Python爬取斗图啦,妈妈再也不会担心我无图可刷了
Posted 小_源
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python爬取斗图啦,妈妈再也不会担心我无图可刷了相关的知识,希望对你有一定的参考价值。
本文同步发表于我的微信公众号,扫一扫文章底部的二维码或在微信搜索 极客导航 即可关注,每个工作日都有文章更新。
一、概况
我们终于把Request网络请求库和Xpath解析库的基本用法学的差不多了,终于可以爬一些自己想爬的网站了。那我们拿什么网站做入门案例呢?好像刷图表情挺火的,那么从爬取表情的网站入手,爬取我们自己想要的表情,做一个刷图达人。我想让我的硬盘这样:

因为我太想进步了。

二、分析
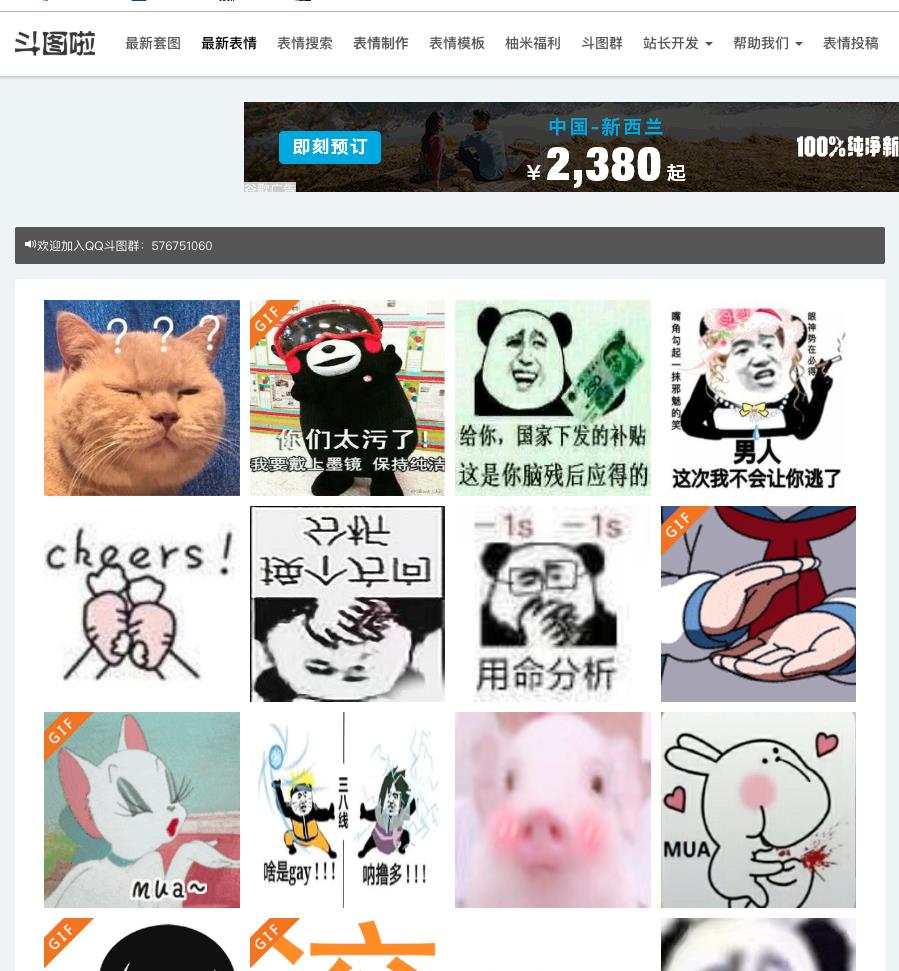
我们爬取一个叫斗图啦(https://www.doutula.com/photo/list/)的网站,来爬取他们的最新表情。
-
URL分析
因为表情有很多,网站都会做分页处理,首先我们先分析出URL地址的变化,就是下面这个样子:
第一页:https://www.doutula.com/photo/list/?page=1
第二页:https://www.doutula.com/photo/list/?page=2
第三页:https://www.doutula.com/photo/list/?page=3 -
表情图片地址提取分析
通过查看浏览器源代码,我们大概发现了图片所在的标签以及图片的地址。
注意:有的图片是GIF类型,而有的图片是JPG类型。
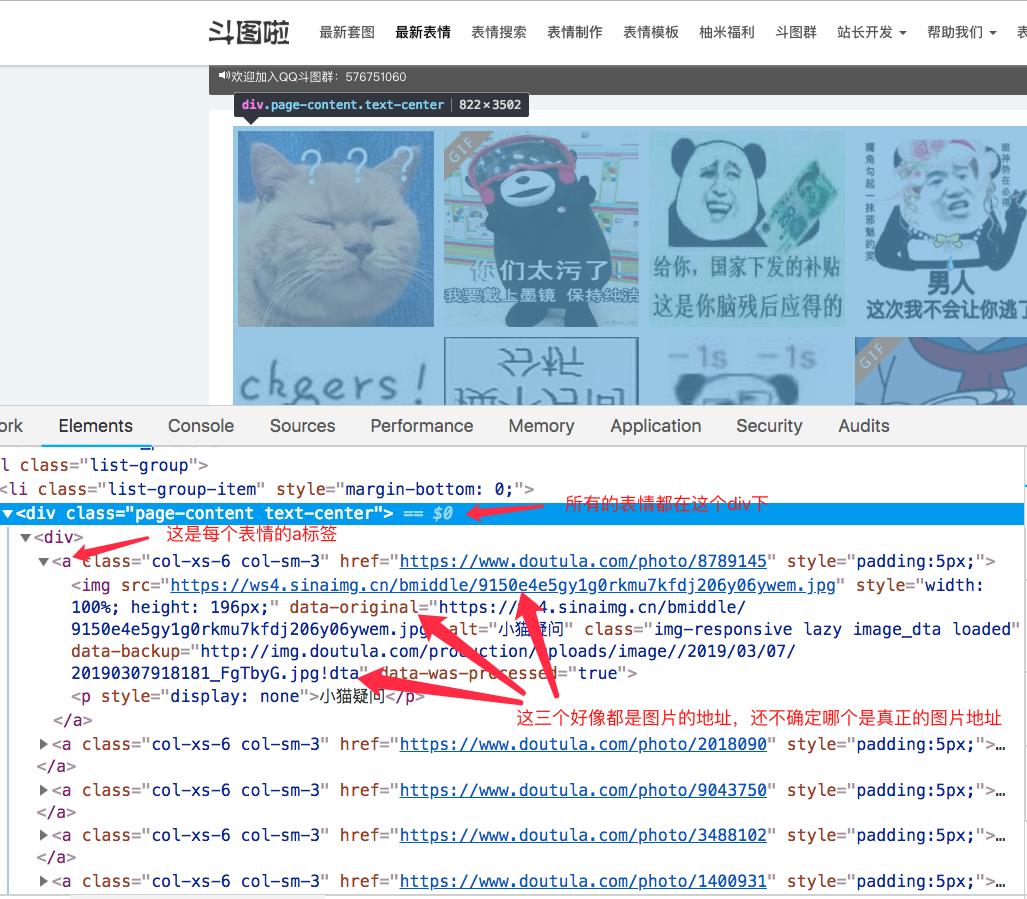
通过在浏览器Xpath插件分析,提取了下面图片地址:

但是我们发现里面有些是静态图片资源,我们在上面也看到图片地址有三个,那么我们在来看看其他属性是否能提取出网络图片地址。

通过用data-original属性提取,这次我们发现里面没了静态资源,都是网络图片地址,这个好像可以用。
三、实现
下面是大概逻辑实现:
import requests
from lxml import etree
class DouTuLaSpider():
def __init__(self):
# 默认第一页开始
self.pn = 1
# 默认URL
self.url = 'https://www.doutula.com/photo/list/?page='
# 添加请求头,模拟浏览器
self.headers =
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_2) AppleWebKit/537.36 (Khtml, like Gecko) Chrome/71.0.3578.98 Safari/537.36'
# 发起请求
def loadpage(self):
# 拼接请求地址
req_url = self.url + str(self.pn) # https://www.doutula.com/photo/list/?page=1
# 发起请求
reponse = requests.get(url=req_url, headers=self.headers)
# 用UTF-8进行编码
content = reponse.content.decode('utf-8')
# 构造xpath解析对象
html = etree.HTML(content)
# 先取出这个div下面的所有a标签
a_list = html.xpath('//div[@class="page-content text-center"]//a')
for a in a_list:
# 在从当前的a标签取下面的img标签的data-original属性,取返回列表的第一个值。注意前面有个.
img_url = a.xpath('./img/@data-original')[0]
print(img_url)
if __name__ == "__main__":
dtls = DouTuLaSpider()
dtls.loadpage()
#打印
https://ws4.sinaimg.cn/bmiddle/9150e4e5gy1g0sad0axupj204t0410sj.jpg
https://ws4.sinaimg.cn/bmiddle/9150e4e5gy1g0sad1qossg206o06ca9x.gif
https://ws4.sinaimg.cn/bmiddle/9150e4e5gy1g0sacyw5wwj207806mmxc.jpg
https://ws1.sinaimg.cn/bmiddle/9150e4e5gy1g0sacxbehoj205d05dq2w.jpg
https://ws4.sinaimg.cn/bmiddle/9150e4e5gy1g0sacu8fy7j20b40b40sv.jpg
https://ws1.sinaimg.cn/bmiddle/9150e4e5gy1g0sacqc75fj205i058aaz.jpg
https://ws3.sinaimg.cn/bmiddle/9150e4e5gy1g0sacso1lbj20u00tamyx.jpg
https://ws1.sinaimg.cn/bmiddle/9150e4e5gy1g0sacod9zzg206o06o40v.gif
https://ws4.sinaimg.cn/bmiddle/9150e4e5gy1g0sachx559j20zk0k0wgo.jpg
......
第一页所有的表情图片地址,我们已经全部爬取下来了,接下来就是把爬取图片地址通过发送网络请求下载到本地,这个时候我们需要考虑两个问题:
- 图片的名字怎么命名?

