高斯分布
Posted 会敲键盘的猩猩
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了高斯分布相关的知识,希望对你有一定的参考价值。
数据挖掘中的高斯分布
高斯分布,无论是单变量还是多元变量,在统计数据挖掘中是非常有用的,包括一些底层数据假设是高度非高斯的数据挖掘模型。我们需要好好了解多元高斯。
为什么我们应该关注它
- 高斯像橘子汁和阳光一样是自然存在的
- 我们需要它来理解贝叶斯最优分类器
- 我们需要它来理解回归
- 我们需要它来理解神经网络
- 我们需要它来理解混合模型
- ……
PDF(概率密度函数)的熵
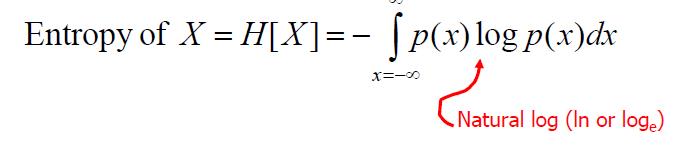
分布的熵越大,预测就越困难,压缩就越困难,分布就有越少的尖。
例1、“盒子”分布
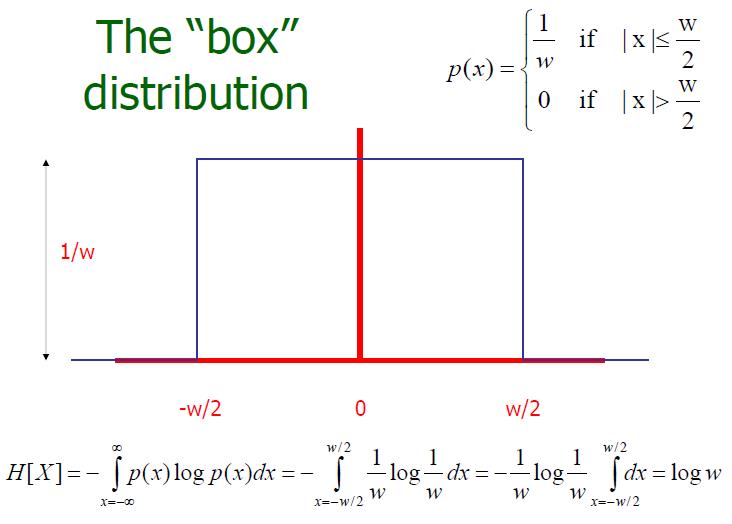
例2、单位方差“盒子”分布

例3、“尖帽”分布

单位方差“尖帽”分布

“2尖”分布

单位方差分布的熵:
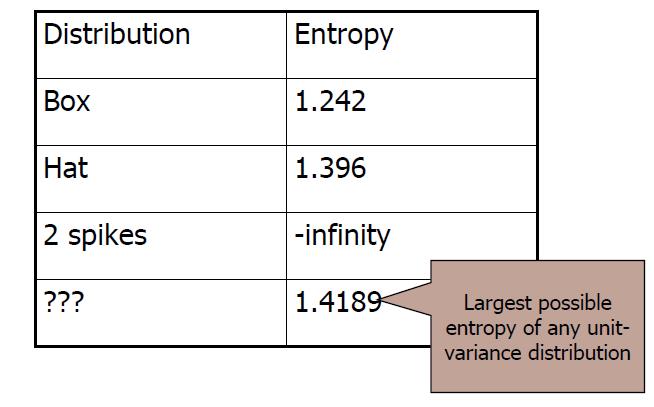
单变量高斯分布
单位方差高斯分布
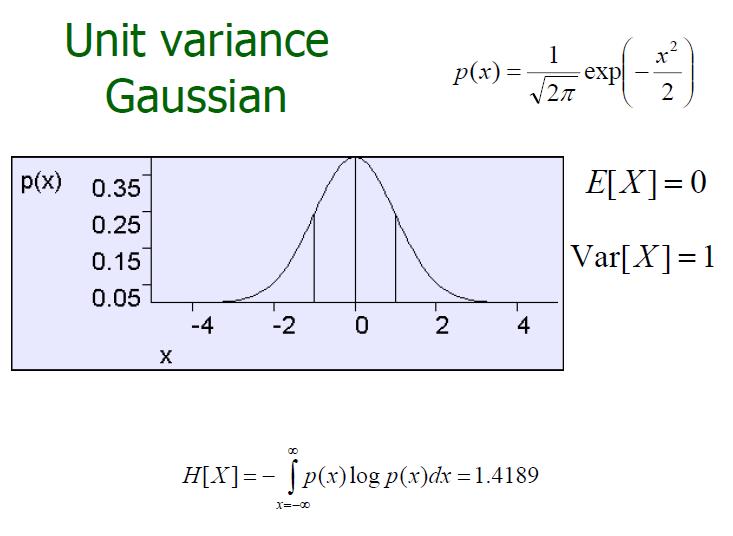
普通高斯分布

