Linux内存从0到1学习笔记(六,物理内存初始化之三 --- 物理内存管理数据结构)
Posted 高桐@BILL
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Linux内存从0到1学习笔记(六,物理内存初始化之三 --- 物理内存管理数据结构)相关的知识,希望对你有一定的参考价值。
写在前面
在BootLoader阶段,内存设备的初始化就已经完成。随后把DDR设备容量大小传递给内核。Linux内核的管理实际上是对如内存节点(pglist_data)、内存管理区(zone),mem_map[]数组,页表项(PTE),物理内存Page Frame 页帧,页框号(PFN),物理地址(paddress)等数据结构的管理。
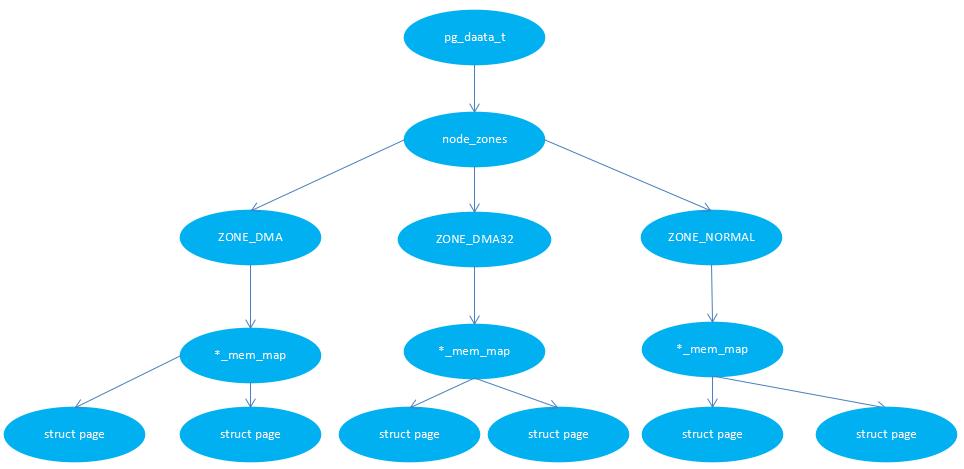
内存以结点为单位,关联到系统中的一个处理器,在内核中即pglist_data(别名pg_data_t)实例。
进一步细分,各个结点又划分内存域;例如,对于可用于(ISA设备的)的DMA操作的内存是有限制的,只有16MB。一个结点常常有三个域,包括ZONE_DMA,ZONE_DMA32,ZONE_NORMAL。
各个内存域都关联了一个数组,用来组织该内存域下的物理内存页(页帧或页框)。对每个页帧都分配了一个struct page实例以及所需的管理数据。
内存节点,内存域,页帧的关系如下图(UMA):
那么接下来我们把前面物理内存初始化过程中所遇到的数据结构,以及数据结构之间的关系进行一个简答的梳理。
一、pglist_data 内存节点
linux_mainline-5.17.0/include/linux/mmzone.h
pglist_data数据结构用来描述一个内存节点的所有资源。UMA架构下,系统只有一个contig_page_data来描述这个内存节点,UNMA则是有一个pglist_data指针数组node_data[]来管理。
/*
* On NUMA machines, each NUMA node would have a pg_data_t to describe
* it's memory layout. On UMA machines there is a single pglist_data which
* describes the whole memory.
*
* Memory statistics and page replacement data structures are maintained on a
* per-zone basis.
*/
typedef struct pglist_data
/*
* node_zones contains just the zones for THIS node. Not all of the
* zones may be populated, but it is the full list. It is referenced by
* this node's node_zonelists as well as other node's node_zonelists.
*/
//一个数组,包含结点中各个内存域的数据结构。
struct zone node_zones[MAX_NR_ZONES];
/*
* node_zonelists contains references to all zones in all nodes.
* Generally the first zones will be references to this node's
* node_zones.
