spark task过多导致任务运行过慢甚至超时
Posted 鸿乃江边鸟
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了spark task过多导致任务运行过慢甚至超时相关的知识,希望对你有一定的参考价值。
背景以及现象
本文基于 spark 3.1.2
设置spark.driver.memory=2g
在调试spark sql任务的时候,发现有几个任务产生了40多万个Task,而且任务长期运行不出来。
分析
运行此sql,可以得到如下的dag(我们只截取产生Task多的Stage),由此可以看到是scan的文件太大了(scan了日志文件半年的数据)。
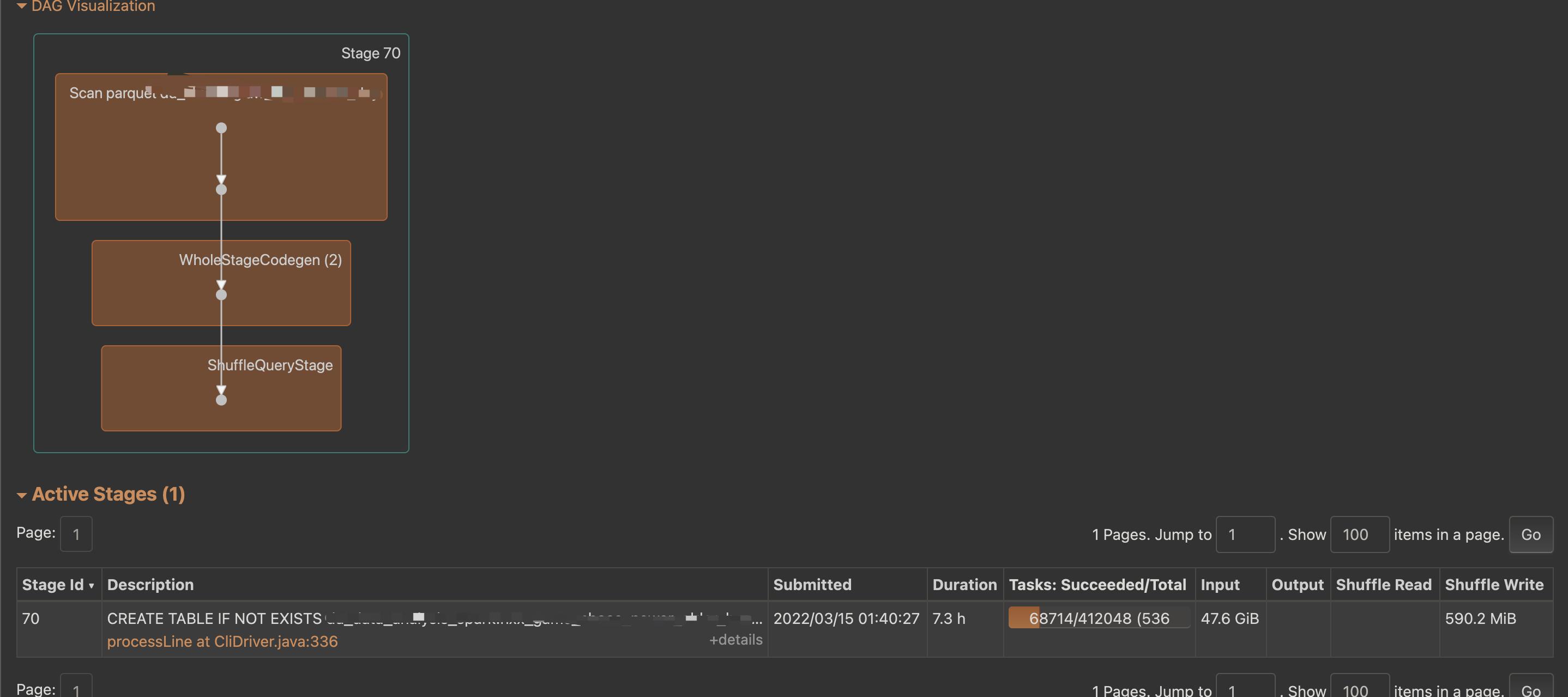
但是为什么这种情况下会导致任务运行很缓慢甚至会超时呢?
