中科大提出统一输入过滤框架InFi
Posted 人工智能博士
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了中科大提出统一输入过滤框架InFi相关的知识,希望对你有一定的参考价值。
点上方人工智能算法与Python大数据获取更多干货
在右上方 ··· 设为星标 ★,第一时间获取资源
仅做学术分享,如有侵权,联系删除
转载于 :机器之心
针对模型推理过程中的输入冗余,中科大新研究首次从理论角度进行了可过滤性分析,并提出统一的输入过滤框架,让模型推理的资源效率大幅提升。
随着移动设备算力的提高和对感知数据进行实时分析需求的增长,以移动为中心的人工智能应用愈发普遍。据估计,2022 年将有超过 80% 的商用 IoT 项目将包含 AI 应用。然而多数精度最优的 AI 模型的计算量过大,以至于难以在移动设备上进行高吞吐的推理,甚至当推理任务被卸载到边缘或云端服务器时其推理效率也难以满足应用的需求。
冗余的输入广泛存在于移动为中心的人工智能应用中,将其过滤是一种有效的提高推理效率的方法。现有工作分别探索过两类输入过滤机制:推理跳过和推理重用。其中推理跳过方法旨在跳过那些不会产生有意义输出的推理计算,例如相册分类应用可能会在没有人脸的图片上运行人脸检测模型:

智能音箱应用可能将不包含指令的语音上传至云端进行语音识别:

而推理重用方法希望重用已进行过得推理计算结果,从而在新的数据到来时能够从缓存中更快速地返回结果,例如智能手环上的动作分类模型可能会处理产生相同动作标签的运动信号:

以及基于无人机和边缘服务器的交通监控可能会在连续两个画面帧中得到不变的车辆计数结果:
现有工作已针对很多应用设计了有效的输入过滤方法,然而两个重要的问题仍未得到解答,并且严重影响着输入过滤方法的应用:
推理任务的可过滤性。尽管输入过滤技术已在很多具体应用中显示出优化效果,但往往是由主观的对冗余输入的观察而启发的。如果不能从理论上回答 “哪些推理任务存在输入过滤的优化机会” 这一问题,则输入过滤技术的应用难以避免高成本的试错过程;
鲁棒的特征可区分性。输入数据的特征表达直接关系到进行推理跳过和找到可重用推理结果的精度,因此对于输入过滤的表现有着关键影响。现有方法多数依赖手工特征或预训练深度特征,这些特征在应用过程中没有鲁棒的可区分性,可能完全失去过滤效果。
在 MobiCom 2022 上,中国科学技术大学 LINKE 实验室针对移动为中心的模型推理场景,提出端到端可学的输入过滤框架 InFi (INput FIlter)。该工作首次对输入过滤问题进行了形式化建模,并基于推理模型和输入过滤器的函数族复杂性对比,在理论层面上对推理任务的可过滤性进行了分析。InFi 框架涵盖了现有的 SOTA 方法所使用的推理跳过和推理重用机制。基于 InFi 框架,该工作设计并实现了支持六种输入模态和三种推理任务部署方式的输入过滤器,在以移动为中心的推理场景中有着广泛的适用性。在 12 个以移动为中心的人工智能应用上进行的实验验证了理论分析结果,并表明 InFi 在适用性、准确性和资源效率方面均优于 SOTA 方法。其中,在一个移动平台上的视频分析应用中,相较于原始推理任务,InFi 实现了 8.5 倍的推理吞吐率并节省了 95% 的通信带宽,同时保持超过 90% 的推理精度。

论文地址:https://yuanmu97.github.io/preprint/InFi_MobiCom22.pdf
项目地址:https://github.com/yuanmu97/infi
可过滤性分析
直观来说,推理任务的可过滤性指:相较于原始推理任务,能否得到一个低成本、高精度的输入数据冗余性的预测器。原始的推理任务定义为属于函数族 H 的模型 h,其将输入数据映射至推理输出,例如人脸检测模型以图片为输入,输出检测结果(人脸位置的检测框)。根据推理模型的输出结果,定义冗余性判断函数 f_h,其输出冗余性标签,例如当人脸位置检测框输出为空时,将该次推理计算视为冗余。属于函数族 G 的输入过滤器 g 定义为从输入数据到冗余标签的映射函数。