*/
//node_zonelists包含了所有节点下的内存域的引用。其指定了备用结点及其内存域的列表,以便在当前结点没有可用空间时,在备用结点分配内存。
struct zonelist node_zonelists[MAX_ZONELISTS];
//结点中,不同内存域的数目保存在nr_zones中。
int nr_zones; /* number of populated zones in this node */
#ifdef CONFIG_FLATMEM /* means !SPARSEMEM */
//在FLATMEM内存模型下有效,指指向page实例数组的指针,用于描述结点的所有物理内存页。它包含了结点中所有内存域的页。
struct page *node_mem_map;
#ifdef CONFIG_PAGE_EXTENSION
struct page_ext *node_page_ext;
#endif
#endif
#if defined(CONFIG_MEMORY_HOTPLUG) || defined(CONFIG_DEFERRED_STRUCT_PAGE_INIT)
/*
* Must be held any time you expect node_start_pfn,
* node_present_pages, node_spanned_pages or nr_zones to stay constant.
* Also synchronizes pgdat->first_deferred_pfn during deferred page
* init.
*
* pgdat_resize_lock() and pgdat_resize_unlock() are provided to
* manipulate node_size_lock without checking for CONFIG_MEMORY_HOTPLUG
* or CONFIG_DEFERRED_STRUCT_PAGE_INIT.
*
* Nests above zone->lock and zone->span_seqlock
*/
spinlock_t node_size_lock;
#endif
//该节点起始页框号,在UMA架构中总是为0,因为UMA下只有一个结点。
unsigned long node_start_pfn;
//当前所有物理页的个数
unsigned long node_present_pages; /* total number of physical pages */
//所有物理页的大小总和,包括空洞。
unsigned long node_spanned_pages; /* total size of physical page
range, including holes */
//节点ID,表示第几个结点
int node_id;
//交换守护进程(swap daemon)的等待队列
wait_queue_head_t kswapd_wait;
//直接内存回收过程中的进程等待队列
wait_queue_head_t pfmemalloc_wait;
/* workqueues for throttling reclaim for different reasons. */
wait_queue_head_t reclaim_wait[NR_VMSCAN_THROTTLE];
atomic_t nr_writeback_throttled;/* nr of writeback-throttled tasks */
unsigned long nr_reclaim_start; /* nr pages written while throttled
* when throttling started. */
//指向该结点的kswapd进程的task_struct
struct task_struct *kswapd; /* Protected by
mem_hotplug_begin/end() */
//kswap回收页面大小
int kswapd_order;
enum zone_type kswapd_highest_zoneidx;
int kswapd_failures; /* Number of 'reclaimed == 0' runs */
#ifdef CONFIG_COMPACTION
int kcompactd_max_order;
enum zone_type kcompactd_highest_zoneidx;
wait_queue_head_t kcompactd_wait;
struct task_struct *kcompactd;
bool proactive_compact_trigger;
#endif
/*
* This is a per-node reserve of pages that are not available
* to userspace allocations.
*/
//每个节点的保留内存
unsigned long totalreserve_pages;
#ifdef CONFIG_NUMA
/*
* node reclaim becomes active if more unmapped pages exist.
*/
unsigned long min_unmapped_pages;
//该node中可回收slab页面阈值,超过该值才会回收该node内存
unsigned long min_slab_pages;
#endif /* CONFIG_NUMA */
/* Write-intensive fields used by page reclaim */
ZONE_PADDING(_pad1_)
#ifdef CONFIG_DEFERRED_STRUCT_PAGE_INIT
/*
* If memory initialisation on large machines is deferred then this
* is the first PFN that needs to be initialised.
*/
unsigned long first_deferred_pfn;
#endif /* CONFIG_DEFERRED_STRUCT_PAGE_INIT */
#ifdef CONFIG_TRANSPARENT_HUGEPAGE
struct deferred_split deferred_split_queue;
#endif
/* Fields commonly accessed by the page reclaim scanner */
/*
* NOTE: THIS IS UNUSED IF MEMCG IS ENABLED.
*
* Use mem_cgroup_lruvec() to look up lruvecs.
