Selenium自动化测试
Posted 任我驰骋°
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Selenium自动化测试相关的知识,希望对你有一定的参考价值。
Selenium自动化测试
一、为什么要Python自动化脚本
- 突破效率瓶颈,同时降低人力成本(注意不能把降低人力成本放在核心位置);
- 降低人为错误率,规避因为人的疲劳和惯性思维以及投机取巧导致的错误;
- 提升执行效率,以及应对高强度连轴转任务,搞定长时间的系统稳定性测试和高并发场景的压力测试;循序渐进,打好基础。
二、Selenium自动化测试工具
1.自动化测试工具
性能自动化测试工具:loadrunner(UI) jmeter(接口)
APP自动化测试工具:appium Macaca
UI自动化测试工具:selenium
selenium的特点:
(1)免费
(2)轻巧,占用内存少
(3)支持多语言 Python java ruby C# javascript
(4)支持多浏览器 Chrome Firefox edge Opear Safari IE等
(5)支持分布式测试 selenium Grid
UI 自动化
在项目后期介入,等到系统功能稳定的时候开始介入的。
接口自动化
在接口完成后就可以介入,项目中期介入
jmeter postman soupUI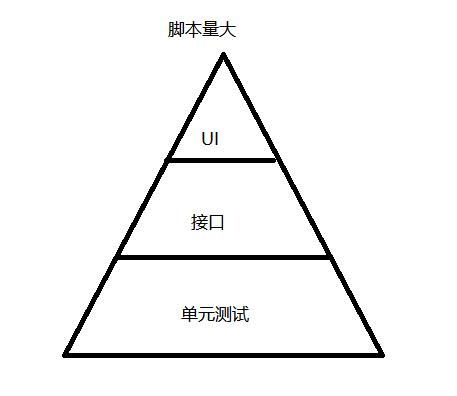
2.自动化测试的优势
回归测试 兼容性测试(浏览器的兼容性)
如果一个脚本它的重复利用率越高,它的价值就会越大,节约了人力成本,节约了各种资源
测试量大不出错
3.如何实施自动化测试
