从0到1搭建大数据平台之开篇
Posted 脚丫先生
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了从0到1搭建大数据平台之开篇相关的知识,希望对你有一定的参考价值。
大家好,我是脚丫先生 (o^^o)
最近比较肝,与小伙伴负责一个小型大数据平台项目。
之前自己一直是做离线开发。
突然有一个实时流的托拉拽模块,又爽又刺激。
爽点是终于可以玩实时流,刺点是如何玩转实时流Flink。
言归正传,我们接着分享上期的从0到1搭建大数据平台。
让小伙伴们又爽又刺激。
把快乐给大家,痛苦留给自己。

文章目录
一、架构总览
在之前的一期「一文看懂大数据的技术生态」中,我们对大数据的技术栈组件。
充分了解之余,更多的是对如此庞大的生态圈叹为观止。
不过,我想你一定不满足于此。
在之前,我们已经把大数据生态圈这栋楼房已经完美竣工。
我在给它买了家具和装饰之后,就完美变形成一个通用大数据平台。

看,这大数据平台框架,真高啊,总共有8楼(真是要费不少钱)。
一层一层,往上拔高,逐渐精彩。
每一层都功能各异,但是又互相依赖,兄弟姐妹关系,你中有我,我中有你。
接下来,我们通过通用大数据平台框架进行数据流程设计。
来吧,我带着你,一步一个脚印,向前迈进。(不懂你捶我)
1.1 数据来源层
数据来源:这是最原始的一步,巧妇难为无米之炊,没有数据,又谈何处理。
我们已经知道了大数据的特点之一是数据种类多样性。具体而言,可以分为以下几种类型。
结构化数据:可以用二维数据库表来抽象,抽取数据规律。以数据库数据和文本数据为结构化数据。
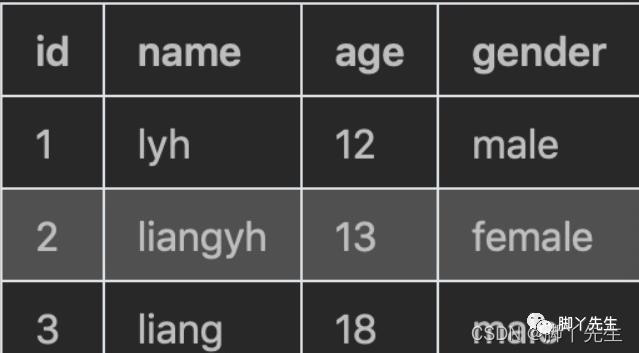
半结构化数据:介于结构化和非结构化之间,主要指XML、html、JSON文档、Email等等,也可称非结构化。

非结构化数据:指信息没有一个预先定义好的数据模型或者没有以一个预先定义的方式来组织,不可用二维表抽象,比如图片,图像,音频,视频等 。

那么这种类型的数据又是从何处获取呢,我想这是大家心里想的第一个问题吧。
一般来说,数据来源主要是两类。
1、各个业务系统的关系数据库,可以称之为业务的交互数据。主要是在业务交互过程中产生的数据。比如,你去大保健要用支付宝付费,淘宝剁手购物等这些过程产生的相关数据。一般存储在DB中,包括mysql,Oracle。
2、各种埋点日志,可以称之为埋点用户行为数据。主要是用户在使用产品过程中,与客户端进行交互过程产生的数据。比如,页面浏览、点击、停留、评论、点赞、收藏等。简而言之,夜深人静的时候,你躲在被子里,用快播神器看不知名的大片这些行为,都会产生数据被捕获。

既然小伙伴们,知道了数据来源,那么我们的数据流程设计第一步:

1.2 数据传输层
当我们知道了数据的种类,以及数据是如何而来的。
那么,紧接着就是用大数据技术组件去获取数据,搞到数据。
数据传输:数据传输层也可称之为,数据采集。
目前业界较为主流的数据采集工具有Flume、Datax、Sqoop、Kafka、Camel等。
又是一堆眼花缭乱的大数据采集组件,那么如何进行选型呢?
带着疑问,我们接着往下走。
一般来说,采集数据是根据数据来源,来确定决定我们要使用的大数据采集组件。
1、针对各个业务系统的关系数据库(业务的交互数据)的采集,这类数据通常的存放在关系型数据库里,可以通过Sqoop或者Datax等大数据技术组件进行定时抽取。
2、针对各种埋点日志(埋点用户行为数据)的采集,这类数据通常是存放在日志服务器里,源源不断的增加,通过Flume进行实时收集到Kafka消息队列。
此时,我们的数据流程设计第二步。
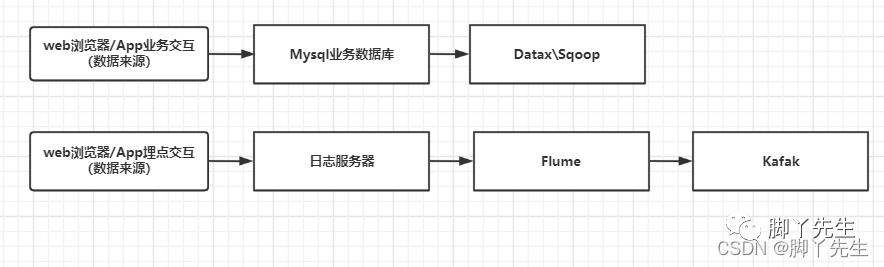
第一条线:从Web浏览器/App业务交互产生的数据,通过java微服务对数据的规则化,解析,存入Db数据库,之后通过异构数据采集大数据组件Datax\\Sqoop进行采集。
第二条线:从Web浏览器/App埋点数据,通过java微服务把数据收集到日志服务器里,之后通过Flume分布式日志收集组件进行初步采集,最后放置kafka消息队列。
1.3 数据存储层
在数据采集这里,我们知道了两条数据线的大致流程。
那么通过大数据技术组件采集到的数据又是如何存储呢。
别着急,待我细细道来。
当我们收集到数据后,便是将这些数据进行存储。
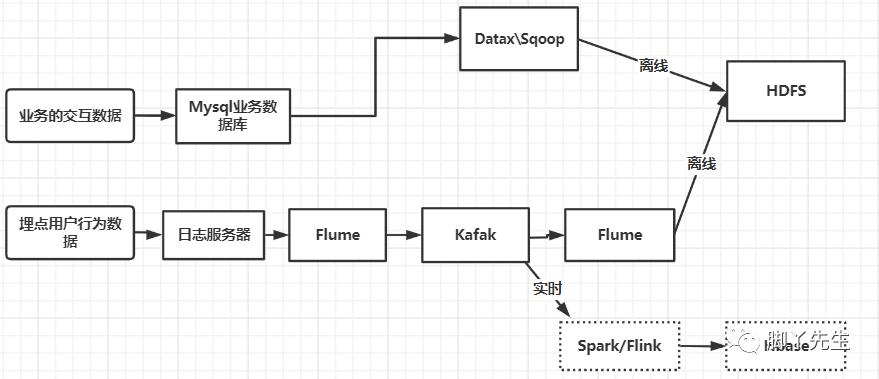
第一条线,针对的是业务的交互数据,一般通过采集存储于分布式文件系统HDFS。
属于离线数据。
第二条线,针对埋点用户行为数据,采集之后的存储分为两种情况。
1、离线:该日志数据通过Flume进行收集,先是放置在kafka消息队列,之后再次利用Flume存储于分布式文件系统HDFS。
2、实时 :该日志数据通过Flume进行收集,先是放置在kafka消息队列,之后直接提供给流式计算引擎Spark/Flink进行处理,最后存储于Hbase。
此时,我们的数据流程设计如下所示:
1.4 资源管理层
资源管理:通过字面进行理解,就可以知道,该层是进行服务器资源管理的。
所谓的资源,即是服务器的CPU、内存等。
我们在「一文看懂大数据的技术生态」中,知道大数据技术主要是解决。
海量数据的存储和计算。
在数据存储层已经解决了海量数据的存储,那么接着就要进行数据的处理计算。
处理计算能力,是需要调用服务器的资源的。
资源管理层中的yarn,就是管理和调度资源的大数据技术组件。
简言之,相当于一个分布式的操作系统平台,而Mapreduce等运算程序则相当于运行于操作系统之上的应用程序,yarn为这些程序提供运算所需的资源(内存、cpu)。