*/
//LRU链表管理结构
struct lruvec __lruvec;
unsigned long flags;
ZONE_PADDING(_pad2_)
/* Per-node vmstats */
struct per_cpu_nodestat __percpu *per_cpu_nodestats;
atomic_long_t vm_stat[NR_VM_NODE_STAT_ITEMS];
pg_data_t;1.1 contig_page_data
extern struct pglist_data contig_page_data;
static inline struct pglist_data *NODE_DATA(int nid)
return &contig_page_data;
1.2 node_data[]
extern struct pglist_data *node_data[];1.3 zonelist
/*
* One allocation request operates on a zonelist. A zonelist
* is a list of zones, the first one is the 'goal' of the
* allocation, the other zones are fallback zones, in decreasing
* priority.
*
* To speed the reading of the zonelist, the zonerefs contain the zone index
* of the entry being read. Helper functions to access information given
* a struct zoneref are
*
* zonelist_zone() - Return the struct zone * for an entry in _zonerefs
* zonelist_zone_idx() - Return the index of the zone for an entry
* zonelist_node_idx() - Return the index of the node for an entry
*/
struct zonelist
struct zoneref _zonerefs[MAX_ZONES_PER_ZONELIST + 1];
;1.4 zoneref
/*
* This struct contains information about a zone in a zonelist. It is stored
* here to avoid dereferences into large structures and lookups of tables
*/
struct zoneref
struct zone *zone; /* Pointer to actual zone */
int zone_idx; /* zone_idx(zoneref->zone) */
;
二、zone 内存管理区
2.1 zone type
通用内存管理要应对各种不同的架构,X86,ARM,MIPS...,为了减少复杂度,只需要挑自己架构相关的。目前我使用的平台,只配置了ZONE_DMA和ZONE_NORMAL。
以ubuntu18.04为例:

enum zone_type
/*
* ZONE_DMA and ZONE_DMA32 are used when there are peripherals not able
* to DMA to all of the addressable memory (ZONE_NORMAL).
* On architectures where this area covers the whole 32 bit address
* space ZONE_DMA32 is used. ZONE_DMA is left for the ones with smaller
* DMA addressing constraints. This distinction is important as a 32bit
* DMA mask is assumed when ZONE_DMA32 is defined. Some 64-bit
* platforms may need both zones as they support peripherals with
* different DMA addressing limitations.
*/
#ifdef CONFIG_ZONE_DMA
//该区域的物理页面专门供I/O设备的DMA使用。之所以需要单独管理DMA的物理页面,是因为DMA使用物理地址访问内存,不经过MMU,并且需要连续的缓冲区,所以为了能够提供物理上连续的缓冲区,必须从物理地址空间专门划分一段区域用于DMA。
ZONE_DMA,
#endif
#ifdef CONFIG_ZONE_DMA32
//标记了使用32位地址字可寻址,适合DMA的内存域。在32位计算机,该内存域为空,即0MB。64位计算机上可能从0到4G。
ZONE_DMA32,
#endif
/*
* Normal addressable memory is in ZONE_NORMAL. DMA operations can be
* performed on pages in ZONE_NORMAL if the DMA devices support
* transfers to all addressable memory.
*/
//该区域的物理页面是内核能够直接使用的
ZONE_NORMAL,
#ifdef CONFIG_HIGHMEM
/*
* A memory area that is only addressable by the kernel through
* mapping portions into its own address space. This is for example
* used by i386 to allow the kernel to address the memory beyond
* 900MB. The kernel will set up special mappings (page
* table entries on i386) for each page that the kernel needs to
* access.
*/
ZONE_HIGHMEM,
#endif
/*
* ZONE_MOVABLE is similar to ZONE_NORMAL, except that it contains
* movable pages with few exceptional cases described below. Main use
* cases for ZONE_MOVABLE are to make memory offlining/unplug more
* likely to succeed, and to locally limit unmovable allocations - e.g.,
* to increase the number of THP/huge pages. Notable special cases are:
*
* 1. Pinned pages: (long-term) pinning of movable pages might
* essentially turn such pages unmovable. Therefore, we do not allow
* pinning long-term pages in ZONE_MOVABLE. When pages are pinned and
* faulted, they come from the right zone right away. However, it is
* still possible that address space already has pages in
* ZONE_MOVABLE at the time when pages are pinned (i.e. user has
* touches that memory before pinning). In such case we migrate them
* to a different zone. When migration fails - pinning fails.
