字节跳动获CVPR2021 细粒度图像竞赛双料冠军
Posted QbitAl
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了字节跳动获CVPR2021 细粒度图像竞赛双料冠军相关的知识,希望对你有一定的参考价值。
允峰 发自 凹非寺
量子位 报道 | 公众号 QbitAI
当我们还对玫瑰、月季和蔷薇傻傻分不清楚的时候,计算机视觉已经可以在一万种极其相似的自然界物种里精确地分门别类了。
图像分类是计算机视觉领域一个由来已久,经过了深入挖掘的问题。但在训练数据有限且类别高度相似的领域中,现有技术的表现并不尽如人意。特别是细粒度分类(Fine-Grained Visual Categorization),如视觉上相似的植物或动物物种、视网膜疾病、建筑风格等的精确区分,仍然极具挑战性。当前,细粒度图像分类也被认为是计算机视觉领域正在解决的最有趣和最有用的开放问题之一。
FGVC是全球顶级计算机视觉盛会CVPR主办的workshop竞赛。在刚刚落幕的CVPR2021中,字节跳动以出色的表现 ,荣获了iNat Challenge 2021大规模细粒度分类和Semi-Supervised iNat 2021:半监督细粒度分类两项竞赛的冠军。
一起看看技术大神们是怎么做到的吧。

△BrownBlueGreendd团队在iNat Challenge2021竞赛中夺冠

△Amadeus团队在Semi-Supervised iNat2021竞赛中夺冠
△BrwonBlueGreendd和Amadeus成员均来自字节跳动智能创作团队
背景介绍
据估计,自然界包含数百万种极其相似的植物和动物。在细粒度分类上,如果没有专业知识,许多物种极难分类。而且,数据收集和标注也面临较大的困难,常常伴随着类别大,数据量少,无标注样本多的问题。
本届FGVC在细粒度分类的方向上举办了两个不同设定的比赛。
1)iNat Challenge 2021:大规模的细粒度分类,任务要求在10000类数据上对自然界中的物种进行分类;
2)Semi-Supervised iNat 2021:半监督的细粒度分类,任务旨在揭示现实环境中遇到的一些挑战,从部分标注的数据中学习。
比赛难点
两项赛事在侧重点和设定上各有不同,从不同角度指向了细粒度分类中常遇到的难点:
1)细粒度分类类别多;
2)大量标签的类间差异小;
3)图像数据中背景干扰较大,实际区分区域占比差异大;
4)数据标注难度大导致有标注数据量少;
5)无标注数据中同时包含类内和类外未标记数据,且类外数据占比不明,比例较大;
6)类间数据不平衡,标注/无标注数据均有明显的长尾现象等等。
算法技术方案
全监督赛道
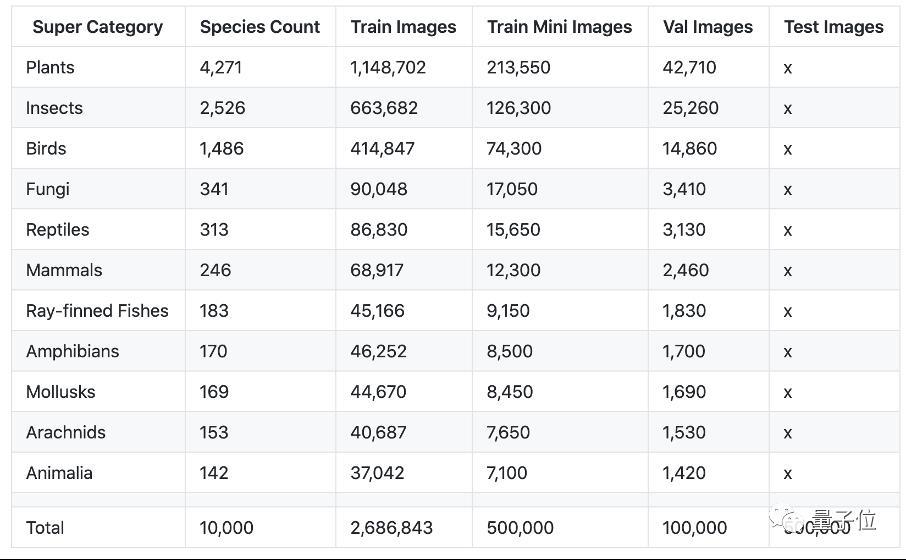 △全监督赛道的物种数量分布
△全监督赛道的物种数量分布
全监督赛道面对的主要问题是物种类别数目多,分类的粒度细,不同物种之间数量差异比较大,因此,BrownBlueGreendd团队从针对该任务在以下几个方面进行了改进。
网络结构设计
不同于普通的图像分类任务,在细粒度任务中使用简单的Softmax 加交叉熵的损失函数往往训练起来收敛较慢且效果欠佳。在细粒度场景下,团队选择度量学习中常用的ArcFace[1]作为损失函数,Arcface通过增加边界惩罚,增强了类内的紧凑度以及类间的差异,有效的提升了模型的分类准确率。

