从聚合支付的设计来谈谈几个设计模式
Posted lyc94620
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了从聚合支付的设计来谈谈几个设计模式相关的知识,希望对你有一定的参考价值。
一、背景
基本上每一个需要对接支付公司的项目都有这样一个烦恼:不同的支付公司给到你的支付费率是不一样的,微信支付宝收的费率是0.6%(不知道后面有没有降低),A支付公司费率的是0.5%,B支付公司费率是0.48%。。。此外还有活动等
大部分公司一开始只对接一家或两家支付公司,后面的可能会由于一些原因呢,慢慢的对接多几家支付公司,降低一下成本,提高收益。从代码的角度上看,一开始的支付代码可能是这样的,eg:
//支付数据 $pay = [ ‘money‘ => 10.00, ‘xx‘ => ‘xx‘ ]; if (微信支付) { $wechat = new WeChat(); $result = $weichat->pay($pay); } else if (支付宝支付) { $alipay = new Alipay(); $result = $alipay->pay($pay); } if ($result) { //支付成功 } else { //支付失败 } ...
这样写代码呢,如果项目从头到尾只会对接一家或者两家支付公司的话,且支付的接口只有一两个,理论上不会有太大的问题。
但是如果多接了一家支付公司的话,基本上会在这个基础上进行修改,比如加多一个 if 判断等,eg:
//支付数据 $pay = [ ‘money‘ => 10.00, ‘xx‘ => ‘xx‘ ]; if (微信支付) { if (微信官方支付) { $wechat = new WeChat(); $result = $weichat->pay($pay); } else if (A微信支付) { $aWechat = new AWeChat(); $result = $aWeichat->pay($pay); } else if (B微信支付) { $bWechat = new BWeChat(); $result = $bWeichat->pay($pay); } } else if (支付宝支付) { if (支付宝官方支付) { $alipay = new Alipay(); $result = $alipay->pay($pay); } else if (A支付宝支付) { $aAlipay = new AAlipay(); $result = $aAlipay->pay($pay); } else if (B支付宝支付) { $bAlipay = new BAlipay(); $result = $bAlipay->pay($pay); } } if ($result) { //支付成功 } else { //支付失败 } ...
红色部分为改动的部分,这样的话,每多对接一家支付公司,就多得一个判断,而且每一个涉及到支付的接口都得改动。这样造成的后果就是代码越来越难看,当接口需要改动的时候,任何涉及到支付的接口都要进行修改,维护成本高,容错率低。
这种情况下,往往一开始没有什么特别大的问题,当后面用户多起来的时候,老板想赚更多钱对接更多的支付公司的时候(盈利模式说白了就是中间商赚差价),问题就慢慢出现了。
下面的篇幅笔者将从聚合支付的角度来分析如何优化上述这种支付代码,以及简单介绍下用到设计模式。
二、聚合支付
前段时间,笔者有幸接触到一个支付改造的项目,一开始呢,项目只对接了微信和支付宝的官方支付,代码结构比较简单,支付的接口也只有一个。
后面由于项目的发展,开始对接很多的第三方支付,其中有一个版本需要对接三四个支付方,而且当时用到支付的业务又不少,支付接口有十来个,如果按照以前的方式搞的话,基本上每一个支付接口都要改动,工作量巨大,还要算上支付配置那一块,这里基本上可以算是噩梦了,此外还要处理统计类的业务,比如统计某个商家某段时间某个支付渠道的收入情况等等,别忘了还要处理退款和查询业务。
小结一下,每多一个支付渠道,改动的地方包括:支付接口、支付配置、退款、统计业务。