找到driver端,
用jstat -gcutil查看一下对应的gc情况(对应的内存都是调优完后的镜像信息),如下:
S0 S1 E O M CCS YGC YGCT FGC FGCT GCT
62.02 0.00 9.96 64.72 91.02 94.29 916 13.091 26 0.650 13.742
0.00 77.27 6.58 64.72 91.02 94.29 917 13.100 26 0.650 13.750
0.00 77.27 76.70 64.72 91.02 94.29 917 13.100 26 0.650 13.750
0.00 22.28 45.52 65.65 91.02 94.29 921 13.143 26 0.650 13.794
0.00 43.36 70.04 65.65 91.02 94.29 923 13.157 26 0.650 13.807
63.00 0.00 71.39 65.65 91.02 94.29 924 13.165 26 0.650 13.815
0.00 87.35 42.71 65.65 91.02 94.29 925 13.173 26 0.650 13.823
21.96 0.00 0.00 66.59 91.02 94.29 930 13.220 26 0.650 13.871
62.19 0.00 7.41 66.59 91.02 94.29 932 13.235 26 0.650 13.886
62.19 0.00 65.55 66.59 91.02 94.29 932 13.235 26 0.650 13.886
直接用jmap -heap 命令查看一下对应的堆情况:
Heap Configuration:
MinHeapFreeRatio = 40
MaxHeapFreeRatio = 70
MaxHeapSize = 4294967296 (4096.0MB)
NewSize = 172621824 (164.625MB)
MaxNewSize = 523436032 (499.1875MB)
OldSize = 345374720 (329.375MB)
NewRatio = 2
SurvivorRatio = 8
MetaspaceSize = 21807104 (20.796875MB)
CompressedClassSpaceSize = 1073741824 (1024.0MB)
MaxMetaspaceSize = 17592186044415 MB
G1HeapRegionSize = 0 (0.0MB)
Heap Usage:
New Generation (Eden + 1 Survivor Space):