* 2. memblock allocations: kernelcore/movablecore setups might create
* situations where ZONE_MOVABLE contains unmovable allocations
* after boot. Memory offlining and allocations fail early.
* 3. Memory holes: kernelcore/movablecore setups might create very rare
* situations where ZONE_MOVABLE contains memory holes after boot,
* for example, if we have sections that are only partially
* populated. Memory offlining and allocations fail early.
* 4. PG_hwpoison pages: while poisoned pages can be skipped during
* memory offlining, such pages cannot be allocated.
* 5. Unmovable PG_offline pages: in paravirtualized environments,
* hotplugged memory blocks might only partially be managed by the
* buddy (e.g., via XEN-balloon, Hyper-V balloon, virtio-mem). The
* parts not manged by the buddy are unmovable PG_offline pages. In
* some cases (virtio-mem), such pages can be skipped during
* memory offlining, however, cannot be moved/allocated. These
* techniques might use alloc_contig_range() to hide previously
* exposed pages from the buddy again (e.g., to implement some sort
* of memory unplug in virtio-mem).
* 6. ZERO_PAGE(0), kernelcore/movablecore setups might create
* situations where ZERO_PAGE(0) which is allocated differently
* on different platforms may end up in a movable zone. ZERO_PAGE(0)
* cannot be migrated.
* 7. Memory-hotplug: when using memmap_on_memory and onlining the
* memory to the MOVABLE zone, the vmemmap pages are also placed in
* such zone. Such pages cannot be really moved around as they are
* self-stored in the range, but they are treated as movable when
* the range they describe is about to be offlined.
*
* In general, no unmovable allocations that degrade memory offlining
* should end up in ZONE_MOVABLE. Allocators (like alloc_contig_range())
* have to expect that migrating pages in ZONE_MOVABLE can fail (even
* if has_unmovable_pages() states that there are no unmovable pages,
* there can be false negatives).
*/
// 可移动区域:伪内存区域,用来防止内存碎片
ZONE_MOVABLE,
#ifdef CONFIG_ZONE_DEVICE
// 为支持持久内存(热插拔增加的内存区域)
ZONE_DEVICE,
#endif
__MAX_NR_ZONES
;2.2 zone
struct zone
/* Read-mostly fields */
/* zone watermarks, access with *_wmark_pages(zone) macros */
//zone水位
unsigned long _watermark[NR_WMARK];
//这个实际上是控制内存紧张时的一种刻度
unsigned long watermark_boost;
unsigned long nr_reserved_highatomic;
/*
* We don't know if the memory that we're going to allocate will be
* freeable or/and it will be released eventually, so to avoid totally
* wasting several GB of ram we must reserve some of the lower zone
* memory (otherwise we risk to run OOM on the lower zones despite
* there being tons of freeable ram on the higher zones). This array is
* recalculated at runtime if the sysctl_lowmem_reserve_ratio sysctl
* changes.
*/
// zone中预留的内存,系统内存不足时,可以使用这些保留的内存来做一些操作,比如使用保留内存的进程释放更多内存。
long lowmem_reserve[MAX_NR_ZONES];
#ifdef CONFIG_NUMA
int node;
#endif
//指向内存节点的pglist_data实例
struct pglist_data *zone_pgdat;
//每CPU保留一些页面,避免自旋锁冲突
struct per_cpu_pages __percpu *per_cpu_pageset;
struct per_cpu_zonestat __percpu *per_cpu_zonestats;
/*
* the high and batch values are copied to individual pagesets for
* faster access
*/
int pageset_high;
int pageset_batch;
#ifndef CONFIG_SPARSEMEM
/*
* Flags for a pageblock_nr_pages block. See pageblock-flags.h.
