[机器学习与scikit-learn-20]:算法-逻辑回归-线性逻辑回归linear_model.LogisticRegression与代码实现
Posted 文火冰糖的硅基工坊
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了[机器学习与scikit-learn-20]:算法-逻辑回归-线性逻辑回归linear_model.LogisticRegression与代码实现相关的知识,希望对你有一定的参考价值。
作者主页(文火冰糖的硅基工坊):文火冰糖(王文兵)的博客_文火冰糖的硅基工坊_CSDN博客
本文网址:[机器学习与scikit-learn-20]:算法-逻辑回归-线性逻辑回归linear_model.LogisticRegression与代码实现_文火冰糖(王文兵)的博客-CSDN博客
目录
第2章 linear_model.LogisticRegression类参数详解
第1章 scikit-learn线性逻辑回归的实现

第2章 linear_model.LogisticRegression类参数详解
2.1 类原型
class sklearn.linear_model.LogisticRegression (
penalty=’l2’,
dual=False, tol=0.0001, C=1.0,
fit_intercept=True,
intercept_scaling=1,
class_weight=None,
random_state=None,
solver=’warn’,
max_iter=100,
multi_class=’warn’,
verbose=0, warm_start=False, n_jobs=None)
2.2 正则化
正则化是用来防止模型过拟合的过程,常用的有L1正则化和L2正则化两种选项,分别通过在损失函数后加上参数向量 的L1范式和L2范式的倍数来实现。
这个增加的范式,被称为“正则项”,也被称为"惩罚项"。
损失函数改变,基于损失函数的最优化来求解的参数取值必然改变,我们以此来调节模型拟合的程度。其中L1范式表现为参数向量中的每个参数的绝对值之和,L2范数表现为参数向量中的每个参数的平方和的开方值。