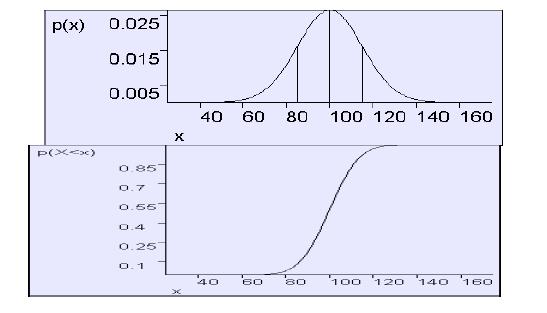
我们描述X ~ N(μ,σ2),X是均值为μ方差为σ2的高斯分布,上图中, X ~ N(100,152)。
误差函数:假设X ~ N(0,1),ERF(x)等于X小于x的概率等于X的累积分布。

假设X ~ N(μ,σ2),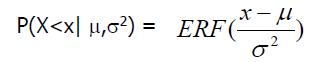
中心极限定理:如果(X1,X2,…Xn)是独立同分布的连续随机变量,那么定义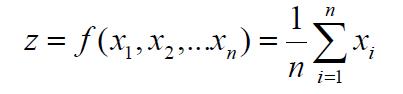 ,当n->∞时,p(z)->均值为E[Xi],方差为Var[Xi]的高斯分布。
,当n->∞时,p(z)->均值为E[Xi],方差为Var[Xi]的高斯分布。
二维高斯分布
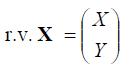 ,那么定义X~N(μ,Σ)的均值为:
,那么定义X~N(μ,Σ)的均值为: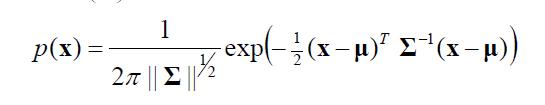 ,其中高斯参数是
,其中高斯参数是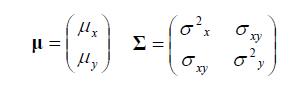 ,Σ是对称非负矩阵。可以证明E[X] = μ,Cov[X] = Σ(注意这是高斯分布的结果属性,不是定义)。
,Σ是对称非负矩阵。可以证明E[X] = μ,Cov[X] = Σ(注意这是高斯分布的结果属性,不是定义)。
估计p(x):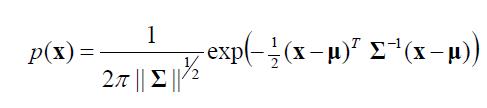
- 步骤一:选一个向量X

