从0到1搭建大数据平台之数据计算
Posted 大数据指北
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了从0到1搭建大数据平台之数据计算相关的知识,希望对你有一定的参考价值。
文章目录
前言
大家好,我是脚丫先生 (o^^o)
之前有说过「从0到1搭建大数据平台之数据存储」,想必小伙伴还有印象。
既然大数据平台有了数据存储,那么针对数据的计算必不可少。
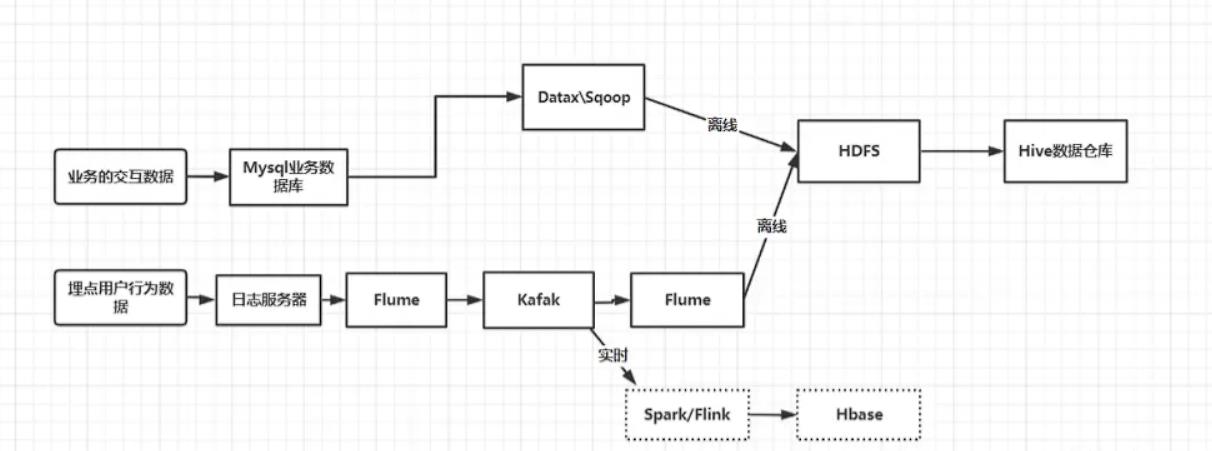
我们都知道大数据计算平台都是围绕着Hadoop生态圈发展的,以HDFS分布式文件系统作为数据存储。
分离线批处理和实时处理两条路线走天下。
在讲解Hadoop的大数据计算之前,我们应该首先了解的是它为何而来。
下面由我带着大家,一步一步,逐渐精彩。
一、传统的数据计算
没有大数据之前,我们的业务数据计算平台基本是依赖于数据库。
比如:微软的SQLServer,甲骨文的Oracle IBM的DB2等。
也就是通常所说的OLTP数据库。