* In SPARSEMEM, this map is stored in struct mem_section
*/
unsigned long *pageblock_flags;
#endif /* CONFIG_SPARSEMEM */
/* zone_start_pfn == zone_start_paddr >> PAGE_SHIFT */
//该内存域起始页帧地址
unsigned long zone_start_pfn;
/*
* spanned_pages is the total pages spanned by the zone, including
* holes, which is calculated as:
* spanned_pages = zone_end_pfn - zone_start_pfn;
*
* present_pages is physical pages existing within the zone, which
* is calculated as:
* present_pages = spanned_pages - absent_pages(pages in holes);
*
* present_early_pages is present pages existing within the zone
* located on memory available since early boot, excluding hotplugged
* memory.
*
* managed_pages is present pages managed by the buddy system, which
* is calculated as (reserved_pages includes pages allocated by the
* bootmem allocator):
* managed_pages = present_pages - reserved_pages;
*
* cma pages is present pages that are assigned for CMA use
* (MIGRATE_CMA).
*
* So present_pages may be used by memory hotplug or memory power
* management logic to figure out unmanaged pages by checking
* (present_pages - managed_pages). And managed_pages should be used
* by page allocator and vm scanner to calculate all kinds of watermarks
* and thresholds.
*
* Locking rules:
*
* zone_start_pfn and spanned_pages are protected by span_seqlock.
* It is a seqlock because it has to be read outside of zone->lock,
* and it is done in the main allocator path. But, it is written
* quite infrequently.
*
* The span_seq lock is declared along with zone->lock because it is
* frequently read in proximity to zone->lock. It's good to
* give them a chance of being in the same cacheline.
*
* Write access to present_pages at runtime should be protected by
* mem_hotplug_begin/end(). Any reader who can't tolerant drift of
* present_pages should get_online_mems() to get a stable value.
*/
//该zone中被伙伴系统管理的页面数量
atomic_long_t managed_pages;
//该zone包含的总页数,包含空洞
unsigned long spanned_pages;
//该zone包含的总页数,不包含空洞
unsigned long present_pages;
#if defined(CONFIG_MEMORY_HOTPLUG)
unsigned long present_early_pages;
#endif
#ifdef CONFIG_CMA
unsigned long cma_pages;
#endif
//内存域名字,如"DMA", "NROMAL"
const char *name;
#ifdef CONFIG_MEMORY_ISOLATION
/*
* Number of isolated pageblock. It is used to solve incorrect
* freepage counting problem due to racy retrieving migratetype
* of pageblock. Protected by zone->lock.
*/
unsigned long nr_isolate_pageblock;
#endif
#ifdef CONFIG_MEMORY_HOTPLUG
/* see spanned/present_pages for more description */
seqlock_t span_seqlock;
#endif
int initialized;
/* Write-intensive fields used from the page allocator */
ZONE_PADDING(_pad1_)
/* free areas of different sizes */
//页面使用状态的信息,伙伴分配系统用来分配的,每个元素对应不同阶page大小目前系统上有11种不同大小的页面,从2^0 - 2^10,即4k-4M大小的页面
struct free_area free_area[MAX_ORDER];
/* zone flags, see below */
unsigned long flags;
/* Primarily protects free_area */
//用来保护对free_area区域的访问.
spinlock_t lock;
/* Write-intensive fields used by compaction and vmstats. */
ZONE_PADDING(_pad2_)
/*
* When free pages are below this point, additional steps are taken
* when reading the number of free pages to avoid per-cpu counter
* drift allowing watermarks to be breached
*/
unsigned long percpu_drift_mark;
#if defined CONFIG_COMPACTION || defined CONFIG_CMA
/* pfn where compaction free scanner should start */
unsigned long compact_cached_free_pfn;
/* pfn where compaction migration scanner should start */
unsigned long compact_cached_migrate_pfn[ASYNC_AND_SYNC];
unsigned long compact_init_migrate_pfn;
unsigned long compact_init_free_pfn;
#endif
#ifdef CONFIG_COMPACTION
/*
* On compaction failure, 1<<compact_defer_shift compactions
* are skipped before trying again. The number attempted since
* last failure is tracked with compact_considered.