自动化测试的时机:等到系统的功能稳定之后做自动化测试
适合做自动化测试的项目:项目周期比较长
- 分析:总体把握系统逻辑,分析出系统的核心体系架构。
- 设计:设计测试用例,测试用例要足够明确和清晰,覆盖面广而精
- 实现:实现脚本,有两个要求一是断言,二是合理的运用参数化。
- 执行:执行脚本远远没有我们想象中那么简单。脚本执行过程中的异常需要我们仔细的去分析原
因。 - 总结:测试结果的分析,和测试过程的总结是自动化测试的关键。
- 维护:自动化测试脚本的维护是一个难以解决但又必须要解决的问题。
- 分析:在自动化测试过程中深刻的分析自动化用例的覆盖风险和脚本维护的成本。
4.selenium工具
selenium1.0 selenium RC selenium IDE selenium Grid
thougthworks 前端 JavaScript库 环境沙箱问题 浏览器拦截
selenium RC

selenium IDE 录制自动化脚本的工具
selenium grid 进行分布式测试的
selenium 2.0
selenium 1.0 + webdriver 浏览器的驱动
Google Simon
webdriver原理:
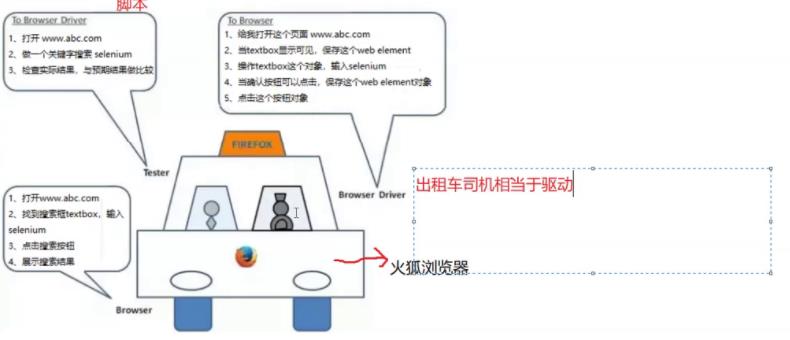
selenium edge Safari 原生驱动
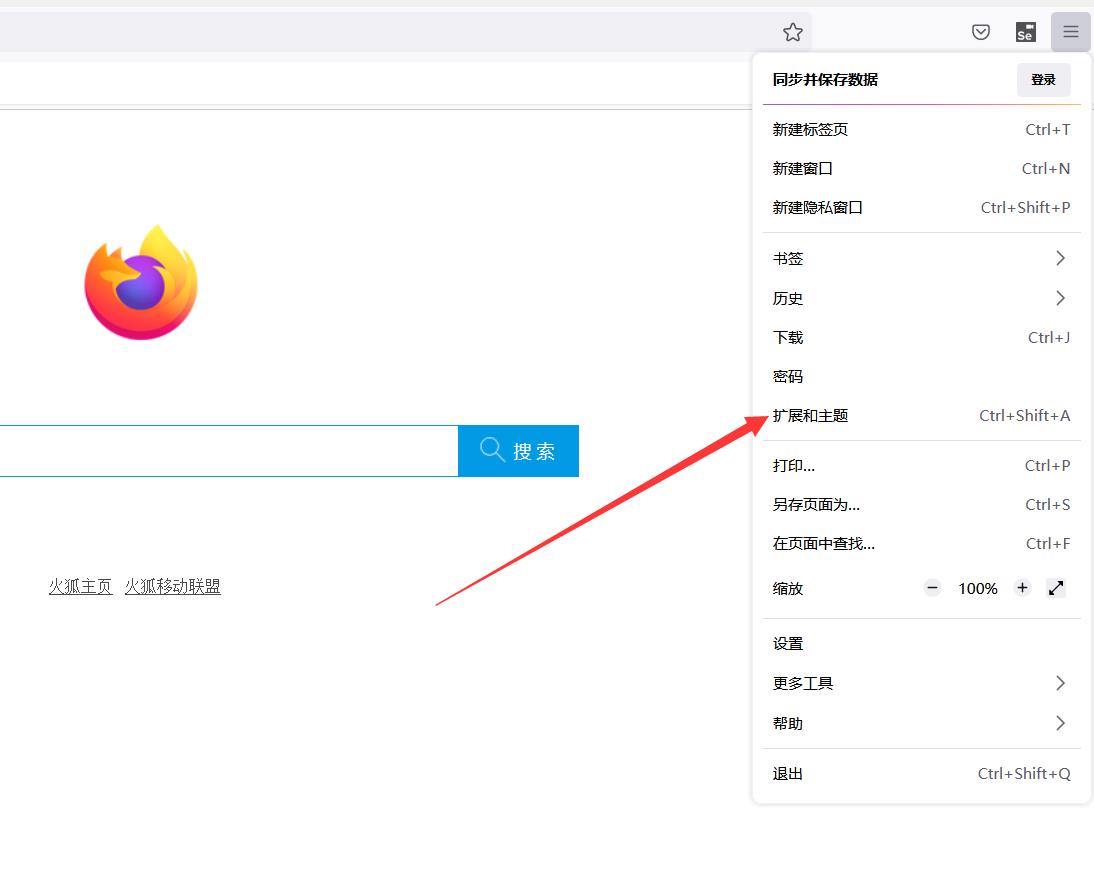
三、使用selenium IDE录制脚本
首先安装火狐浏览器,打开扩展选项
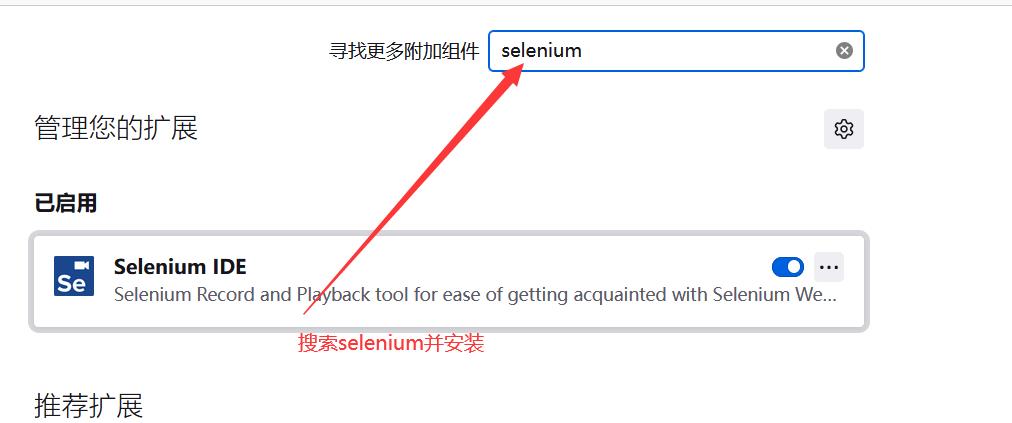
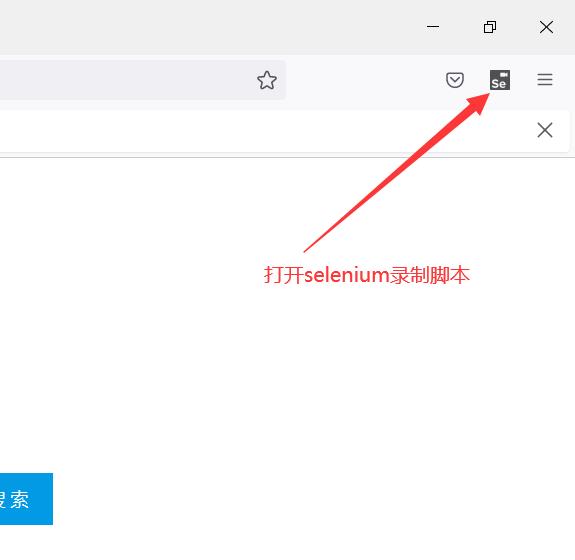