△Arcface计算公式
在Backbone网络的选择中,团队选择了基于Transformer结构的Swin-Transformer[2]以及基于CNN结构的EfficientNet[3] 作为基础网络,这两个Backbone的优点是模型的Imagenet 准确率较高且性能较好。
多模态信息融合
与往年的比赛设置不同,今年的比赛中主办方提供了图像的经纬度以及日期等信息,这对自然界生物的细粒度识别有很大的帮助,比如南美洲和亚洲的某种植物,在采集的图像上可能差异并不大,但通过图像的经纬度等信息,就可以很容易的对两个物种进行区分。团队设计了如图所示的多模态信息融合网络,其中,图像信息通过Backbone网络得到相应的图像特征。对于地理信息,首先对地理信息进行编码,然后通过Embedding网络映射成为特征向量,与图像特征进行叠加后,送入最后的分类器中。实验结果显示加入地理特征后,在不同的网络结构中均有3-4个点的提升。
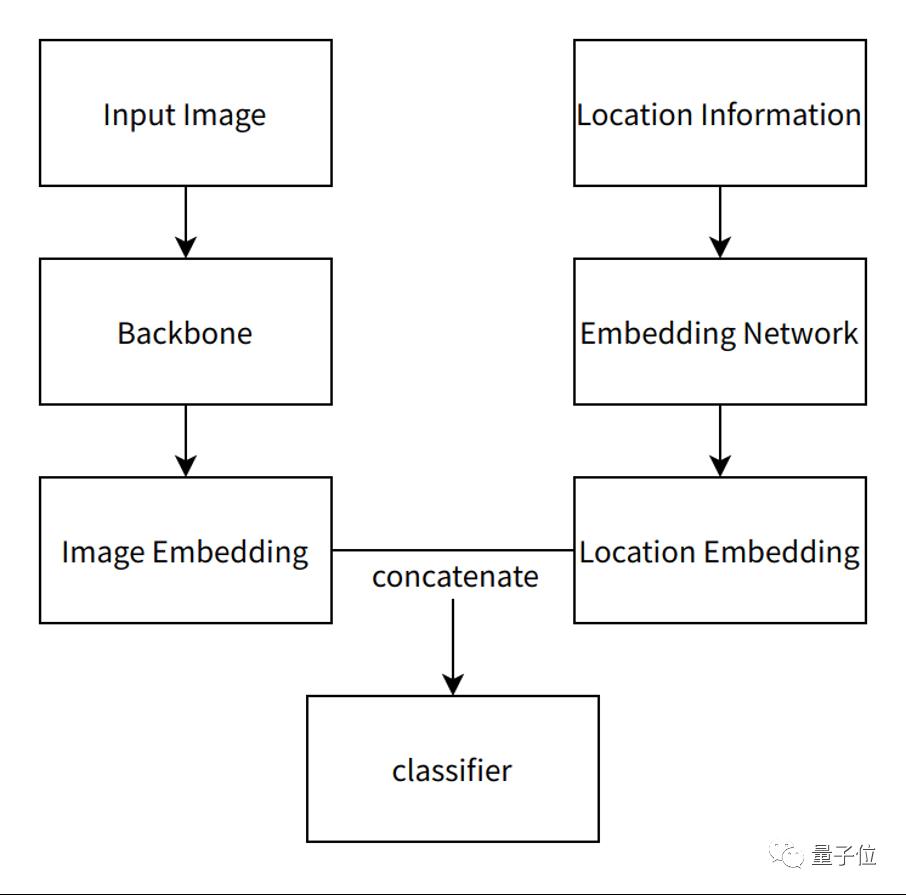
△多模态信息融合网络
此外,赛后团队还探索了基于检测的方案。首先基于历年具有检测框的数据训练一个目标检测器。对于输入的原始图像,首先用检测器提取图像的关键区域,随后将原始图像与提取的关键区域图像分别经过特征提取网络,并进行特征融合。实验表明,在模型参数量几乎不变的情况下,采用基于检测的方案会给同样的基础模型准确率带来明显的提升。