* compact_order_failed is the minimum compaction failed order.
*/
unsigned int compact_considered;
unsigned int compact_defer_shift;
int compact_order_failed;
#endif
#if defined CONFIG_COMPACTION || defined CONFIG_CMA
/* Set to true when the PG_migrate_skip bits should be cleared */
bool compact_blockskip_flush;
#endif
bool contiguous;
ZONE_PADDING(_pad3_)
/* Zone statistics */
atomic_long_t vm_stat[NR_VM_ZONE_STAT_ITEMS];
atomic_long_t vm_numa_event[NR_VM_NUMA_EVENT_ITEMS];
____cacheline_internodealigned_in_smp;
三、Page 页帧
linux_mainline-5.17.0/include/linux/mm_types.h
/*
* Each physical page in the system has a struct page associated with
* it to keep track of whatever it is we are using the page for at the
* moment. Note that we have no way to track which tasks are using
* a page, though if it is a pagecache page, rmap structures can tell us
* who is mapping it.
*
* If you allocate the page using alloc_pages(), you can use some of the
* space in struct page for your own purposes. The five words in the main
* union are available, except for bit 0 of the first word which must be
* kept clear. Many users use this word to store a pointer to an object
* which is guaranteed to be aligned. If you use the same storage as
* page->mapping, you must restore it to NULL before freeing the page.
*
* If your page will not be mapped to userspace, you can also use the four
* bytes in the mapcount union, but you must call page_mapcount_reset()
* before freeing it.
*
* If you want to use the refcount field, it must be used in such a way
* that other CPUs temporarily incrementing and then decrementing the
* refcount does not cause problems. On receiving the page from
* alloc_pages(), the refcount will be positive.
*
* If you allocate pages of order > 0, you can use some of the fields
* in each subpage, but you may need to restore some of their values
* afterwards.
*
* SLUB uses cmpxchg_double() to atomically update its freelist and counters.
* That requires that freelist & counters in struct slab be adjacent and
* double-word aligned. Because struct slab currently just reinterprets the
* bits of struct page, we align all struct pages to double-word boundaries,
* and ensure that 'freelist' is aligned within struct slab.
*/
#ifdef CONFIG_HAVE_ALIGNED_STRUCT_PAGE
#define _struct_page_alignment __aligned(2 * sizeof(unsigned long))
#else
#define _struct_page_alignment
#endif
struct page
//原子标志,有些情况下会异步更新。
unsigned long flags; /* Atomic flags, some possibly
* updated asynchronously */
/*
* Five words (20/40 bytes) are available in this union.
* WARNING: bit 0 of the first word is used for PageTail(). That
* means the other users of this union MUST NOT use the bit to
* avoid collision and false-positive PageTail().
*/
union
struct /* Page cache and anonymous pages */
/**
* @lru: Pageout list, eg. active_list protected by
* lruvec->lru_lock. Sometimes used as a generic list
* by the page owner.
*/
struct list_head lru;
/* See page-flags.h for PAGE_MAPPING_FLAGS */
//mapping指定了页帧所在的地址空间。有三种含义:
//mapping = 0,说明该page属于swap cache;
//mapping != 0,bit[0] = 0,说明该page属于页缓存或文件映射,mapping指向文件的地址空间address_space;
//mapping != 0,bit[0] != 0,说明该page为匿名映射,mapping指向struct anon_vma对象
struct address_space *mapping;
pgoff_t index; /* Our offset within mapping. */
/**
* @private: Mapping-private opaque data.
* Usually used for buffer_heads if PagePrivate.
* Used for swp_entry_t if PageSwapCache.
* Indicates order in the buddy system if PageBuddy.
*/
//由映射私有,不透明数据;如果设置PagePrivate,通常用于buffer_heads;如果设置了PageSwapCache,则用于swp_entry_t;如果设置了PG_buddy,则用于表示伙伴系统中的阶。
unsigned long private;
;
struct /* page_pool used by netstack */
/**
* @pp_magic: magic value to avoid recycling non
* page_pool allocated pages.