假设原始推理模型的目标函数(即提供真实标签的函数)为 c ,其过滤器的目标函数为 ,则可见训练原始的推理模型和训练输入过滤器的区别在于监督标签的不同:推理预测由原始任务标签域 Y 监督,而过滤预测由冗余标签域 Z 监督。那么对于推理任务的可过滤性一个直观的想法是,如果学习输入过滤器比学习原始推理模型更简单,则有潜力得到有效的输入过滤器。
,则可见训练原始的推理模型和训练输入过滤器的区别在于监督标签的不同:推理预测由原始任务标签域 Y 监督,而过滤预测由冗余标签域 Z 监督。那么对于推理任务的可过滤性一个直观的想法是,如果学习输入过滤器比学习原始推理模型更简单,则有潜力得到有效的输入过滤器。
基于此思路,该工作分析了三类常见推理任务的可过滤性:

分析过程的关键在于将输入过滤器的目标函数与原始推理模型相关联,从而在两个学习任务间建立复杂度可比较的桥梁。以分类任务基于置信度进行冗余判别为例,输入过滤器的目标函数族形式为 ,依此可证明输入过滤器的函数族的 Rademarcher 复杂度小于等于原始推理模型,进而得到该任务可过滤性的分析结果。
,依此可证明输入过滤器的函数族的 Rademarcher 复杂度小于等于原始推理模型,进而得到该任务可过滤性的分析结果。
框架设计和实现
以上的可过滤性分析基于将输入过滤视为一个学习任务得到,因此框架设计需要具有端到端可学性,而不依赖手工特征或预训练深度特征。同时,框架设计应该统一地支持推理跳过(SKIP)和推理重用(REUSE)机制。该工作基于一个简洁的思路,即 SKIP 等价于对全零输入的推理结果的 REUSE,将两种机制统一到一个框架之中。
框架包含训练和推理两个阶段。训练阶段通过孪生特征网络为一对输入数据抽取特征,计算特征距离后由一个分类网络得到冗余标签预测结果。

在推理阶段,若采用 SKIP 机制,则将另一个输入的特征固定为零,退化为基本的分类器,根据预测的冗余性标签决策是否跳过当前输入数据;若采用 REUSE 机制,则需要维护一个 “输入特征 - 推理输出” 表作为缓存,通过计算当前输入特征与缓存的输入特征之间的距离,采用 K - 近邻方法决策是否重用缓存的推理结果。
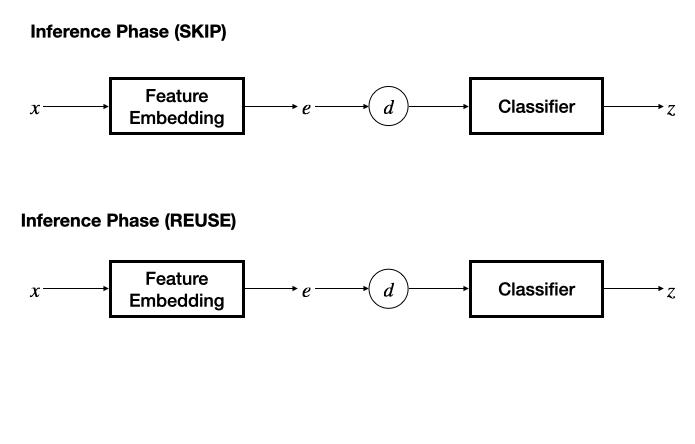
该工作提出了 “模态相关的特征网络 + 任务无关的分类网络” 的设计,为文本、图像、视频、音频、感知信号、中间层特征设计了特征抽取网络,并能够很容易地扩展至更多数据模态,分类器网络则设计为多层感知机模型。对输入模态的灵活支持为 InFi 在不同的任务部署方式上的适用性提供了基础,包括三种典型的以移动为中心的推理任务部署方式:端上推理、卸载至边缘推理、端 - 边模型切分推理。
InFi 使用 Python 实现,深度学习模块基于 TensorFlow 2.4,目前代码已开源。
验证实验
InFi 在 5 个数据集上的 12 种人工智能推理任务上进行了验证实验,涵盖图片、视频、文本、音频、运动信号、中间层特征六种输入模态。与三个基线方法的对比实验表明,InFi 具有更广泛的适用性,并且在准确性和效率上都更优。
以在城市道路监控视频中进行车辆计数的任务为例,在端上推理时,相较于原始的工作流,采用 SKIP 和 REUSE 机制的 InFi 方法分别能够将推理吞吐提升 1.9 和 7.5 倍,同时皆保持超过 90% 的推理精度;在进行端 - 边模型切分推理时,两种机制下的 InFi 分别能够节省 70.7% 和 95.0% 的通信带宽。