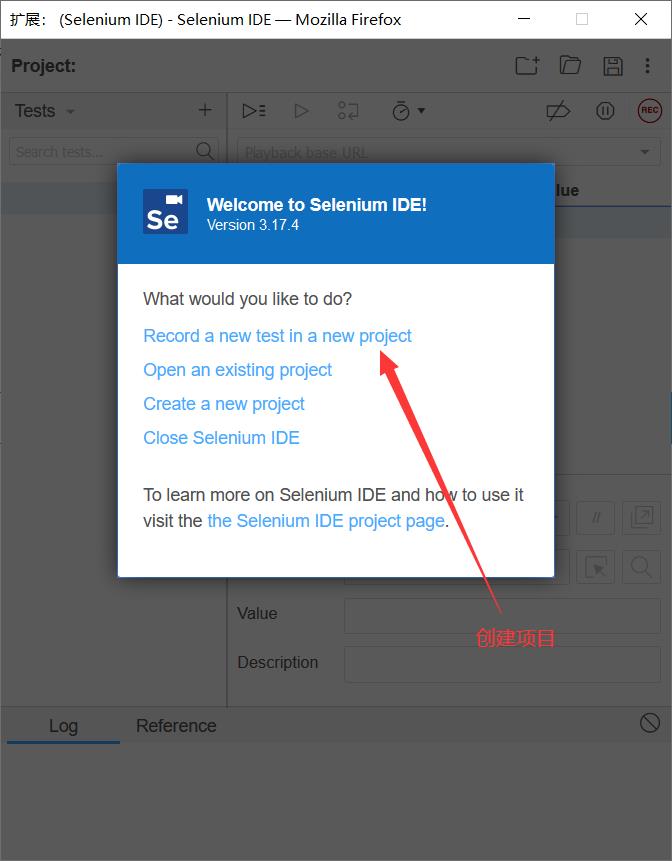
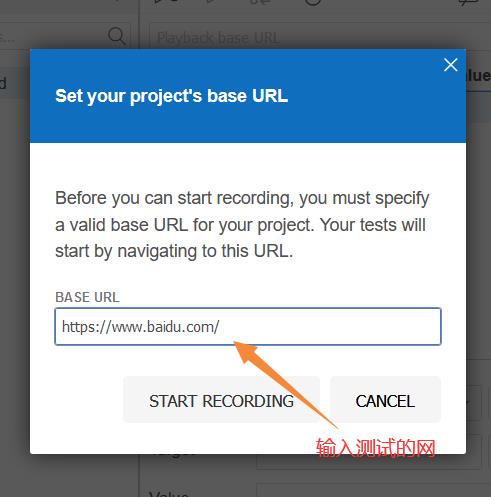
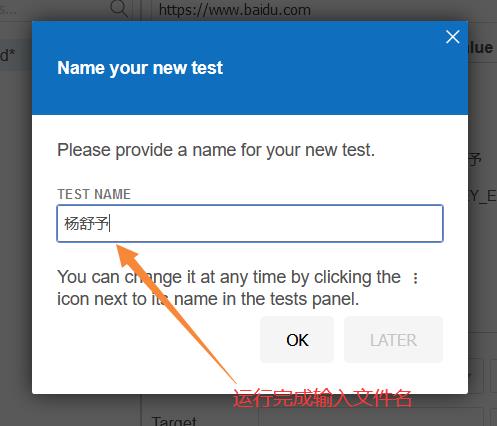
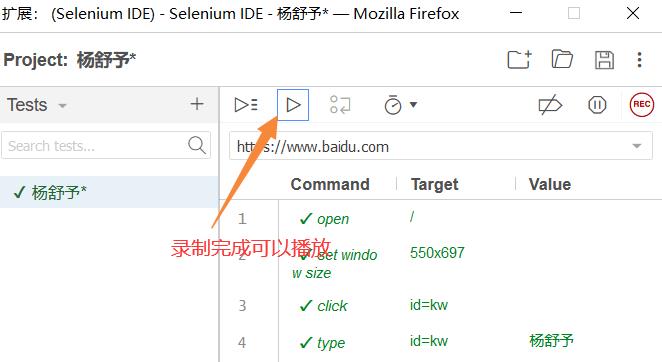
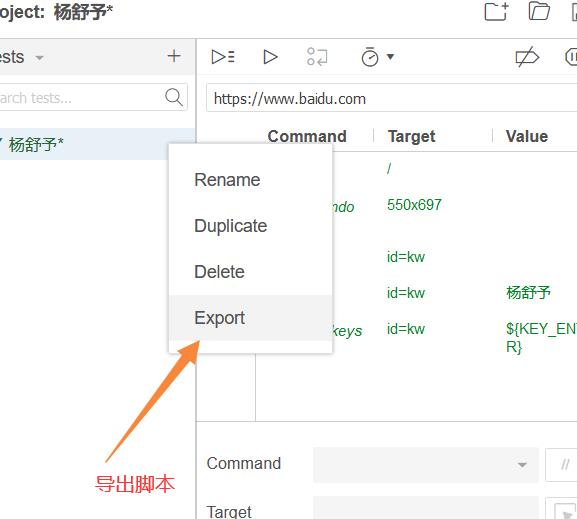
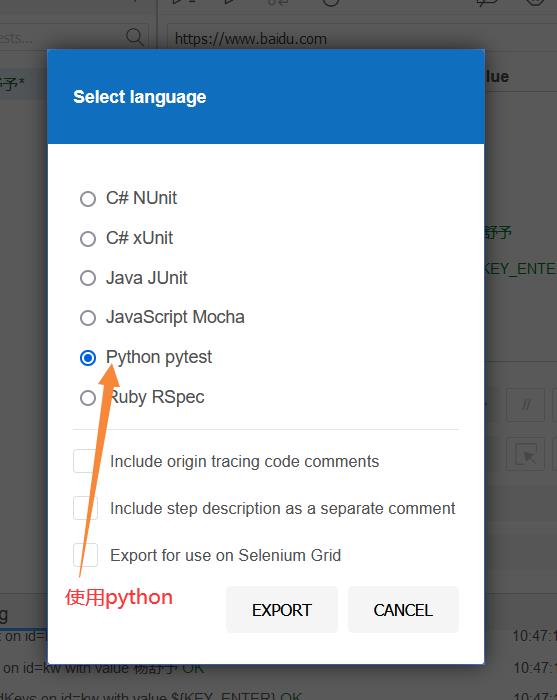
代码如图所示:
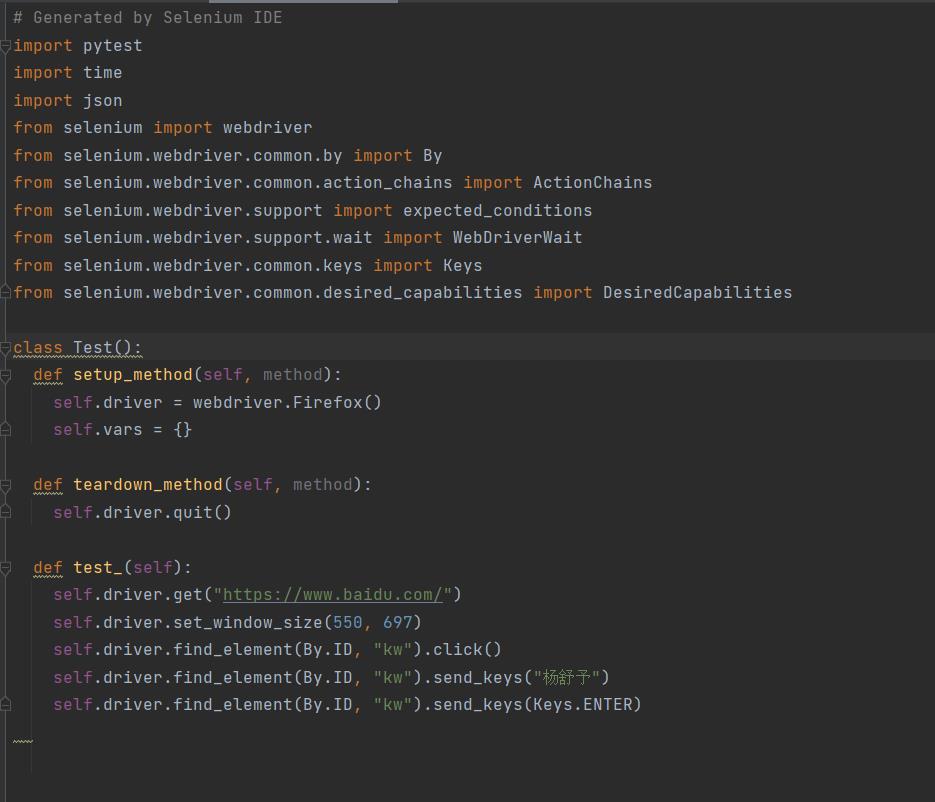
四、自动化脚本使用
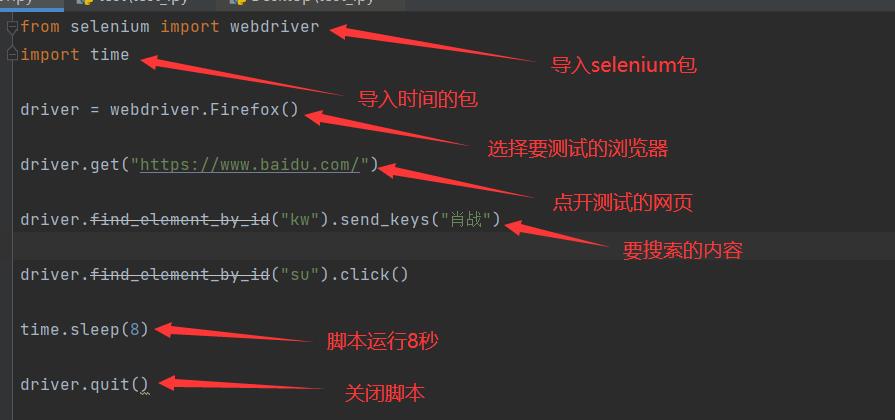
如何定位页面上的元素?