△基于检测的方案
数据增强
在训练阶段,团队采用随机翻转,随机旋转,以及亮度、对比度、饱和度上的变化进行数据增强。同时团队还采用了随机擦除的增强方式,即在输入图中随机选择一块区域以概率P擦除该区域,并使用图像的均值进行填充,有效的缓解了过拟合现象。
在测试阶段,团队使用FiveCrop、水平翻转与多尺度测试来提高模型的表现。此外,对于多个基础模型的预测结果,抛弃了现有的模型融合策略,创新性地采用了进化算法实现多模型预测的融合,对每个基础模型的投票权重进行迭代优化,避免了手动调节超参数的同时,进一步提升了预测准确率。最后,团队得到了95.56%(Public)/95.58%(Private)的Top1 准确率。
半监督赛道
半监督学习旨在使用更有效的方式利用无标注数据去提升模型的效果。其中一部分方法是通过在无标注数据上进行无监督学习(对比学习)等,得到预训练模型后在有标注数据上进行fine-tuning,如MoCo[4] 系列,SimCLR[5] 系列,SwAV[6] 等。另外一些方法是在共同使用这些有标注及无标注数据进行训练,如FixMatch[7],MixMatch[8]等。
无监督训练方案
无标注数据的使用可以在few-shot场景下带来较大的收益,如何利用这部分数据显得非常重要。该场景的设定困难且较为贴近实际场景,即同时包含类内及类外的数据,类外数据占比可能在70%-90%。同时由于细粒度的特性,数据的类间差异较小。这些特点使得无监督对比学习及半监督学习在该设定下的收益较小。
团队设计并优化了聚类方案将无监督转化为大规模小量数据的有监督学习,通过特征和类别信息将无标注图像划分成cluster,通过cluster分布和数量等信息选取相应的有效类别,将cluster信息当作弱监督的标注进行有监督训练。
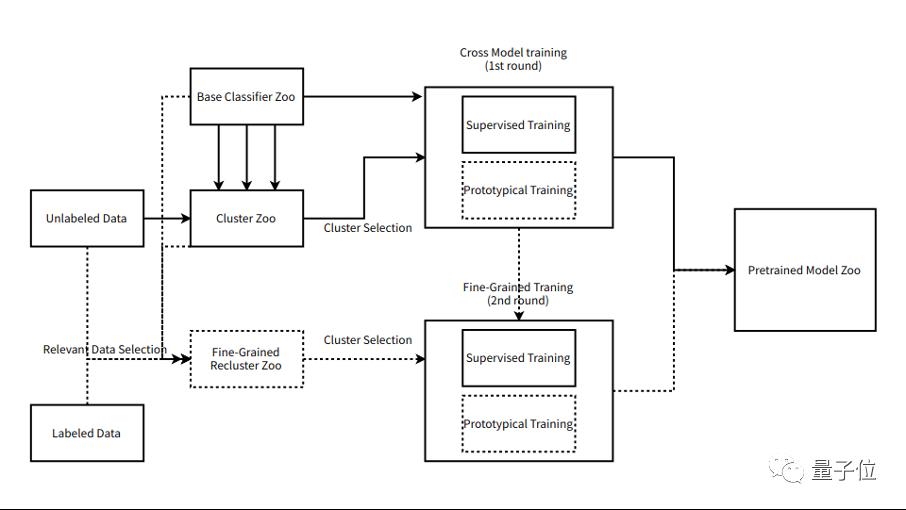
△无监督训练流程
随后通过使用有监督数据进行引导和pseudo-label的方式筛选与目标标签更紧密更相关的数据,进行二轮Fine-Grained Recluster。并将前一阶段的模型在该精细数据上进行微调,得到新的预训练模型。
同时,训练期间可以采用Prototypical的方式,减少长尾及数据量少带来的影响。
有监督训练方案
有标注的数据在数量较少,在进行微调的过程中,很容易出现过拟合的情况,而且由于过拟合的情况,导致数据平衡策略都不是很奏效。同时由于模型参数量的不同,微调对于过拟合/拟合的程度也不同,在参数量大的模型,如ResNeSt269e及NFNet,单一学习率及双阶段微调会产生严重的过拟合。
于是团队针对解决过拟合问题采用了两种不同的微调方法。
1) 针对参数量较大的模型,使用分层学习率微调,冻住BN/LN层,对于浅层网络开小学习率,采用数据平衡策略进行训练。
2)针对参数量较小的模型,使用双阶段微调,第一阶段冻住BN/LN层,端到端微调整个网络,第二阶段冻住骨干网络,采用数据平衡策略微调最后的refactor及fc线性层。
双阶段相较单阶段有更大的收益,分层学习率对于大参数量模型在单阶段也有更好的效果。