yarn好比大功率电池,给机器提供能量。
1.5 数据计算层
数据处理:这一步是数据处理最核心的环节。
包括离线处理和流处理两种方式。
对应的计算引擎包括MapReduce、Spark、Flink等。
处理完的结果会保存到已经提前设计好的数据仓库中,或者HBase、Redis、RDBMS等各种存储系统上。
在这层中,我们终于解决了海量数据的存储计算。
撒花。

此时,我们的数据流程设计为

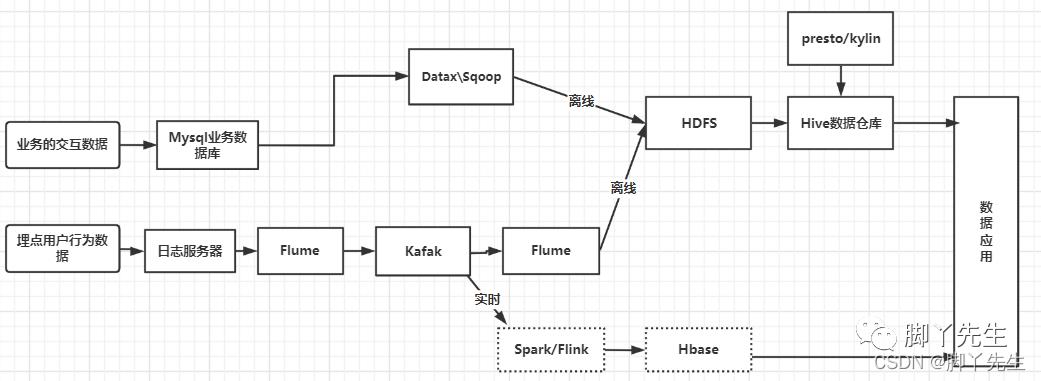
离线处理:当数据存储到HDFS后,利用Mapreduce/Hive/SparkSQL大数据技术组件,根据业务需求,对数据进行处理计算。
实时处理:当数据放置于Kafka消息队列时,利用Spark/Flink,根据业务指标需求,对数据进行实时计算。
1.6 任务调度层
任务调度:在离线处理阶段,我们会对数据进行定时处理。
因此,任务调度的大数据组件Oozie / Azkaban/airflow 会服务于离线处理任务。
满足我们定时调度的需求,通常离线处理任务的定时调度时间,大多数是设置到晚上凌晨进行执行。
我们小组一直在用的是airflow大数据定时调度组件,它的依赖能力是非常强的,社区人群也比较活跃,对python开发人员非常友好。

小伙伴们,这里我总结了三种调度神器的介绍,给大家一个简单的介绍。

1.7 多维分析层
多维数据分析是一种非常先进的数据分析理念。
在这层,大数据计算组件kylin/presto/impala组件,提供即席查询功能。
所谓即席查询是指用户根据自己的需求,灵活的选择查询条件,系统根据用户的选择生成相应的统计报表。
我们可以这么理解:即席查询就是一种快速的执行自定义SQL。
此时,我们的数据流程设计继续升级。

1.8 应用层
应用:应用应用,有数据就应用。
可以这么理解,该层是把经过离线和实时处理并且存入数据库里的数据进行使用。
包括数据的可视化展现、业务决策、或者AI等各种数据应用场景。
此时,我们的数据流程已经粗略的设计完成。
撒花。

好了,今天就聊这么多,祝各位终有所成,收获满满!
期待老铁的关注!!!
更多精彩内容请关注 微信公众号 👇「脚丫先生」🔥:
一枚热衷于分享大数据基础原理,技术实战,架构设计与原型实现之外,还喜欢输出一些有趣实用的编程干货内容,与程序人生。
更多精彩福利干货,期待您的关注 ~
以上是关于从0到1搭建大数据平台之开篇的主要内容,如果未能解决你的问题,请参考以下文章