*/
unsigned long pp_magic;
struct page_pool *pp;
unsigned long _pp_mapping_pad;
unsigned long dma_addr;
union
/**
* dma_addr_upper: might require a 64-bit
* value on 32-bit architectures.
*/
unsigned long dma_addr_upper;
/**
* For frag page support, not supported in
* 32-bit architectures with 64-bit DMA.
*/
atomic_long_t pp_frag_count;
;
;
struct /* Tail pages of compound page */
unsigned long compound_head; /* Bit zero is set */
/* First tail page only */
unsigned char compound_dtor;
unsigned char compound_order;
atomic_t compound_mapcount;
unsigned int compound_nr; /* 1 << compound_order */
;
struct /* Second tail page of compound page */
unsigned long _compound_pad_1; /* compound_head */
atomic_t hpage_pinned_refcount;
/* For both global and memcg */
struct list_head deferred_list;
;
struct /* Page table pages */
unsigned long _pt_pad_1; /* compound_head */
pgtable_t pmd_huge_pte; /* protected by page->ptl */
unsigned long _pt_pad_2; /* mapping */
union
struct mm_struct *pt_mm; /* x86 pgds only */
atomic_t pt_frag_refcount; /* powerpc */
;
#if ALLOC_SPLIT_PTLOCKS
spinlock_t *ptl;
#else
spinlock_t ptl;
#endif
;
struct /* ZONE_DEVICE pages */
/** @pgmap: Points to the hosting device page map. */
struct dev_pagemap *pgmap;
void *zone_device_data;
/*
* ZONE_DEVICE private pages are counted as being
* mapped so the next 3 words hold the mapping, index,
* and private fields from the source anonymous or
* page cache page while the page is migrated to device
* private memory.
* ZONE_DEVICE MEMORY_DEVICE_FS_DAX pages also
* use the mapping, index, and private fields when
* pmem backed DAX files are mapped.
*/
;
/** @rcu_head: You can use this to free a page by RCU. */
struct rcu_head rcu_head;
;
union /* This union is 4 bytes in size. */
/*
* If the page can be mapped to userspace, encodes the number
* of times this page is referenced by a page table.
*/
//内存管理子系统中映射的页表项计数,用于表示页是否已经映射,还用于限制逆向映射搜索。
atomic_t _mapcount;
/*
* If the page is neither PageSlab nor mappable to userspace,
* the value stored here may help determine what this page
* is used for. See page-flags.h for a list of page types
* which are currently stored here.
*/
unsigned int page_type;
;
/* Usage count. *DO NOT USE DIRECTLY*. See page_ref.h */
atomic_t _refcount;
#ifdef CONFIG_MEMCG
unsigned long memcg_data;
#endif
/*
* On machines where all RAM is mapped into kernel address space,
* we can simply calculate the virtual address. On machines with
* highmem some memory is mapped into kernel virtual memory
* dynamically, so we need a place to store that address.
* Note that this field could be 16 bits on x86 ... ;)
*
* Architectures with slow multiplication can define
* WANT_PAGE_VIRTUAL in asm/page.h
*/
#if defined(WANT_PAGE_VIRTUAL)
void *virtual; /* Kernel virtual address (NULL if
not kmapped, ie. highmem) */
#endif /* WANT_PAGE_VIRTUAL */
#ifdef LAST_CPUPID_NOT_IN_PAGE_FLAGS
int _last_cpupid;
#endif
_struct_page_alignment;以上是关于Linux内存从0到1学习笔记(六,物理内存初始化之三 --- 物理内存管理数据结构)的主要内容,如果未能解决你的问题,请参考以下文章
Linux内存从0到1学习笔记(六,物理内存初始化之三 --- 物理内存管理数据结构)
Linux内存从0到1学习笔记(六,物理内存初始化之二 --- 内存模型)
Linux内存从0到1学习笔记(6.4,物理内存初始化之预留内存)
Linux内存从0到1学习笔记(6.8,物理内存初始化之buddy伙伴系统)