△微调流程
迭代训练
该训练流程是可以迭代起来以增强网络的最终效果,通过更好的模型可以获得更好的cluster及pseudo-label,可以产出更强的预训练模型,以及准确的预测结果。
测试阶段
测试阶段采用多尺度测试及Five Crop等增强方式。同时使用不同结构不同训练方式的网络进行ensemble,最终在官方验证集上达到了82.1%的Top-1准确率。
结果与总结
采用上述的技术方案,团队在全监督和半监督赛道均取得了冠军的成绩。

△全监督赛道

△半监督赛道
成果落地应用
细粒度识别在多种场景下都有着应用,比如识别身边的植物,动物,商品等。半监督的技术贴合细粒度问题的实际运用场景,使得团队在构建深度学习模型时,降低标注成本,使用更少的数据,以更低的成本来完成模型的训练。目前,上述技术正在字节跳动的部分产品里开发落地。
字节跳动智能创作团队
智能创作团队是字节跳动的多媒体创新科技研究所和综合型服务商。覆盖音视频、计算机视觉、语音、图形图像、工程软件开发等多技术方向,在部门内部实现了内容创作和消费的闭环。旨在以多种形式向公司内部各类业务线和外部 toB 合作伙伴提供业界最前沿的多媒体和智能创作能力与行业解决方案。
目前,智能创作团队已通过字节跳动旗下的智能科技品牌火山引擎向企业开放技术能力和服务。
参考文献
[1] Jiankang Deng, Jia Guo, Niannan Xue, and Stefanos Zafeiriou. Arcface: Additive angular margin loss for deep face recognition. In CVPR, pages 4690–4699, 2019.
[2] Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, and Baining Guo. Swin transformer: Hierarchical vision transformer using shifted windows. arXiv preprint arXiv:2103.14030, 2021.
[3] Mingxing Tan and Quoc V Le. Efficientnet: Rethinking model scaling for convolutional neural networks. arXiv preprint arXiv:1905.11946, 2019.
[4] Kaiming He, Haoqi Fan, Yuxin Wu, Saining Xie, and Ross Girshick. Momentum contrast for unsupervised visual representation learning. arXiv preprint arXiv:1911.05722, 2019.
[5] Ting Chen, Simon Kornblith, Mohammad Norouzi, and Geoffrey Hinton. A simple framework for contrastive learning of visual representations. arXiv preprint arXiv:2002.05709, 2020.
[6] Mathilde Caron, Ishan Misra, Julien Mairal, Priya Goyal, Piotr Bojanowski, and Armand Joulin. Unsupervised learning of visual features by contrasting cluster assignments. arXiv preprint arXiv:2006.09882, 2020.
[7] Kihyuk Sohn, David Berthelot, Chun-Liang Li, Zizhao Zhang, Nicholas Carlini, Ekin D Cubuk, Alex Kurakin, Han Zhang, and Colin Raffel. Fixmatch: Simplifying semisupervised learning with consistency and confidence. arXiv preprint arXiv:2001.07685, 2020.
[8] David Berthelot, Nicholas Carlini, Ian Goodfellow, Nicolas Papernot, Avital Oliver, and Colin A Raffel. Mixmatch: A holistic approach to semi-supervised learning. In NeurIPS, 2019.
以上是关于字节跳动获CVPR2021 细粒度图像竞赛双料冠军的主要内容,如果未能解决你的问题,请参考以下文章
CVPR2021竞赛结果出炉,阿里淘系多媒体算法包揽3项国际冠军