定位页面元素的原则:元素的属性全局(全网页)唯一;
id 全局唯一
name
class name
link text
partial link text
xpath 全局唯一
css selector
1.操作测试对象
click
send_keys
clear 清楚定位到的元素的内容
submit 提交表单
text 获取元素的文本内容
2.添加等待
time.sleep() 固定等待
driver 驱动变量 implicity_wat()智能等待(不一定等待给够的时间)
这两者等待的共同点:等待够设置的时间,如果下一句要执行的代码,元素没有加载出来,都会抛异常
3.打印
title 打印当前页面的title
current_url 打印当前网页的URL
4.浏览器的操作
浏览器的最大化:maxmize_window
设置浏览器的高和宽:set_window_size
浏览器的前进 forward()
浏览器的后退 back()
控制浏览器的滚动条

5.键盘试键

键盘组合键
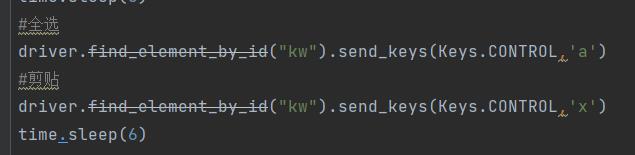
6.鼠标事件


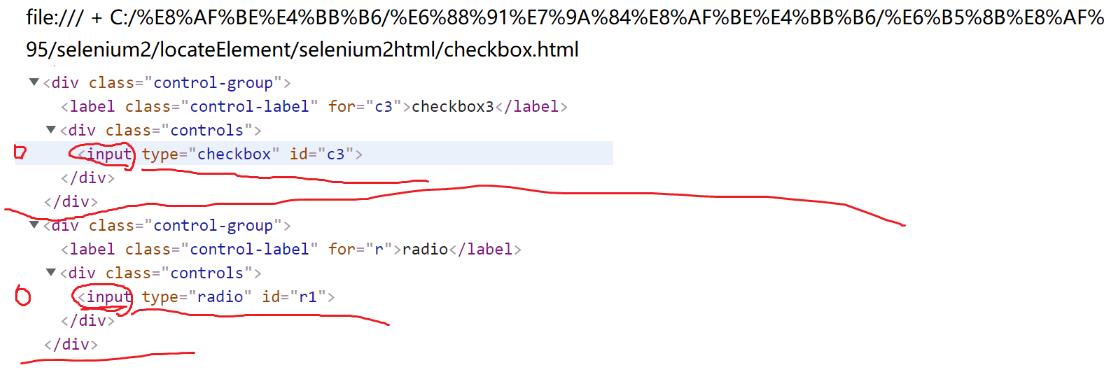
7.定位一组元素
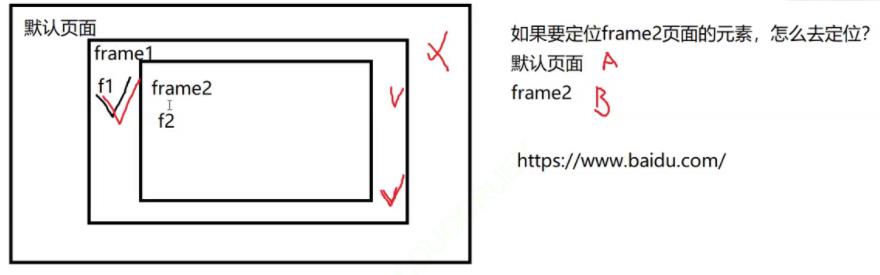
8.多层框架的定位

9.DIV对话框的处理

10.上传文件操作

五、unittest框架
1.unittest和Junit的区别
共同点:单元测试框架
unittest:UI界面功能的单元测试框架(黑盒的功能单元测试框架)
Junit:基于代码的单元测试框架(白盒的单元测试框架)
2.unittest框架解析
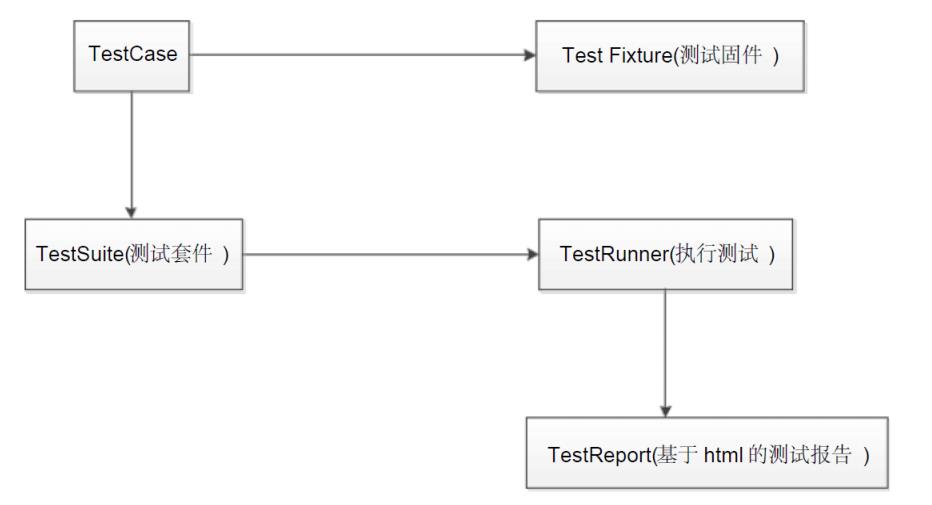
测试固件:
setUp():做执行测试用例前的准备工作
tearDown():执行测试用例后的清理工作
测试套件:
3.测试用例的运行顺序
0~9 A ~ Z a ~ z
4.忽略测试用例的执行
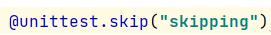
5.测试套件
addTest
makesuite
TestLoader
discover
addTest每次把一个测试脚本中的一个测试用例加载进测试条件
makesuit和TestLoader把一个测试脚本中的所有测试用例加载进测试套件
discover把一个文件夹下,所有以某种形式命名的脚本中的所有测试用例都加载到测试套件中
verbosity=0 只输出测试套件中运行失败的测试用例的失败原因
verbosity=1 测试套件中运行成功的测试用例输出,运行失败的测试用例输出
verbosity=2 输出测试套件中运行的所有测试用例的来源(测试用例的名称以及测试用例所在的脚本名称和类名称)运行成功的测试用例输出OK 失败的输出FAIL
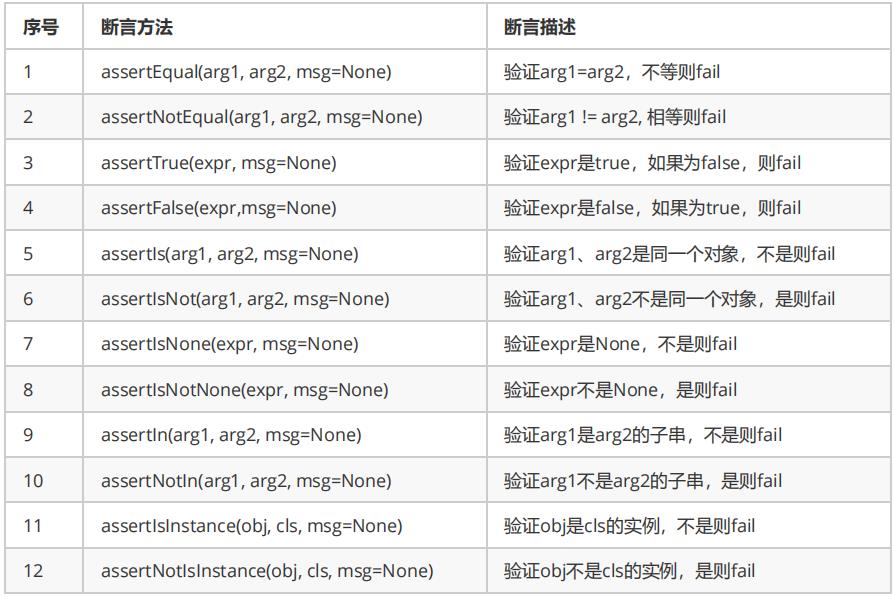
6.断言
手工测试用例:测试环境,测试步骤,测试数据,预期结果
自动化的测试中, 对于每个单独的case来说,一个case的执行结果中, 必然会有期望结果与实际结果, 来判断该case是通过还是失败, 在unittest 的库中提供了大量的实用方法来检查预期值与实际值, 来验证case的结果, 一般来说, 检查条件大体分为等价性, 逻辑比较以及其他, 如果给定的断言通过, 测试会继续执行到下一行的代码, 如果断言失败, 对应的case测试会立即停止或者生成错误信息( 一般打印错误信息即可) ,但是不要影响其他的case执行。
7.html报告
总结分析测试用例执行的过程中哪一些测试用例执行成功,哪一些测试用例执行失败,并且分析失败的原因
