ACL2022 自监督文本表示新框架ArcCSE
Posted 阿里巴巴淘系技术团队官网博客
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ACL2022 自监督文本表示新框架ArcCSE相关的知识,希望对你有一定的参考价值。

学习高质量文本表示是NLP的基础任务之一,可应用于大量的下游任务。尽管像BERT之类的预训练语言模型获得了巨大成功的,但在文本语义相似任务中,直接用其获取的文本表征往往效果欠佳。最近一些基于对比学习的文本表示建模方法取得了不错的效果,但这些方法更多关注于正负表征对的构建,对训练目标优化不足。如先前工作普遍采用的NT-Xent loss,判别能力不足且无法建模文本间的语义偏序关系。因此,本文提出一种新的自监督文本表示算法ArcCSE,通过设计新的对比学习目标并建模文本间语义偏序关系,增强模型对样本语义的区分能力。实验表明,该方法在STS和SentEval多个文本语义相关性及下游迁移任务上超过此前的自监督文本表示模型。相关文章“A Contrastive Framework for Learning Sentence Representations from Pairwise and Triple-wise Perspective in Angular Space”已被ACL 2022录用。
基于BERT[1]等预训练语言模型获取文本表征向量时,若不经finetune直接采用[CLS] embedding或输出层embedding的均值作为表征,常常无法得到较好的效果,有时效果甚至不如非结合上下文语境的embedding方法如GloVe。有鉴于此,近期一些自监督文本表征算法陆续提出,这些方法往往侧重于采用不同的文本数据增强方法或不同的模型结构来获取文本表征正样本对,并通过对比学习方法来对模型进行优化。已有工作对训练目标本身探索较少,因此本文从对比学习损失函数构建和文本间语义偏序关系建模角度出发,提出了一种新的自监督文本表示算法,相较已有算法表现出更好的语义判别力,如图1。
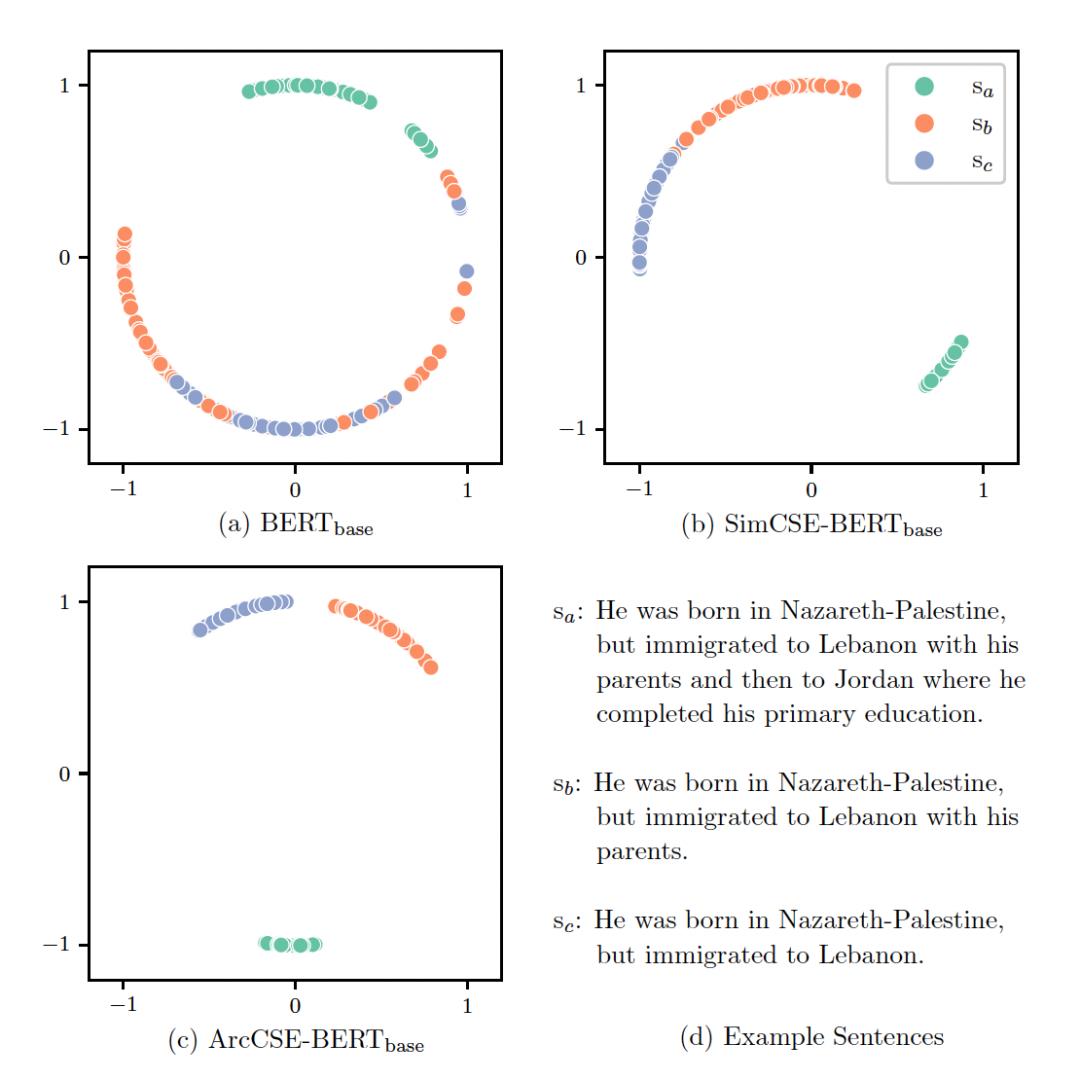
图1. 文本表示向量可视化, 将三个相关文本分别经过BERT、SimCSE和ArcCSE多次获取多个表示向量,再用t-SNE降维进行可视化
