不用正则表达式,爬取斗图啦
Posted thloveyl
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了不用正则表达式,爬取斗图啦相关的知识,希望对你有一定的参考价值。
title: Python-爬取图片
date: 2019-04-17 23:18:24
tags: Python
这是之前部署hexo时候写的爬取斗图啦网站,目前最新的爬取图片文章:https://www.cnblogs.com/thloveyl/p/12248334.html
Requests爬取图片
import time
import requests
import urllib.request
class getRequests:
# 在text获取响应文本时可采用正则表达式,筛选出图片的url、名字,用拆分算是违背了Python语法简洁。
def getImagePath(self):
#斗图啦不变的部分url
url = 'https://www.doutula.com/photo/list/?page='
#计数
sum = 0
# 获取到第一页到2327页的所有图片
for i in range(1,2328):
#拼接url
print(url+str(i))
#发送请求获取响应的文本
reponse = requests.get(url+str(i))
retext = reponse.text
#将响应文本拆分
reponseList = retext.split('data-original="')
# print(reponseList)
#取出url那部分
imageUrl = reponseList[1:len(reponseList)-1]
print('当前页数:%d' % i)
for x in imageUrl:
#图片url
iurl= x.split('" alt="')
imageUrl = iurl[0]
# print('图片URL:%s'%imageUrl)
#图片名称
imageName = iurl[1].split('"')[0]
#防止图片因为包含以下不能命名的字符,报错。
noContanins = ['?', '*', ':', '"', '<', '>','\\', '/', '|']
for noC in noContanins:
if imageName.__contains__(noC):
#替换字符
print(noC)
imageName = imageName.replace(noC,'')
#图片后缀
imageType = imageUrl.split('!')[0]
#逆向拆分
imageType = imageType.rsplit('.')
#取最后一个.后面的字母作为格式
imageType = imageType[len(imageType)-1]
# 替换null的格式
if imageType == 'null':
imageType = 'jpg'
# 如果遇见错误就continue:进入下次循环
try:
# 设置保存路径 - 该文件夹需要已存在
path = ('d:doutula\\'+ imageName+'.' + imageType)
urllib.request.urlretrieve(imageUrl, path)
sum += 1
except:
continue
print('下载至%s || 已下载文件数:%d张。'%(path,sum))
print('总共爬取%d张图片'%sum)
if __name__ == '__main__':
# 获取当前时间
print("开始: ", time.strftime('%Y.%m.%d %H:%M:%S ', time.localtime(time.time())))
getRequests().getImagePath()
print("完成: ", time.strftime('%Y.%m.%d %H:%M:%S ', time.localtime(time.time())))
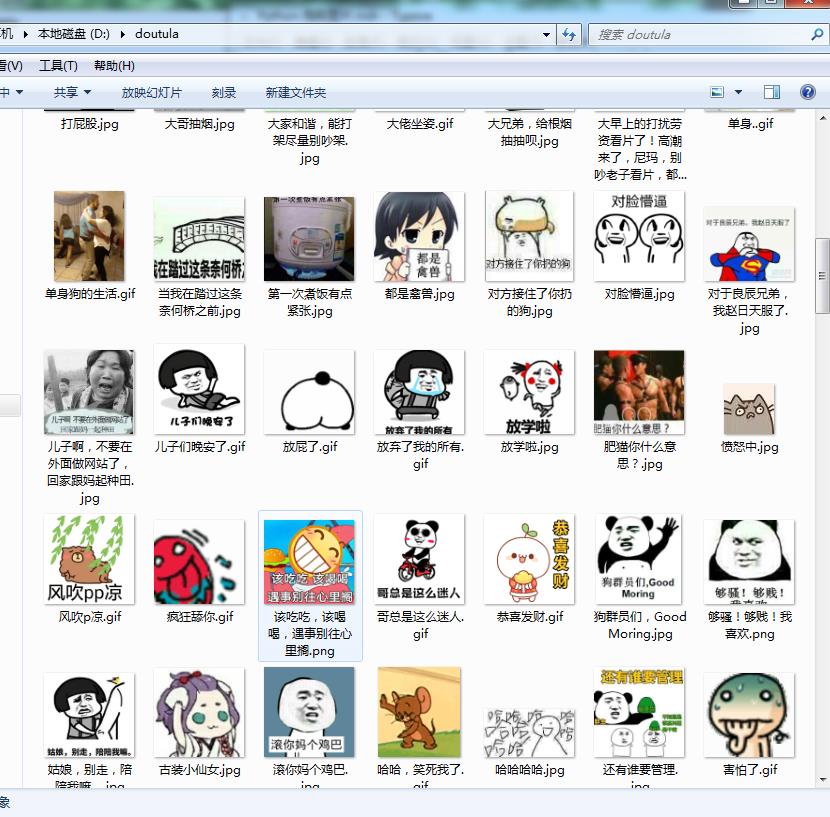
此处没有运用正则表达式,违背了Python代码简洁的宗旨、后续学习到正则表达式时再进行重构。
PS:最新的使用了正则表达式代替了提取链接的冗余代码:https://www.cnblogs.com/thloveyl/p/12248334.html
本文只做记录,如有错误,欢迎留言纠正!
以上是关于不用正则表达式,爬取斗图啦的主要内容,如果未能解决你的问题,请参考以下文章