profile
http://www.flickr.com/photos/user-id/ – photostream
http://www.flickr.com/photos/user-id/photo-id – individual photo
http://www.flickr.com/photos/user-id/sets/ – all photosets
http://www.flickr.com/photos/user-id/sets/photoset-id – single photoset
同样还可以构建其他页面,比如用户在登录的情况,可以让他们链向 http://www.flickr.com/photos/me/* 或 http://www.flickr.com/people/me/* ,將使用其自己的ID 取代「me」。
链接示例:
http://www.flickr.com/photos/12037949754@N01/
http://www.flickr.com/photos/12037949754@N01/155761353/
http://www.flickr.com/photos/12037949754@N01/sets/
http://www.flickr.com/photos/12037949754@N01/sets/72157594162136485/
短网址服务
Flickr 针对上传的图片提供短网址服务。Flickr上每张相片均拥有经数学计算的简短URL:http://flic.kr/p/base58-photo-id
利用Base58将数字和字母进行组合对照片ID进行压缩。Base58和base62[0-9a-zA-Z]差不多,只是为了更加利于辨认,删除了容易混淆的0, O, I,和 l。
作者:https://www.biaodianfu.com/url-design.html
来源:钱魏Way
版权申明:内容来源网络,仅供分享学习,版权归原创者所有。除非无法确认,我们都会标明作者及出处,如有侵权烦请告知,我们会立即删除并表示歉意。谢谢!
-End-
最近有一些小伙伴,让我帮忙找一些 面试题 资料,于是我翻遍了收藏的 5T 资料后,汇总整理出来,可以说是程序员面试必备!所有资料都整理到网盘了,欢迎下载!
点击👆卡片,关注后回复【面试题】即可获取
在看点这里 好文分享给更多人↓↓
好文分享给更多人↓↓
以上是关于谈谈如何设计好网站的URL的主要内容,如果未能解决你的问题,请参考以下文章