方法
ArcCSE算法框架主要包含pairwise文本关系建模和triple-wise文本关系建模,算法框架如下图所示。
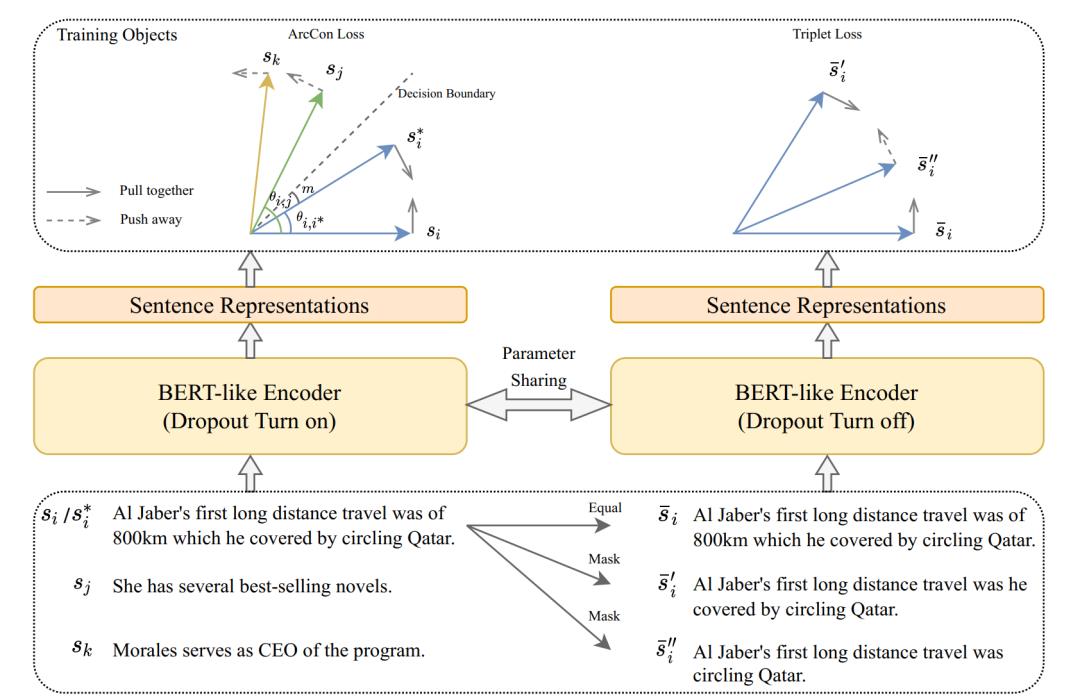
图2. ArcCSE算法框架
▐ 基于Angular Margin的对比学习
为了建模pairwise文本关系,需挖掘文本语义层面的正样本与负样本对。参考SimCSE [2],本文采用dropout作为文本增广方法获取文本表示正样本对。由于dropout的随机性,同一文本经过encoder两次可得到两个相似的表示向量 ,构成正样本对。同一batch中不同文本的表示向量构成负样本对
,构成正样本对。同一batch中不同文本的表示向量构成负样本对 ,而后基于这些样本对进行对比学习。
,而后基于这些样本对进行对比学习。
常用的对比学习目标NT-Xent loss [3] 形式如下:

其中
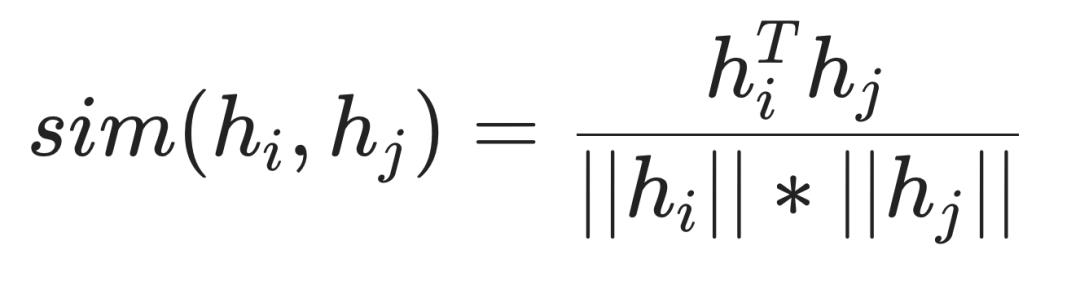
该目标函数可将相似语义的文本拉近,不相似的文本推开,其决策边界为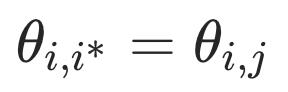 。其中
。其中
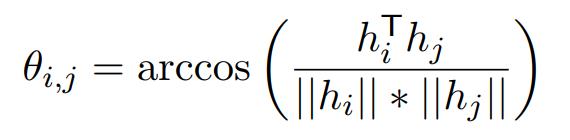
该目标函数对不同表征的区分性仍有不足,对噪声不够鲁棒。决策边界附近微小的扰动都可能导致不同的判别结果(如图3左所示)。
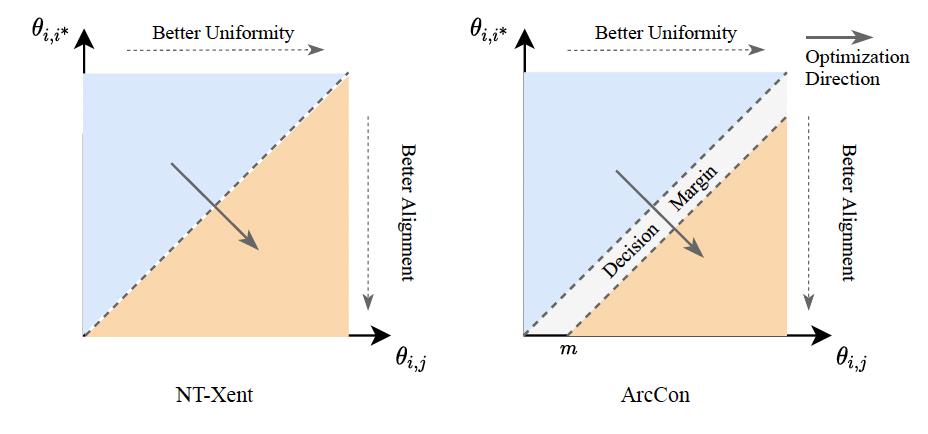
图3. NT-Xent loss和ArcCon loss对比
为克服该问题,本文提出新的目标函数Angular Margin Contrastive Loss(ArcCon Loss),在正样本对之间增加额外的angular margin,表示如下:

在该loss函数中,决策边界为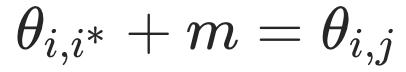 (如图3右所示)。相较ArcFace[4],ArcCon不需要标注信息。相较NT-Xent,其鲁棒性更强,并且能进一步提升反映对比学习表征质量的两个指标alignment和uniformity [5]。其中alignment反映表征空间中正样本对的接近程度,uniformity反映表征向量在空间中分布的均匀程度,可分别计算如下:
(如图3右所示)。相较ArcFace[4],ArcCon不需要标注信息。相较NT-Xent,其鲁棒性更强,并且能进一步提升反映对比学习表征质量的两个指标alignment和uniformity [5]。其中alignment反映表征空间中正样本对的接近程度,uniformity反映表征向量在空间中分布的均匀程度,可分别计算如下:
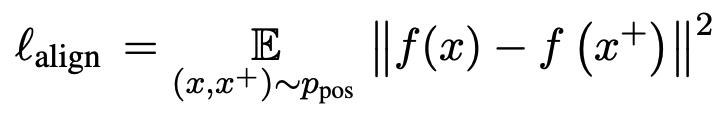
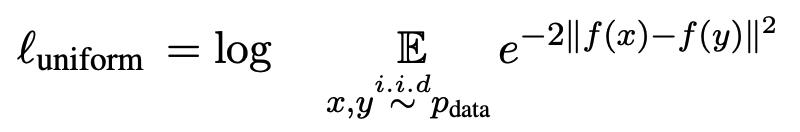
模型训练过程中alignment和uniformity的变化如图4所示。
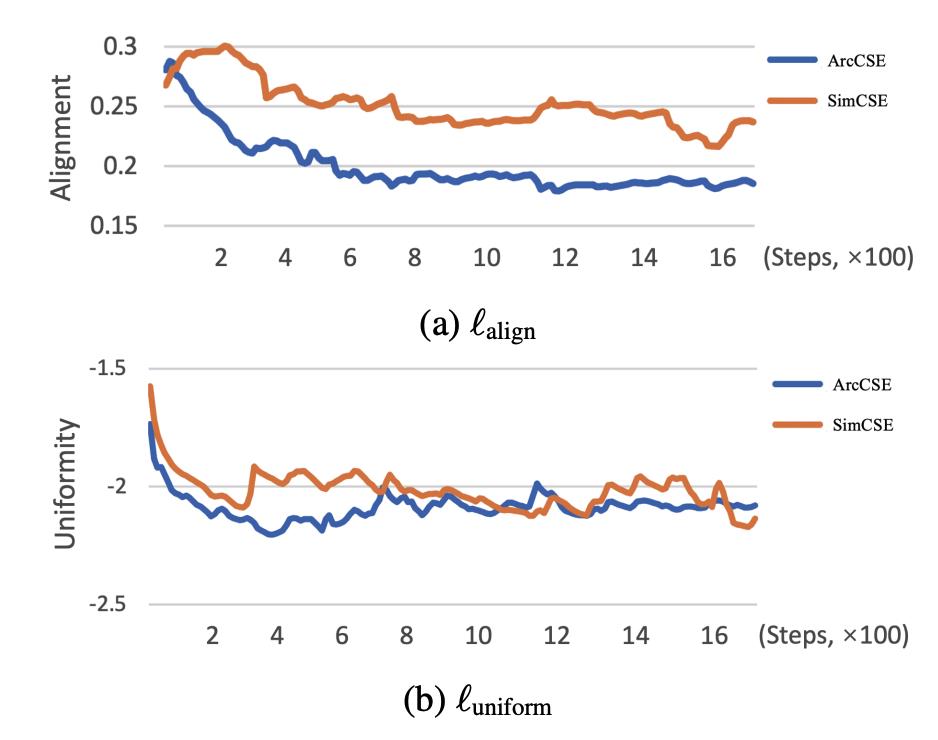
图4. alignment和uniformity在模型训练过程中的变化(值越小越好)
由图4可以看到,ArcCSE与采用NT-Xent的SimCSE均可提升alignment和uniformity,相较SimCSE,ArcCSE在alignment上的提升更为明显。
▐ 建模文本语义偏序关系
以往的研究工作仅考虑文本间pairwise语义关系,即文本或相似或不相似。但事实上文本语义存在不同的相似程度,比如s2跟s1可以比s3跟s1更相似,现有的方法缺乏建模这样的偏序关系的能力。
为了区分不同的语义相似程度,本文提出一种新的自监督任务,建模自动生成的triplet文本之间的蕴含关系。对于数据集中的每个文本si,先通过mask句中的一个连续片段得到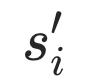 (mask比率20%,消融实验确定),再增大mask区域得到
(mask比率20%,消融实验确定),再增大mask区域得到 (mask比率40%,消融实验确定),如下例所示:
(mask比率40%,消融实验确定),如下例所示:

这样可以构造存在蕴含关系的三元组triplet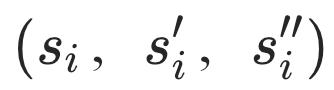 。在少数情形下,构造的三元组可能不满足蕴含关系,但多数情形下蕴含关系成立。因此在分析大量数据后,模型会强化对正确信息的判别,噪声信息的影响较为有限。