多一个支付渠道就要改动这么多地方,如果是在之前的代码上加多个 if 进行处理的话,工作量大不说,基本上是复制粘贴,没有任何技术含量,就是简单的逻辑判断,调用接口,处理返回结果,然后就没有了。如果思想只停留在这,那非常危险!必须给自己找点苗头,这样才有搞头,完成任务的同时又提高自己的技术水平,而不是重复同样的事情。
结论已经很清晰了,必须对原有的支付进行改造,这里简单介绍下聚合支付,啥是聚合支付呢,说白了就是一个项目接入了多个支付渠道,而且能够使用任意一个渠道进行支付、退款等操作,而且任何渠道之间没有任何关系,彼此不会互相干扰。
到这里呢,我们来简单梳理一下聚合支付的业务:
-
需要对接多个支付渠道
-
所有的支付能够兼容任意渠道
-
所有的退款能够兼容任何渠道
-
任何渠道都能需要独立进行配置
-
任何渠道都有统计功能
-
渠道之间能够无缝进行切换(比如某个渠道奔溃了,能够切换到其他渠道)
如果想满足上面的功能,又不影响原有的业务的情况下,就需要将原有的支付模块独立抽离开来,单独作为一个服务,也就是聚合支付,凡是项目里面的任何支付、退款、查询、统计等都要通过聚合支付来处理。
然后,要怎么设计呢?考虑到由于涉及到多个支付渠道,首先工厂模式跑不了,一个支付渠道可以看成一个工厂;此外单例模式也要用到,支付的配置是固定的,每必要重复 new 创建;还要适配器模式,由于不同的支付渠道使用的参数或者返回结果都可能不一样,适配器就派上用场了;此外还有策略模式,比如你要根据什么依据创建支付渠道进行支付。
下面的篇幅主要结合支付方面的业务来简单介绍这几种设计模式,以及它们的有点和部分伪代码实现
三、工厂模式
工厂模式:这种类型的设计模式属于创建型模式,它提供了一种创建对象的最佳方式。在工厂模式中,我们在创建对象时不会对客户端暴露创建逻辑,并且是通过使用一个共同的接口来指向新创建的对象。
好处:
-
一个调用者想创建一个对象,只要知道其名称就可以了
-
扩展性高,如果想增加一个产品,只要扩展一个工厂类就可以
-
屏蔽产品的具体实现,调用者只关心产品的接口
为什么用工厂模式呢?由于支付渠道很多,而且不同的支付渠道其实是有共性的,比如:支付、回调、查询、退款、退款查询等。把这些共同的东西抽出来当成一个 IPayChannel 接口,任何支付渠道都需要实现这个接口。
接着上面的聚合支付,使用工厂模式可以将所有的支付渠道抽出一个模型出来,把它们的共同点全部封装成一个接口,不同的支付渠道都需要实现这个接口。eg:
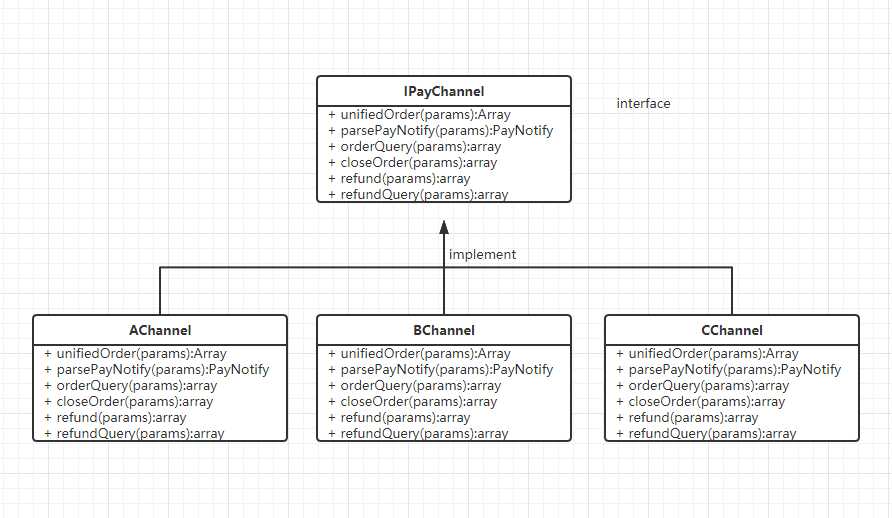
说明:unifiedOrder是统一下单入口、parsePayNotify是处理回调的、orderQuery订单查询、closeOrder订单关闭、refund退款、refundQuery退款查询
下面看一下改造后的代码结构:
//接口 interface IPayChannel { public function unifiedOrder(params); public function parsePayNotify(params); public function orderQuery(params); public function closeOrder(params); public function refund(params); public function refundQuery(params); public function facepayAuthinfo(params); } //AChannel class AChannel implements IPayChannel { public function unifiedOrder(params) { ...do things } public function parsePayNotify(params) { ...do things } public function orderQuery(params) { ...do things } public function closeOrder(params) { ...do things } public function refund(params) { ...do things } public function refundQuery(params) { ...do things } public function facepayAuthinfo(params) { ...do things } }