并且把结果记录下来
把HTMLTestRunner.py PYthon38\\Lib下
(1)解决生成的HTML报告存放的问题
创建一个文件夹,专门存放HTML报告
(2)解决重复命名的问题
8.错误截图
六、数据驱动
安装数据驱动
pip install ddt
dd.ddt:
装饰类,也就是继承自TestCase的类
ddt.data:
装饰测试方法。参数是一系列的值
ddt.file_data:
装饰测试方法。参数是文件名。文件可以是json 或者 yaml类型。
注意,如果文件以”.yml”或者”.yaml”结尾,ddt会作为yaml类型处理,其他所有文件都会作为json文件处理。
如果文件中是列表,每个列表的值会作为测试用例参数,同时作为测试用例方法名后缀显示。
如果文件中是字典,字典的key会作为测试用例方法的后缀显示,字典的值会作为测试用例参数。
ddt.unpack:
传递的是复杂的数据结构时使用。比如使用元组或者列表,添加unpack之后,ddt会自动把元组或者列表对应到多个参数上。字典也可以这样处理。
另外:
在主函数中,直接调用main() ,在main中加入verbosity=2 ,这样测试的结果就会显示的更加详细。
这里的verbosity 是一个选项, 表示测试结果的信息复杂度,有三个值:
0 ( 静默模式): 你只能获得总的测试用例数和总的结果比如总共100个失败,20 成功80
1 ( 默认模式): 非常类似静默模式只是在每个成功的用例前面有个“ . ” 每个失败的用例前面有个“F”
2 ( 详细模式): 测试结果会显示每个测试用例的所有相关的信息
以上是关于Selenium自动化测试的主要内容,如果未能解决你的问题,请参考以下文章
Selenium自动化测试:如何使用cookie跳过验证码登录