。在少数情形下,构造的三元组可能不满足蕴含关系,但多数情形下蕴含关系成立。因此在分析大量数据后,模型会强化对正确信息的判别,噪声信息的影响较为有限。
由于三个文本语义相似,用encoder生成表示向量时如果dropout开启可能会引入额外的噪声,降低对蕴含关系信息的利用能力。因此在该部分建模中会关闭用于生成表示向量的encoder里的dropout。
由于到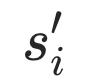 跟
跟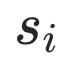 比
比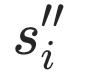 跟
跟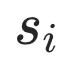 更相似,我们可以用triplet loss建模这种关系:
更相似,我们可以用triplet loss建模这种关系:

其中 是由不带dropout噪声生成的
是由不带dropout噪声生成的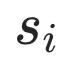 的表示向量,
的表示向量, 表示
表示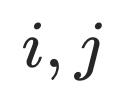 之间的cosine相似度,
之间的cosine相似度,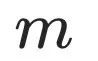 取0。
取0。
综合以上两部分的建模,得到最终优化目标:
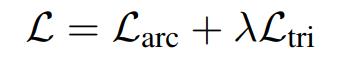
实验
本文在两类评估任务上进行了对比实验:
无监督语义相似性任务(STS),主要评价模型判别文本语义相似度的能力
SentEval 迁移任务,评价文本表示向量迁移到下游任务时的效果
▐ 无监督STS任务
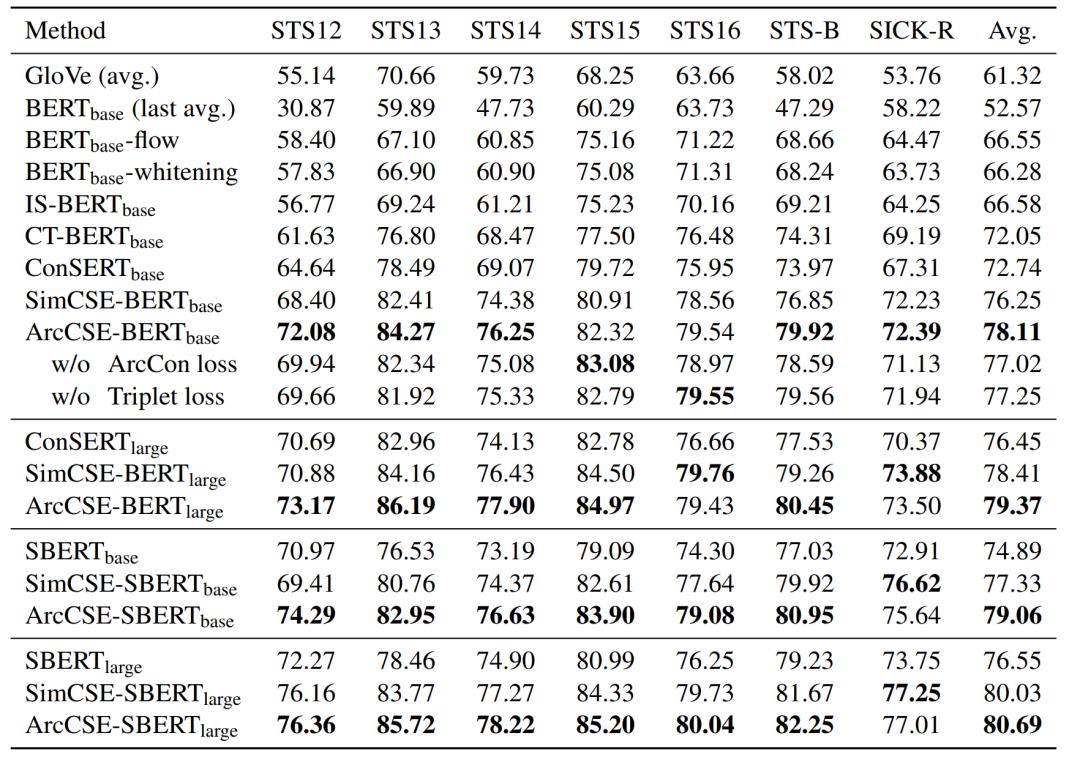
表1. 在STS任务上的文本表示的性能(Spearman's correlation)
由表1结果可以看到,将ArcCSE应用于BERT与SBERT预训练模型时,在base和large模型尺度上效果均有明显提升,超过此前的SOTA算法SimCSE。对比实验证明文章提出ArcCon优化目标和Triplet优化目标均可有效提升模型效果。