- 步骤二:定义δ = x - μ

- 步骤三:计算与椭圆相交的等高线数量,形式为Σ-1,D=sqrt(δTΣ-1δ)=x和μ的马氏距离
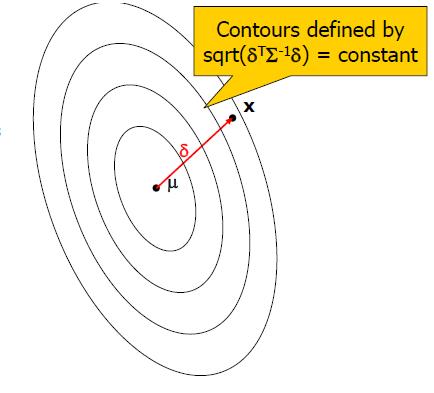
- 步骤四:定义w = exp(-D2/2),在马氏距离的平方空间中,靠近μ的x有较大的权值,而远离的有较小的权值。
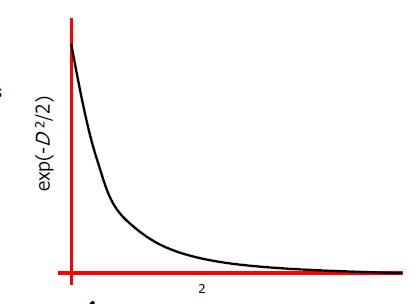
- 步骤五:
 乘以w确保
乘以w确保 。
。
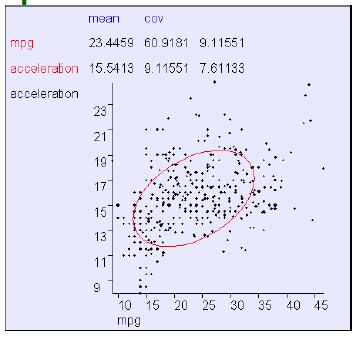
例1:
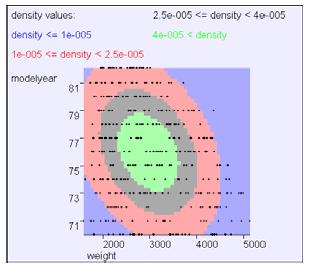
观察:均值,主轴,非对角线协方差的含义,p(x)的最大梯度区域

例2:
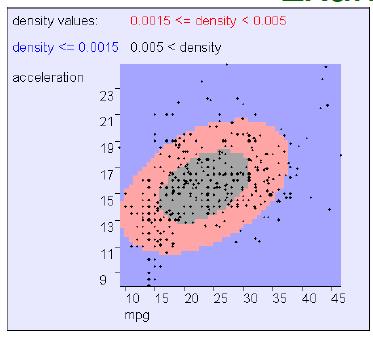
例3:


在这个例子中,x和y几乎是独立的。
例4:
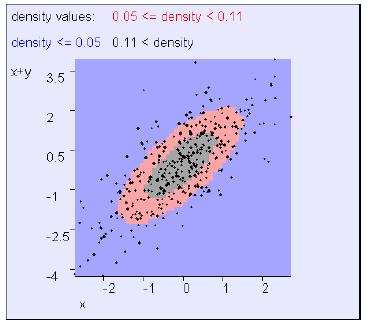

这个例子中,x和x+y明显是非独立的。
例5:
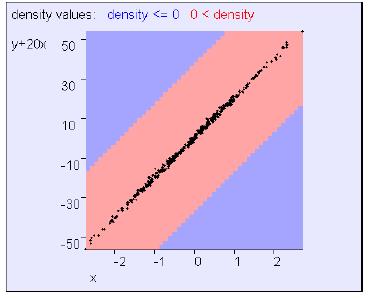

这个例子中,x和20x+y明显是非独立的。
多元高斯分布
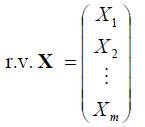 那么定义X ~ N(μ,Σ)的均值为:
那么定义X ~ N(μ,Σ)的均值为:

其中高斯参数为:
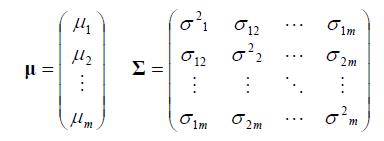
Σ是一个非负矩阵。另外,E[X] = μ和Cov[X] = Σ。(注意他们是高斯的结果属性,不是定义)
普通高斯分布
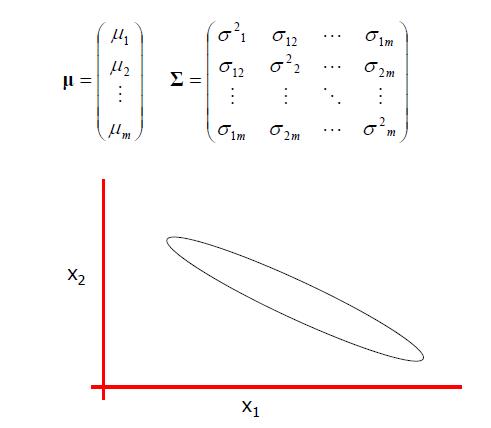
轴对齐高斯分布
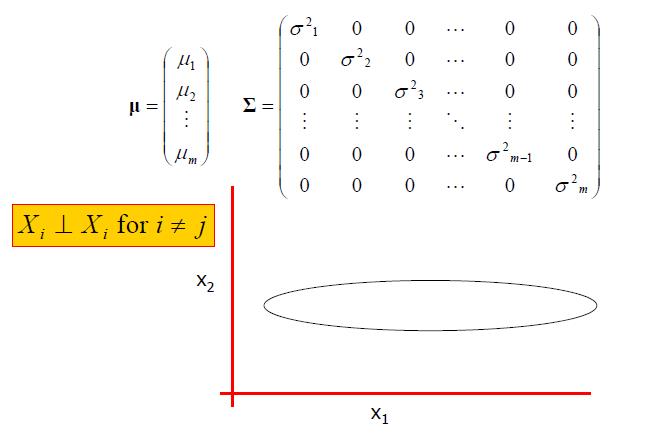
球状高斯分布

退化的高斯分布
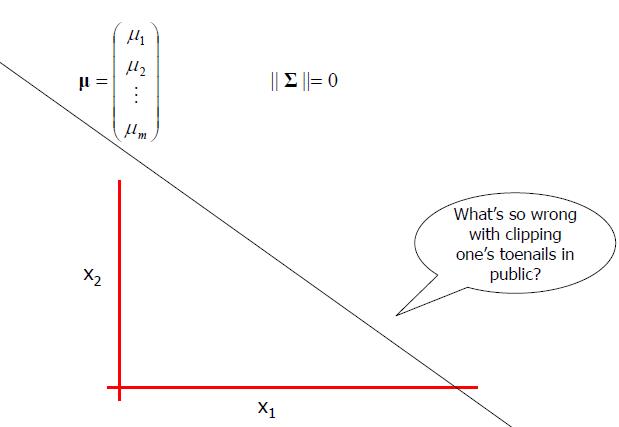
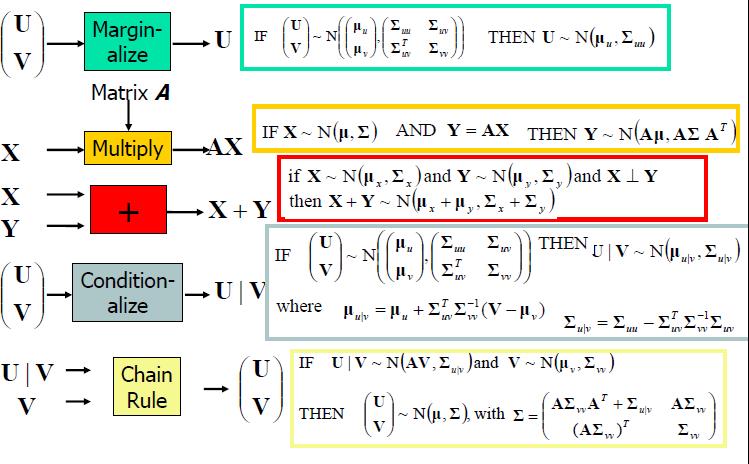
到目前为止,我们见到了高斯公式,对它的行为表现有个直观的认识,也了解了高斯协方差矩阵,接下来给一些高斯分布的技巧。
变量子集
 写作
写作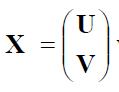 其中
其中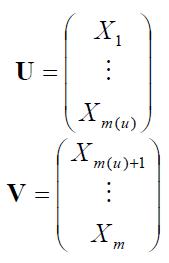
这将是我们将m维分布拆分成变量子集的标准符号。
高斯边缘化依然是高斯分布
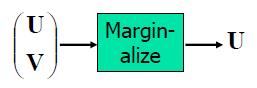
如果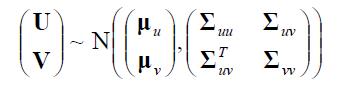
那么U依然是高斯分布(这个事实不是很明显)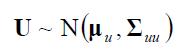 。
。
线性变换后依然保持高斯分布
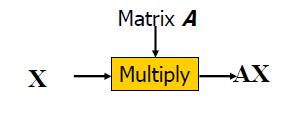
假设X是一个m维高斯随机变量X ~ N(μ,Σ),定义Y是一个p维的随机变量(注意p≤m),因此Y = AX
其中A是一个p x m矩阵,那么Y ~ N(Aμ,AΣ AT )
两个独立的高斯相加依然是高斯分布
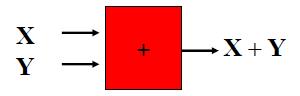
如果X ~ N(μ , Σ ),Y ~ N(μ , Σ )并且X ⊥ Y,那么

