ICLR和CVPR双料大作:谷歌自监督学习框架,夺榜多个异常检测
Posted 人工智能博士
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ICLR和CVPR双料大作:谷歌自监督学习框架,夺榜多个异常检测相关的知识,希望对你有一定的参考价值。
点上方人工智能算法与Python大数据获取更多干货
在右上方 ··· 设为星标 ★,第一时间获取资源
仅做学术分享,如有侵权,联系删除
转载于 :新智元
ICLR2021和CVPR2021双料大作,谷歌最新成果,融合单类分类与深度表示的自监督学习的异常检测算法,超越多个数据集基准。
异常检测(有时称为离群值检测或分布外检测)是许多领域中最常见的机器学习应用之一,从制造业中的缺陷检测到金融中的诈骗交易检测。
它常用于收集大量正常样本很容易,但异常数据很少且难以找到的情况。经典算法如单类分类算法中的单类支持向量机(OC-SVM)或支持向量数据表示(SVDD)常用于异常检测,不幸的是,这些经典算法并没有从使强大的机器学习大放异彩。
反而,通过自监督学习包括旋转预测(rotation prediction)和对比学习(contrastive learning)从无标记数据中学习视觉特征表示,将单类分类器与深度表示学习的成功结合起来,在异常数据检测上取得了长足的进展。
深度单类分类(Deep One-Class Classification)的两阶段框架
【问题】虽然端到端学习已经在许多机器学习问题上取得了成功,包括深度学习算法设计,但这种用于深度单类分类器的方法往往会出现退化,即不管输入是什么,模型都输出相同的结果。
为了解决这个问题,谷歌推出了一个两阶段(two-stage)框架。
该框架发表在在ICLR2021的“Learning and Evaluating Representations for Deep One-class Classification”中,利用自监督表示学习的最新进展和经典单类算法,在各类基准测试中取得了最先进的指标,包括CIFAR、f-MNIST、Cat vs Dog和CelebA,而且训练还很简单。
随后,在CVPR2021上发表了“CutPaste: Self-Supervised Learning for Anomaly Detection and Localization”,在同框架下提出一种新的表示学习算法,用于工业缺陷检测,在MVTec基准上同样达到了新的最高水平。
在第一阶段,模型通过自监督学习深度特征表示。在第二阶段,采用单类分类算法,如OC-SVM或核密度估计,将第一阶段学习的特征表示作为输入。
这种两阶段算法不仅对退化具有鲁棒性,而且可以建立更精确的单类分类器。此外,该框架并不局限于特定的表示学习和单类分类算法——即可以很容易地在不同算法中即插即用。(下图为gif,建议下载动图)

语义异常检测
谷歌用两种具有代表性的自监督表示学习算法,旋转预测和对比学习,来测试该两阶段框架在异常检测方面的有效性。
旋转预测,是指模型对输入图像旋转角度的检测能力。之所以选用旋转预测,是因为端到端旋转预测网络的良好性能,已被广泛应用于一类分类研究。现有的方法通常使用内置的旋转预测分类器来学习表示来进行异常检测,但由于内置的分类器没有经过训练来进行单类分类,所以这种方法是次优的。
对比学习,是指模型学习把从相同图像转换来的样本放在一起,同时将其他图像转换而来的推开。在训练过程中,当图像从数据集中提取时,每个图像都经过两次简单的增强(如随机裁剪或颜色变化)。
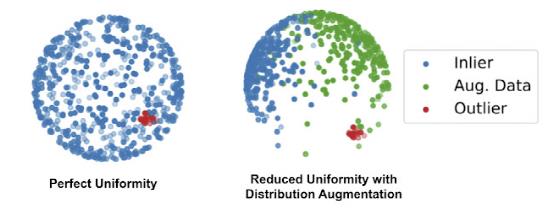
通过最小化与同一图像之间的距离以鼓励一致性,同时最大化不同图像之间的距离。通常的对比学习会收敛于这样一种解,即所有正规样本的表示都均匀地分布在一个球面上。这是有问题的,因为大多数单类算法通过检查测试示例与正常训练示例的接近程度来确定离群值,但当所有正态示例都均匀分布在整个空间时,离群值就会不太容易检出。
为了解决这一问题,谷歌提出了单类对比学习的分布增广(DA)方法。其思想是,模型不是仅仅从训练数据中学习表示,而是从训练数据加上增强样本的并集中学习,其中增强训练样本可以几何变换,如旋转或水平翻转,来增加分布。使用DA,训练数据不再均匀分布在表示空间中,因为一些区域被增强数据占据。
【旋转预测实验】
在计算机视觉中常用的数据集上,包括CIFAR10和CIFAR-100、Fashion MNIST和Cat vs Dog,通过area under receiver operating characteristic curve(AUC)来评估单类分类的性能。例如,当狗的图像是inlier的时候,猫的图像是如何被检测出异常outlier的。
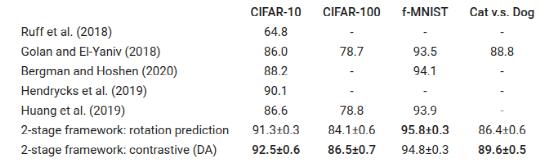
考虑到次优的内置旋转预测分类器通常用于旋转预测,所以,在框架的第二阶段,只需用一个类分类器替换第一阶段用于学习表示的内置旋转分类器,就可以显著提高性能,从86到91.3 AUC。而且,该两阶段框架在上述所有基准上都实现了最先进的性能。
【对比学习实验】
在真实世界的异常检测应用中,异常通常是由局部缺陷定义的,而不是完全不同的语义,例如,纹理异常检测。

尽管旋转预测和分布增强对比学习表示在语义异常检测方面表现出了最先进的性能,但这些算法在纹理异常检测方面表现不佳。相反,对比学习可能更适合这种场景。
第二篇论文中,谷歌提出了一种新的纹理异常检测的自监督学习算法。整体异常检测遵循两阶段框架,但第一阶段,模型学习图像的深度表示,专门训练来预测图像是否通过简单的剪贴数据增强。(剪贴增强:通过随机剪切一个给定图像的局部补丁,并将其粘贴回同一图像的不同位置)。学习区分常规样本和剪贴增强样本,有助于提升特征对图像局部不规则性的敏感度。

使用MVTec进行测试,包含15个对象类别的真实缺陷检测数据集来评估上述方法。

另外,除了图像级的异常检测外,还使用CutPaste方法来定位异常的位置,即“patch-level”异常检测。通过高斯平滑的上采样来聚合补丁异常分数,并在显示异常位置的热图中可视化它们,这大大改善了异常的定位性能。下表显示了用于本地化评估的像素级AUC。

在这项工作中,谷歌通过引入一个新的2阶段深度单类分类框架,并强调了将构建分类器与学习表示解耦的重要性,以便分类器能够与目标任务一致,进行单类分类。
此外,该方法允许各种自监督表示学习方法的应用,在从语义异常到纹理缺陷检测的各种视觉单类分类应用中取得了最先进的性能。
---------♥---------
声明:本内容来源网络,版权属于原作者
图片来源网络,不代表本公众号立场。如有侵权,联系删除
AI博士私人微信,还有少量空位


点个在看支持一下吧

以上是关于ICLR和CVPR双料大作:谷歌自监督学习框架,夺榜多个异常检测的主要内容,如果未能解决你的问题,请参考以下文章
学习笔记 | 2023 ICLR ParetoGNN 多任务自监督图神经网络实现更强的任务泛化