▐ SentEval 任务

表2. 文本表示在SentEval迁移任务的性能
表2结果表明基于ArcCSE产生的文本表示向量在应用于下游的文本分类、情感分析等任务时取得了较好的效果,平均准确率优于SimCSE及其他经典模型。
总结
论文提出一种新的自监督文本表示框架ArcCSE,其通过引入angular margin构建了一个新的对比学习目标,可增强文本语义判别能力,同时提出了一个新的自监督任务对文本的语义偏序关系进行建模。在STS语义相似度判别任务和SentEval迁移任务上的实验表明ArcCSE效果优于SOTA算法。该方案已在淘系内容理解业务中落地应用,如点淘、闲鱼业务场景中话题及内容的检索聚合等。
Reference
[1] Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. BERT: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pages 4171–4186, Minneapolis, Minnesota. Association for Computational Linguistics.
[2] Tianyu Gao, Xingcheng Yao, and Danqi Chen. 2021. Simcse: Simple contrastive learning of sentence embeddings. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing (EMNLP). Association for Computational Linguistics.
[3] Ting Chen, Simon Kornblith, Mohammad Norouzi, and Geoffrey Hinton. 2020. A simple framework for contrastive learning of visual representations. In Proceedings of the 37th International Conference on Machine Learning, volume 119 of Proceedings of Machine Learning Research, pages 1597–1607. PMLR.