如果你想使用 AChannel 进行支付的话,就直接创建一个对象,调对应的方法即可,不同通道的操作也是如此。
四、单例模式
单例模式:这种类型的设计模式属于创建型模式,它提供了一种创建对象的最佳方式。这种模式涉及到一个单一的类,该类负责创建自己的对象,同时确保只有单个对象被创建。这个类提供了一种访问其唯一的对象的方式,可以直接访问,不需要实例化该类的对象。
好处:
-
在内存里只有一个实例,减少了内存的开销,尤其是频繁的创建和销毁实例
-
避免对资源的多重占用
对接过支付的人都知道,调用任何一个接口都需要用特定的支付配置,比如公钥、私钥、计算签名的key、请求接口、回调验签的key等,这种配置类型的参数,我们可以抽出来当成一个单例类,避免每一次支付都频繁创建和销毁,减少内存开支。
比如可以把某个支付渠道 A 的配置参数抽出来,当成一个 AChannelConfig,eg:

下面看下改造后的代码,eg:
class AChannelConfig { private static $instance = null; private $setting = []; private function __construct(){} private function __clone(){} public static function getInstance() { if (self::$instance == null) { self::$instance = new self(); } return self::$instance; } public function set($index, $value) { $this->setting[$index] = $value; } public function get($index) { return $this->setting[$index]; } }
支付配置单例类是在创建工厂的时候顺带创建的,一种渠道只需创建一个单例类,由于构造函数是私有的,单例类是无法通过 new 来创建的,一定程度上减少了资源的开销。
五、适配器模式
适配器模式:作为两个不兼容的接口之间的桥梁。这种类型的设计模式属于结构型模式,它结合了两个独立接口的功能。这种模式涉及到一个单一的类,该类负责加入独立的或不兼容的接口功能。
好处:
-
可以让任何两个没有关联的类一起运行
-
提高了类的复用
-
增加了类的透明度
-
灵活性好
当你对接的支付渠道多了之后,你会发现,不同的公司的请求参数和返回参数都是不一样的,这种情况下,你就得需要一个适配器,把它们的数据格式进行适配,转化成你自己的格式,后面不管你对接多少个渠道,对你项目来说,只需要处理适配器返回的数据格式就行了,不需要管第三方返回的格式;支付也是类型,你只管把参数传给适配器,由适配器逆向适配即可。
创建一个 PayChannelAdapter,来对支付参数以及返回结果进行适配,这个跟单例类一样需要结合工厂类进行处理,eg:

改造后的代码如下,eg:
class PayChannelAdapter { public function pay(params) { ...do things } public function refund(params) { ...do things } public function close(params) { ...do things } public function query(params) { ...do things } }
说白了,适配器主要是把返回结果很请求参数进行统一而已,比如A渠道返回的支付金额是amount,B渠道返回的是money,有了适配器之后,你可以将这些统一成amount,这样一来,不管对接什么支付渠道,你仅需要处理适配器返回的结果即可。