capacity = 155385856 (148.1875MB)
used = 115967072 (110.59481811523438MB)
free = 39418784 (37.592681884765625MB)
74.63167818826444% used
Eden Space:
capacity = 138149888 (131.75MB)
used = 100616000 (95.95489501953125MB)
free = 37533888 (35.79510498046875MB)
72.83103986302181% used
From Space:
capacity = 17235968 (16.4375MB)
used = 15351072 (14.639923095703125MB)
free = 1884896 (1.797576904296875MB)
89.06417092442966% used
To Space:
capacity = 17235968 (16.4375MB)
used = 0 (0.0MB)
free = 17235968 (16.4375MB)
0.0% used
concurrent mark-sweep generation:
capacity = 3127533568 (2982.6484375MB)
used = 2325934584 (2218.1840744018555MB)
free = 801598984 (764.4643630981445MB)
74.36961213776492% used
可以看到driver端的内存 full gc频次有点高,而且内存增长的很厉害。
再次 我们用jmap -dump:format=b,file=heapdump.hprof命令dump内存的堆信息,我们分析一下,用MAT打开,我们可以看到如下的信息:

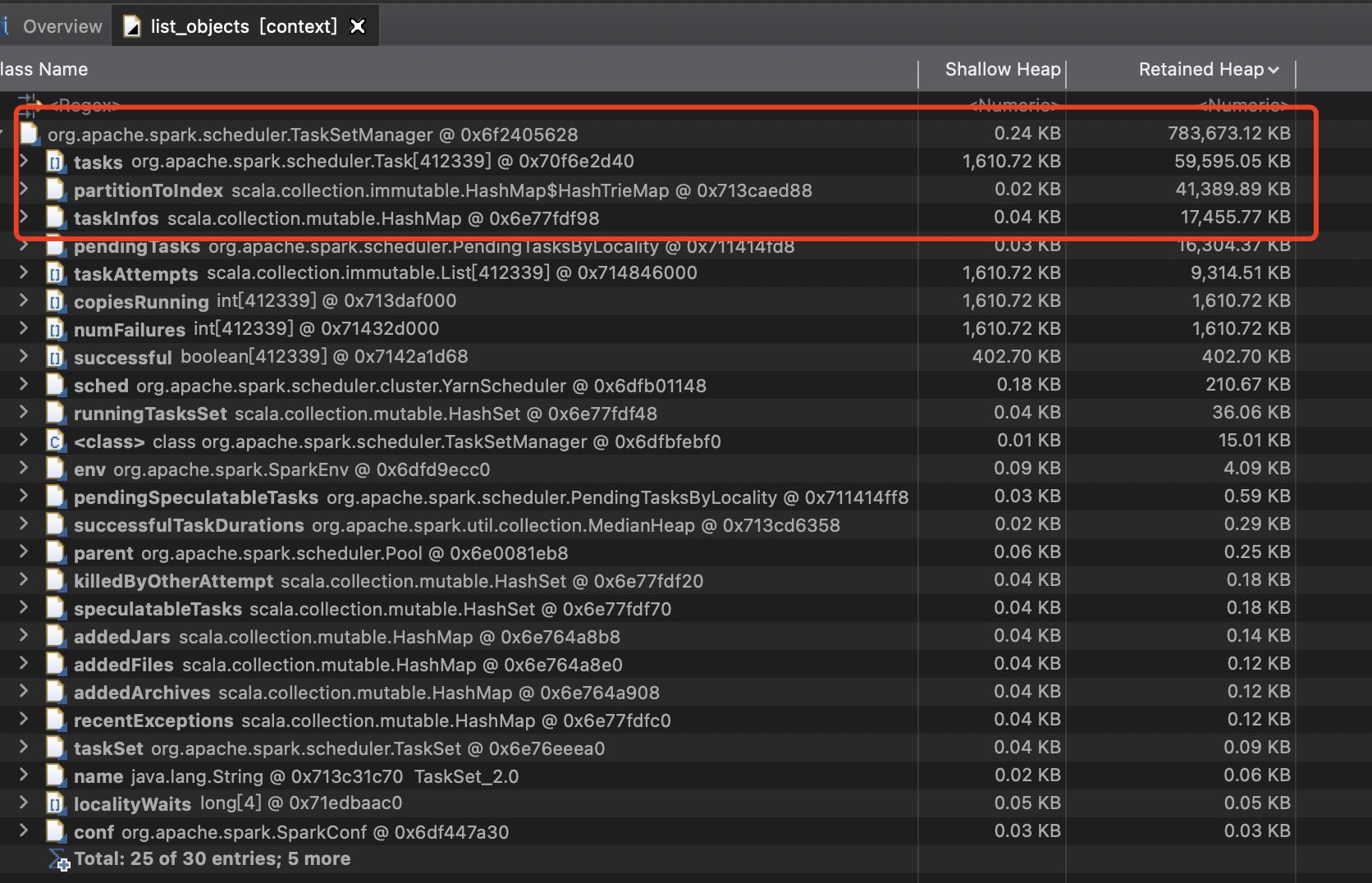
可以看到 taskSetManager的内就占用了700G。而且这任务才只是开始运行,所以后续很长一段时间,必然会占比较长的时间段。
而且这只是一个taskSetManager的内存占用,如果在足够复杂的sql下,有可能会有类似的taskSetManaget会有多个(taskSetManager是一个stage所有task的总和)。
结论以及解决方法
所以在这种情况下,如果业务上改变不了,我们就得增加内存,在笔者的情况下,增加driver内存到4g就能很好的解决,且运行的速度很快。
spark.driver.memory=4g
以上是关于spark task过多导致任务运行过慢甚至超时的主要内容,如果未能解决你的问题,请参考以下文章