我们在去看了一下源代码,发现alt属性的值可以当做图片的名字,所以在爬取图片地址的时候也需要把alt属性的值提取出来。 - 图片的后缀是什么?
因为我们有图片的网络地址,我们可以通过字符串截取,把图片地址的后缀截取下来。
两个问题实现:
import requests
from lxml import etree
import os
class DouTuLaSpider():
def __init__(self):
# 默认第一页开始
self.pn = 1
# 默认URL
self.url = 'https://www.doutula.com/photo/list/?page='
# 添加请求头,模拟浏览器
self.headers =
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'
# 发起请求
def loadpage(self):
# 拼接请求地址
req_url = self.url + str(self.pn) # https://www.doutula.com/photo/list/?page=1
# 发起请求
reponse = requests.get(url=req_url, headers=self.headers)
# 用UTF-8进行编码
content = reponse.content.decode('utf-8')
# 构造xpath解析对象
html = etree.HTML(content)
# 先取出这个div下面的所有a标签
a_list = html.xpath('//div[@class="page-content text-center"]//a')
for a in a_list:
# 在从当前的a标签取下面的img标签的data-original属性,取返回列表的第一个值。注意前面有个.
img_url = a.xpath('./img/@data-original')[0]
# 图片名字
img_name = a.xpath('./img/@alt')[0]
print(img_url)
#下载图片
self.loadimg(img_url, img_name)
#发起图片请求
def loadimg(self, img_url, img_name):
folder = 'doutu'#本地文件夹名字
if not os.path.exists(folder):#如果文件夹不存在
os.mkdir(folder)#创建文件夹
# 拼接本地图片路径
path = folder + "/" + img_name + img_url[-4::]
# 发起图片请求
reponse = requests.get(url=img_url, headers=self.headers)
# 图片二进制数据
content = reponse.content
#保存图片
self.saveimg(path,content)
#保存图片
def saveimg(self,path,content):
with open(path,'wb') as f:
f.write(content)
if __name__ == "__main__":
dtls = DouTuLaSpider()
dtls.loadpage()
最终的我的本地文件夹,装了许多我日思夜想的表情。这只是第一页,我们需要硬盘被装红的那种感觉,我们要实现多页爬取,先用循环代替吧~
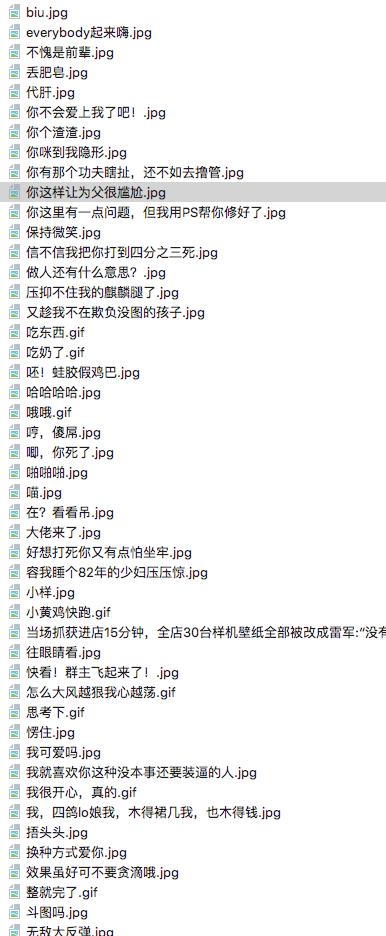
我们在代码最下面加了一个循环,把每次的数值赋值给页码。这样就会不停的发送请求了。
if __name__ == "__main__":
dtls = DouTuLaSpider()
for i in range(1,100):#1-100页
print('爬取第%d页'%i)
dtls.pn = i #把每页赋值给pn
dtls.loadpage()
不爬了,不爬了,图片太多。我的硬盘好像有点装不下了,最终我们让妈妈不用担心了。
四、总结
我们用一个简单的例子,入门了爬虫。爬虫入门相对比较简单,但是在爬取的时候也许我们需要考虑的几个点:
-
URL地址怎么变化?(动态网站先不考虑)
-
提取内容在哪里?(先用xpath大概获取位置)
-
请求的网站源代码跟浏览器里面的源代码是否有区别(以请求下来的源码为准)
-
源码
欢迎关注我的公众号,我们一起学习。

以上是关于Python爬取斗图啦,妈妈再也不会担心我无图可刷了的主要内容,如果未能解决你的问题,请参考以下文章