2.3 类参数说明
(1)penalty='l2' : 正则化参数类型,字符串‘l1’或‘l2’,默认‘l2’。

(2)dual=False :
对偶或者原始方法。Dual只适用于正则化相为l2的‘liblinear’的情况,通常样本数大于特征数的情况下,默认为False。
(3)C=1.0 : C为正则化系数λ的倒数,必须为正数,默认为1。
和SVM中的C一样,值越小,代表正则化越强。
(4)fit_intercept=True : 是否存在截距,默认存在。
(5)intercept_scaling=1 : 仅在正则化项为‘liblinear’,且fit_intercept设置为True时有用
(6)solver='liblinear' : solver参数决定了我们对逻辑回归损失函数的优化方法,有四种算法可以选择。
- a) liblinear:使用了开源的liblinear库实现,内部使用了坐标轴下降法来迭代优化损失函数。
- b) lbfgs:拟牛顿法的一种,利用损失函数二阶导数矩阵即海森矩阵来迭代优化损失函数。
- c) newton-cg:也是牛顿法家族的一种,利用损失函数二阶导数矩阵即海森矩阵来迭代优化损失函数。
- d) sag:即随机平均梯度下降,是梯度下降法的变种,和普通梯度下降法的区别是每次迭代仅仅用一部分的样本来计算梯度,适合于样本数据多的时候。
从上面的描述可以看出,newton-cg、lbfgs和sag这三种优化算法时都需要损失函数的一阶或者二阶连续导数,因此不能用于没有连续导数的L1正则化,只能用于L2正则化。而liblinear通吃L1正则化和L2正则化。
同时,sag每次仅仅使用了部分样本进行梯度迭代,所以当样本量少的时候不要选择它,而如果样本量非常大,比如大于10万,sag是第一选择。但是sag不能用于L1正则化,所以当你有大量的样本,又需要L1正则化的话就要自己做取舍了。要么通过对样本采样来降低样本量,要么回到L2正则化。
但是liblinear也有自己的弱点!我们知道,逻辑回归有二元逻辑回归和多元逻辑回归。对于多元逻辑回归常见的有one-vs-rest(OvR)和many-vs-many(MvM)两种。而MvM一般比OvR分类相对准确一些。而liblinear只支持OvR,不支持MvM,这样如果我们需要相对精确的多元逻辑回归时,就不能选择liblinear了。也意味着如果我们需要相对精确的多元逻辑回归不能使用L1正则化了。
第3章 线性逻辑回归代码示例
线性回归是指模型是用“直线”拟合,用直线回归、然后分类。
适合于数据的分布界限是:直线可以分割的。
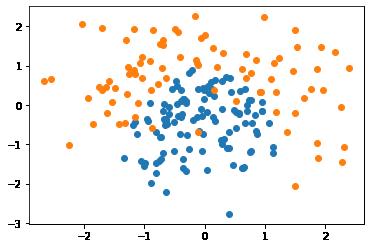
3.1 步骤1:生成、构建训练数据集
# 导入库
import numpy as np
import matplotlib.pyplot as plt
# 创建自动生成的数据集
np.random.seed(0)
# 生成二维随机向量点(X1,X2)
X = np.random.normal(0, 1, size=(200, 2))
X1 = X[:,0]
X2 = X[:,1]
print(X.shape)
print(X1.shape)
print(X2.shape)
# 生成样本二分类的标签:
# 2X+X2 > 1的点标签为1
# 2X+X2 =< 1的点标签为0
# 边界:直线边界 X1^2 + X2
Y = np.array((X1**2 + X2) > 1, dtype='int')
print(Y.shape)
print(Y)
# 随机抽取 20个样本,强制其分类为 1,
# 相当于更改数据,添加噪音
for _ in range(10):
Y[np.random.randint(200)] = 1
# 所有标签y=0的点
plt.scatter(X[Y==0, 0], X[Y==0, 1])
# 所有标签y=1的点
plt.scatter(X[Y==1, 0], X[Y==1, 1])
plt.show()(200, 2) (200,) (200,) (200,) [1 1 1 0 0 1 0 0 1 0 1 0 1 0 1 0 0 0 1 0 0 1 0 1 1 1 0 0 0 0 0 0 0 1 0 0 0 0 0 0 1 0 1 1 1 1 1 0 1 0 1 1 1 0 1 1 1 0 0 1 0 1 0 1 0 1 0 1 0 0 1 0 1 1 1 1 0 0 0 0 1 0 1 0 1 1 0 1 0 0 0 0 0 1 1 1 0 0 1 1 0 1 0 0 0 1 0 0 0 1 0 0 1 0 0 1 0 1 0 0 0 0 0 1 0 0 0 1 0 1 0 0 1 0 0 0 1 0 0 1 1 1 0 1 1 0 1 1 0 0 1 0 0 0 0 1 0 0 0 0 0 0 1 1 1 0 0 1 1 1 0 0 0 0 0 0 1 0 1 0 0 1 0 0 0 0 0 0 0 0 1 1 0 0 1 0 0 0 1 1]
3.2 步骤2:构建模型并训练模型
# 构建模型并训练模型
from sklearn.model_selection import train_test_split
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, random_state=0)
from sklearn.linear_model import LogisticRegression
#log_reg = LogisticRegression()
log_reg = LogisticRegression(C=1.0, class_weight=None, dual=False, fit_intercept=True,
intercept_scaling=1, max_iter=100, multi_class='ovr', n_jobs=1,
penalty='l2', random_state=None, solver='liblinear', tol=0.0001,
verbose=0, warm_start=False)
log_reg.fit(X_train, Y_train)
score_train = log_reg.score(X_train, Y_train)
score_test = log_reg.score(X_test, Y_test)
print("训练集分数",score_train)
print("测试集分数:",score_test)训练集分数 0.7933333333333333 测试集分数: 0.8
备注:从上图可以看出,用直线去拟合抛物线分布的向量点,准确率并不高。
下一篇文章看如何优化,使用多项式来进行预测。
3.3 步骤3:可视化模型预测的分类边界
# 可视化训练结果
#可视化决策边界:通过两种预测分类的颜色不同来展示决策的边界
# 背景数据:为二维网格数据点:meshgrid
# 所有用模型预测为1的点,标注红色
# 所有用模型预测为0的点,标注为蓝色
def plot_decision_boundary(model, axis):
# 生成二维度的网格数据
x1, x2 = np.meshgrid(
np.linspace(axis[0], axis[1], int((axis[1]-axis[0])*100)).reshape(-1,1),
np.linspace(axis[2], axis[3], int((axis[3]-axis[2])*100)).reshape(-1,1)
)
print("x1.shape", x1.shape)
print("x2.shape", x2.shape)
# 组合X1,X2, 得到(X1,X2)向量点
X = np.c_[x1.ravel(), x2.ravel()]
print("X.shape", X.shape)
# 模型预测分类
y_predict = model.predict(X)
print("y_predict.shape=", y_predict.shape)
# 把一维预测值转换成网格上的点的分类类型
y = y_predict.reshape(x1.shape)
print("y.shape=", y.shape)
print(y)
from matplotlib.colors import ListedColormap
custom_cmap = ListedColormap(['#EF9A9A','#FFF59D','#90CAF9'])
# 彩色打印网格点,网格点的颜色由y的类型确定
# y的类型,由模型对网格点的预测得到
plt.contourf(x1, x2, y, linewidth=5, cmap=custom_cmap)
plot_decision_boundary(log_reg, axis=[-3, 3, -3, 3])
# 可视化源样本点
plt.scatter(X[Y==0,0], X[Y==0,1])
plt.scatter(X[Y==1,0], X[Y==1,1])
plt.show()x1.shape (600, 600) x2.shape (600, 600) X.shape (360000, 2) y_predict.shape= (360000,) y.shape= (600, 600) [[0 0 0 ... 0 0 0] [0 0 0 ... 0 0 0] [0 0 0 ... 0 0 0] ... [1 1 1 ... 1 1 1] [1 1 1 ... 1 1 1] [1 1 1 ... 1 1 1]]

作者主页(文火冰糖的硅基工坊):文火冰糖(王文兵)的博客_文火冰糖的硅基工坊_CSDN博客
本文网址:[机器学习与scikit-learn-20]:算法-逻辑回归-线性逻辑回归linear_model.LogisticRegression与代码实现_文火冰糖(王文兵)的博客-CSDN博客
以上是关于[机器学习与scikit-learn-20]:算法-逻辑回归-线性逻辑回归linear_model.LogisticRegression与代码实现的主要内容,如果未能解决你的问题,请参考以下文章
机器学习机器学习入门02 - 数据拆分与测试&算法评价与调整