这类数据库主要用来进行事务处理,比如新增一个订单、修改一个订单、查询一个订单和作废一个订单等。其核心是高效对单条数据进行处理。
但是,随着互联网的迅速发展,业务数据已经呈现指数型的增长。
面对如此海量的数据,传统的OLTP数据库,访问通常需要全表扫描,频繁而且通常又是并发地全表扫描会造成OLTP数据库响应异常缓慢甚至宕机。
也许你会说:可以通过增加CPU,内存,磁盘等方式提高处理能力。
但是 这类集中式的数据库很难满足海量数据对计算能力的巨大需求,同时传统数据库架构对高端设备的依赖,无疑将直接导致系统成本的大幅度增加,甚至可能会导致系统被主机和硬件厂商所“绑架”,不得不持续增加投入成本。
因此必须有新的理论支撑和技术突破才能够满足这些海量数据分析请求。
于是就有了Hadoop的闪亮登场。
二、Hadoop的崛起
随着互联网行业的发展,特别是移动互联网的快速发展。
短短几年发生了翻天覆地的变化:
-
- 一个是数据规模前所未有,一个成功的互联网产品日活可以过亿,就像你熟知的头条、抖音、快手、网易云音乐,每天产生几千亿的用户行为。传统数据库难于扩展,根本无法承载如此规模的海量数据。
-
- 另一个是数据类型变得异构化,互联网时代的数据除了来自业务数据库的结构化数据,还有来自 App、Web 的前端埋点数据,或者业务服务器的后端埋点日志,这些数据一般都是半结构化,甚至无结构的。传统数据库对数据模型有严格的要求,在数据导入到数据库前,数据模型就必须事先定义好,数据必须按照模型设计存储。
紧接着经典的三大论文的出现,提出了一种新的,面向数据分析的海量异构数据的统一计算、存储的方法。
在2005年,Hadoop应运而生,大数据技术开始普及。相较于传统的数据库主要有两个优势:
- 1 完全分布式,易于扩展,可以使用价格低廉的机器堆出一个计算、存储能力很强的集群,满足海量数据的处理要求;
- 2 弱化数据格式,数据被集成到 Hadoop 之后,可以不保留任何数据格式,数据模型与数据存储分离,数据在被使用的时候,可以按照不同的模型读取,满足异构数据灵活分析的需求。
因此,越来越多的企业选择基于Hadoop来存储计算海量数据。
以下计算组件更为详细的原理在之后细说,先知其表,后知其里。
三、离线计算
离线数据处理,数据计算频率主要以天(包含小时、周和月)为单位。
例如:按天进行数据处理,每天凌晨等数据采集和同步的数据到位后,相关的数据处理任务会被按照预先设计的ETL (抽取、转换、加载,一般用来泛指数据清洗、关联、规范化等数据处理过程〉逻辑以及ETL任务之间的拓扑关系依次调用,最终的数据会写入离线数据仓库中。
在这个数据计算过程中最频繁使用的是Hadoop生态圈的MapReduc和Hive。
MapReduce
MapReduce 是Google 公司的核心计算模型,它将运行于大规模集群上的复杂并行计算过程高度抽象为两个函数: map 和reduce。
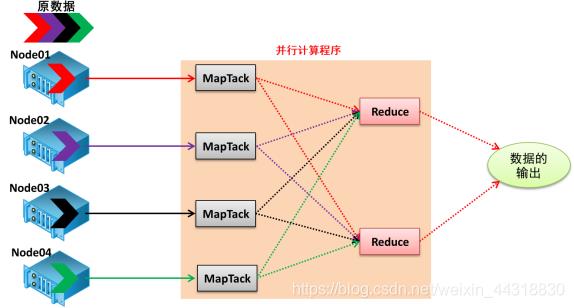
其核心思想:分而治之,先分后和:将一个大的、复杂的工作或任务,拆分成多个小的任务,并行处理,最终进行合并。
-
map: 将数据进行拆分,即把复杂的任务分解为若干个“简单的任务”来并行处理。可以进行拆分的前提是这些小任务可以并行计算,彼此间几乎没有依赖关系。
-
reduce: 对数据进行汇总,即对map阶段的结果进行全局汇总。
Hive
Hive:它是由 Facebook 开源用于解决海量结构化日志的数据统计。它是基于大数据生态圈 hadoop 的一个数据仓库工具,可以将结构化的数据文件映射为一张表,并提供类 SQL 查询功能。
其本质是将 HQL 转化成 MapReduce 程序。
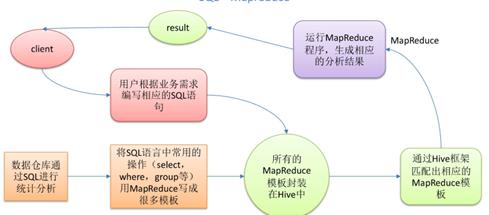
从图示可以看出,Hive 从某种程度上讲就是很多“SQL—MapReduce”框架的一个封装,可以将用户编写的 Sql 语言解析成对应的 MapReduce 程序,最终通过 MapReduce 运算框架形成运算结果提交给 Client。
SparkSQL
尽管MapReduce 和Hive 能完成海量数据的大多数批处理工作,并且在大数据时代成为企业大数据处理的首选技术,但是其数据查询的延迟一直被诣病,而且也非常不适合选代计算和DAG (有向无环图)计算。
因此,我们需要更为强大的强大的计算引擎。

于是Spark也登上了舞台,它有可伸缩、基于内存计算等特点,且可以直接读写Hadoop上任何格式的数据,较好地满足了数据即时查询和迭代分析的需求,因此变得越来越流行。
同时基于内存的Spark计算速度大约是基于磁盘的HadoopMapReduce的100倍。
也许会说,还有Presto,kylin等。但是这些组件一般用于即席查询,就是针对一个业务想快速测试的统计分析指标,其指标没有经过需求分析讨论的。而Mapreduce、Hive这些用于经过讨论确定的业务指标计算流程。
四、 实时计算
实时计算对时效性的要求非常高,是相对于离线计算而言。
计算频率达到秒级别。每来一条数据,就立马进行处理。
Spark Streaming

SparkStreaming是一套框架。
SparkStreaming是Spark核心API的一个扩展,可以实现高吞吐量的,具备容错机制的实时流数据处理。
其原理是将实时流数据分成小的时间片断(秒或者几百毫秒),以类似Spark 离线批处理的方式来处理这小部分数据。
Flink

在数据处理领域,批处理任务与实时流计算任务一般被认为是两种不同的任务。
一个数据项目一般会被设计为只能处理其中一种任务,例如Spark Streaming只支持流处理任务,而Map Reduce、 Hive 只支持批处理任务。 那么两者能够统一用一种技术框架来完成吗?
批处理是流处理的特例吗?
带着这两个疑问,是时候登场—>Flink。
Flink 是一个同时面向分布式实时流处理和批量数据处理的开源计算平台够,其基于同一个Flink 运行时(Flink Runtime),提供支持流处理和批处理两种类型应用的功能。
Flink在实现流处理和批处理时,与传统的一些方案完全不同,它从另一个视角看待流处理和批处理,将二者统一起来。
Flink完全支持流处理,批处理被作为一种特殊的流处理,只是它的输入数据流被定义为有界的而已。
基于同一个Flink 运行时, Flink 分别提供了流处理和批处理API,而这两种API 也是实现上层面向流处理、批处理类型应用框架的基础。
总结
离线处理和批处理是大数据计算中,非常必要的两条腿。
也是大数据平台的核心所在。
因此,学好大数据计算组件的重要性不言而喻。
由于工作原因,一直在接触flink的流批一体计算建设,所以我在自己的大数据平台研发中,思考过是否用flink来完成流批一体的数据开发模块。
祝各位终有所成,收获满满!
更多精彩内容请关注 微信公众号 👇「大数据指北」🔥:
一枚热衷于分享大数据基础原理,技术实战,架构设计与原型实现之外,还喜欢输出一些个人私活案例。
更多精彩福利干货,期待您的关注 ~
以上是关于从0到1搭建大数据平台之数据计算的主要内容,如果未能解决你的问题,请参考以下文章