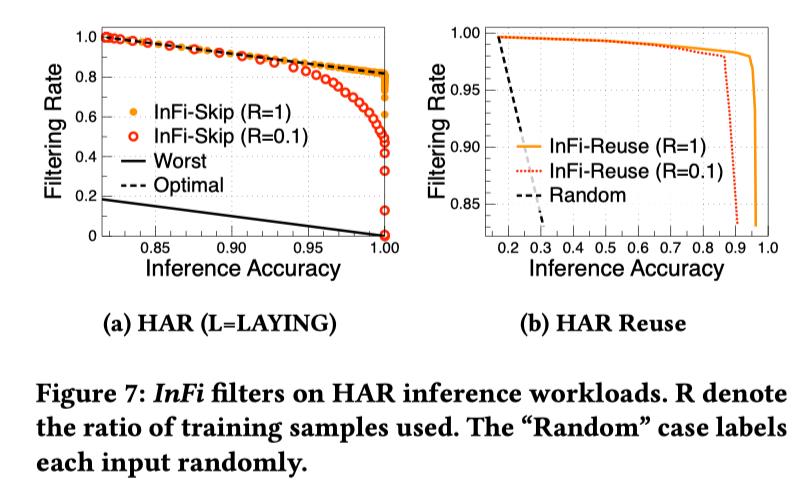
InFi 的训练成本也很低。在一个基于运动信号的动作识别应用中,仅使用 10% 的训练数据集即可得到过滤表现接近最优的 SKIP 和 REUSE 结果。InFi 可在保持超过 95% 推理精度的情况下,节省 80% 的推理运算。
结论与未来展望
该工作首次给出了可过滤性的理论分析,提出了统一的端到端可学的输入过滤框架,并在广泛的人工智能推理任务中验证了其设计和实现的优越性,对于实现以移动为中心的资源高效的推理有着重要的意义。InFi 框架的一大优点在于无需人工标注,未来可能会形成新的人工智能模型部署的最佳实践,即在每个模型的推理服务期间,自监督地训练输入过滤器,实现精度 - 资源权衡的模型推理。
论文引用:
Mu Yuan, Lan Zhang, Fengxiang He, Xueting Tong, and Xiang-Yang Li. 2022. InFi: End-to-end Learnable Input Filter for Resource-efficient Mobilecentric Inference. In The 28th Annual International Conference On Mobile Computing And Networking (ACM MobiCom ’22), October 24–28, 2022, Sydney, NSW, Australia. ACM, New York, NY, USA, 14 pages. https://doi.org/10.1145/ 3495243.3517016
---------♥---------
声明:本内容来源网络,版权属于原作者
图片来源网络,不代表本公众号立场。如有侵权,联系删除
AI博士私人微信,还有少量空位


点个在看支持一下吧

以上是关于中科大提出统一输入过滤框架InFi的主要内容,如果未能解决你的问题,请参考以下文章