至于支付和退款,这个就有点意思,用的是反向适配器,比如我们想支付,传了一组固定的支付参数,适配器会根据你不同的支付渠道生成对应的参数,再调指定的支付渠道。
六、策略模式
策略模式:一个类的行为或其算法可以在运行时更改。这种类型的设计模式属于行为型模式。在策略模式中,我们创建表示各种策略的对象和一个行为随着策略对象改变而改变的 context 对象。策略对象改变 context 对象的执行算法。
好处:
-
算法可以自由切换
-
避免使用多重条件判断
-
扩展性良好
为什么使用策略模式呢?先看下我们的需求,其中有一点说,渠道之间能够无缝切换,就是为了避免某个渠道突然出问题不能用了,为了不影响商家正常营业,只能临时帮商家切换到备用的渠道,尽可能减少商家的损失。这种情况主要是对接的支付公司不是特别靠谱导致的,想想也是,规模达到一定程度的公司,费率也都差不多。一般只有新的渠道为了抢占市场份额才会推出低费率,吸引更多的使用者来使用。
前面说了工厂模式 ,不同的支付渠道对应一个工厂,现在问题来了,要怎么创建工厂,谁来创建工厂,这就得用到策略模式了。
创建一个 PayChannelStrategy 类,用来创建对应的支付通道,结合工厂模式效果更佳,eg:

其中,支付的时候根据一些账号之类的数据判断商家用的默认支付渠道是什么,根据这个依据创建不同工厂并返回;查询的时候则根据已有的订单ID,查询订单下单时用的哪个渠道,返回对应的工厂类。
改造后的代码结构如下,eg:
class PayChannelStrategy { public function createPayChannel($params) { 这里根据一些特定的依据创建并返回工厂类 } public function createPayChannelByOrderId($params) { 这里根据一些特定的依据创建并返回工厂类 } }
有了策略模式,我们只需要根据商家的信息以及要支付的数据,就可以轻轻松松拿到对应的工厂类,再调用对应的方法完成支付、查询、退款等操作。如同你去某个地方旅行一样,坐汽车、坐高铁、坐飞机等都是一种策略,每个商家也对应一种支付策略,不同的策略之间往往是独立的,不会相互影响。
七、优缺点
上述的聚合支付设计,用到了:工厂模式、单例模式、适配器模式、策略模式
对于使用者来说,你仅仅只需要拿到商家的一些数据,用 PayChannelStrategy 创建支付通道,拿到对应的通道类后,就可以进行你的支付、查询、退款等操作,最后根据返回的结果进行判断就行了。
从代码的角度上看,原本乱七八糟的代码现在被划分为几块,一个是通道块(工厂类),一个是配置块(单例类),一个是适配器块,以及策略块,如下图:

先说下优点:
-
代码结构清晰,不同的类处理不同的业务
-
易于扩展,新增一个渠道so easy
-
屏蔽了具体的实现,只需要关心接口即可
-
灵活性高,算法可以自由切换,避免多重判断
-
兼容性高
当然也是有缺点的:
-
由于使用了工厂模式,每多一个渠道就要新增一个文件,当工厂多了就不是什么好事了
-
适配器过多的使用也会造成一定的复杂性,一个类尽量少用或者使用一个适配器
-
策略类多了,也会有膨胀的问题
八、总结
在我们平时的开发过程中,不仅要避免重复性的工作,也不能一味为了做需求而敲代码,要学会思考,尽可能结合我们学到的数据结构、算法、设计模式,毕竟这些解决方案是众多软件开发人员经过相当长的一段时间的试验和错误总结出来的。不仅能在一定程度上提高我们的开发效率,也能够让我们巩固基础知识,也能提高团队的效率,一个项目往往不是一个人开发的,我们写代码的同时也要关注团队开发效率上的问题。
此外呢,很多的设计模式在实际的开发过程中不一定是单一使用的,而是综合使用的。
不过也要注意一些问题,算法、数据结构、设计模式等从根据实际业务出发,不能盲目使用,也不是用的越多越好,对你的业务有帮助才是最好的解决办法。使用得当的话,会使代码干净整洁易于维护,减少大量重复的判断和使用,让代码更加易于维护和拓展。
参考:设计模式
以上是关于从聚合支付的设计来谈谈几个设计模式的主要内容,如果未能解决你的问题,请参考以下文章