为什么X和Y不独立它就不成立呢?
下面两种说明那种对呢?
如果X和Y是非独立的,那么X+Y是高斯分布,但是协方差会改变;
如果X和Y是非独立的,那么X+Y可能是非高斯分布。
有条件的高斯是高斯分布

如果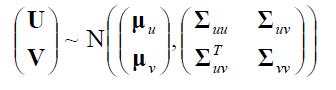 那么,
那么,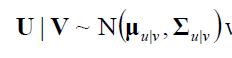
其中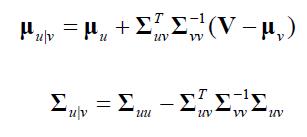
注意:当v的给定值是μv时,u的条件均值是μu;边缘均值是v的一个线性函数;条件方差真好等于或小于边缘方差;条件方差与v的给定值是无关的。
举例说明:
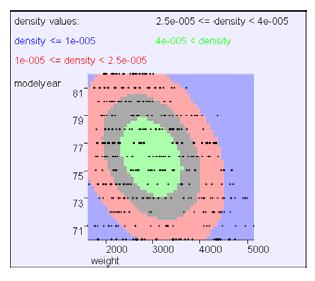
如果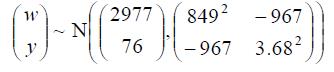 那么
那么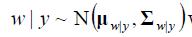 ,其中
,其中

同理m=82时

给出原高斯作对比

高斯和链式法则

让A是一个常数矩阵,如果 那么
那么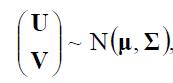 并且
并且
总结一下可用的高斯工具:
最后举一个例子。
假设有一个聪明的势利眼,且有一个孩子。整个世界中,IQ用一个高斯分布N(100,152)描绘
另外有一个测试,是来侧IQ的分数,平均分是那个人的IQ。但是因为噪声的存在,所测的值可能比真实值IQ高或者低。
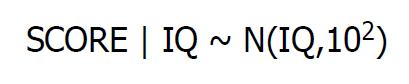
假设那个人非要拉着自己的孩子去做测试,孩子得到了130分,他惊喜他孩子的IQ是属于前2%。

某些人可能会想:这个测试肯定是不精确的,所以孩子的IQ可能是120或140,但是根据所给的结果,这个孩子很有可能是130。
最大似然IQ

MLE是能使观测数据最有可能出现的隐藏参数的值。在本例中,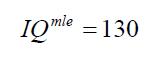
但是这与给定观测值后最有可能的参数值不相同。
我们真正想要的是:

所求的是IQ的后验概率。
考虑上面说到的那么多高斯工具,我们打算这样计算:

如果在给定分数的情况下必须给出最有可能的IQ,那么
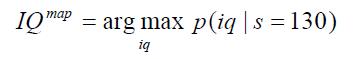
MAP是最大后验概率。
to be continue……
以上是关于高斯分布的主要内容,如果未能解决你的问题,请参考以下文章