[4] Jiankang Deng, Jia Guo, Niannan Xue, and Stefanos Zafeiriou. 2019. Arcface: Additive angular margin loss for deep face recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR).
[5] Tongzhou Wang and Phillip Isola. 2020. Understanding contrastive representation learning through alignment and uniformity on the hypersphere. In Proceedings of the 37th International Conference on Machine Learning, volume 119 of Proceedings of Machine Learning Research, pages 9929–9939. PMLR.
团队介绍
大淘宝技术内容理解团队依托淘系内容数据资产,建设了内容场景下的结构化标签、检索、审核、互动与生产等技术体系。支持淘宝直播、逛逛和点淘等十余个核心业务。我们持续以技术驱动产品和商品创新,不断探索和衍⽣颠覆型互联⽹新技术,获得过国家科技进步⼆等奖,在NIPS、CVPR、ACL、TPAMI、TIP等会议及期刊上发表10余篇机器视觉和自然语言相关的论文。
✿ 拓展阅读


作者|钰皓
出品|阿里巴巴新零售淘系技术


以上是关于ACL2022 自监督文本表示新框架ArcCSE的主要内容,如果未能解决你的问题,请参考以下文章
CVPR 2022 | FAIR提出MaskFeat:自监督视觉预训练新方法!灵感之一来自16年前CVPR论文...
CVPR 2022 | FAIR提出MaskFeat:自监督视觉预训练新方法!灵感之一来自16年前CVPR论文...