Flink学习中之timewatermarkstate
Posted 柳小葱
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Flink学习中之timewatermarkstate相关的知识,希望对你有一定的参考价值。
🌿今天我们来了解一下flink中的几个重要基础概念:time、watermark、state,这是flink流处理中实现数据流执行速度快和结果正确的要点,对往期内容感兴趣的同学可以看下面👇:
- 链接: Flink学习专辑.
🌰其实在前面的章节中,我们也介绍了一些时间、状态的概念,但不够深入,本篇博客将从flink的运行机制上说明这些概念在流处理框架中的作用。
目录
1. Time
flink的时间语义主要分为3种:
- Event Time: 事件时间,它通常由事件中的时间戳描述,例如采集的
日志数据中,每一条日志都会记录自己的生成时间 - Ingestion Time:进入时间,是指数据进入flink的事件
- Processing Time:操作时间,是每一个执行基于时间操作的算子的本地系统时间,与机器相关,默认的时间属性就是 Processing Time
一般来说,绝大一部分业务都会采用 Event Time,如果Event Time无法使用,才会使用Ingestion Time和Processing Time,如果我们重视时间真实发生的时间或者要保证数据恢复前和恢复后保持一致,那么我们需要用Event Time作为时间标准,如果我们对事件的准确性要求不高,但对运行速度要求很高时,我们就可以选择Processing Time。
2. Watermark
我们一般采用Event Time模式处理流数据,这就代表数据的时间戳来源于数据里的时间,但数据在进行传输、分区等的操作,会使得数据乱序到达flink,导致计算不正确。
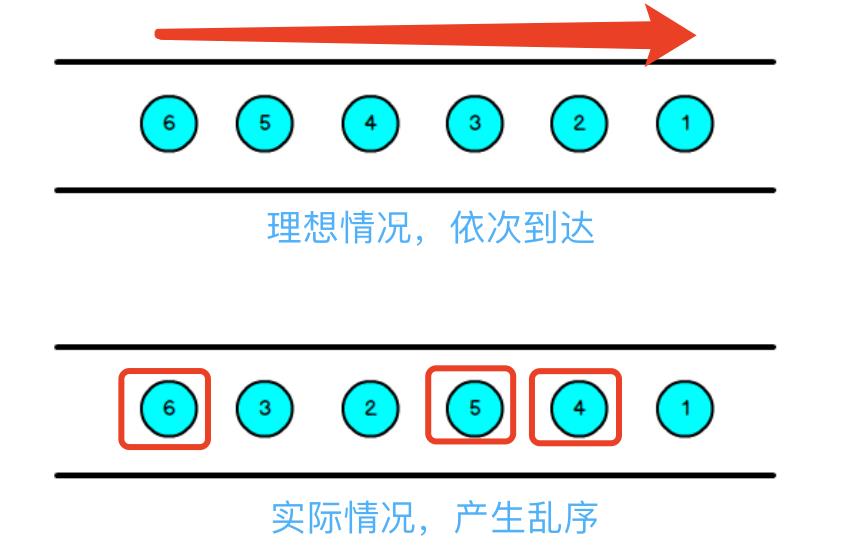
于是,便有了watermark这个概念,用来避免乱序数据带来的时间不正确。
2.1 Watermark的作用
- Watermark 是一种衡量 Event Time 进展的机制。
- Watermark 是用于处理乱序事件的,而正确的处理乱序事件,通常用Watermark 机制结合 window 来实现。
- 数据流中的 Watermark 用于表示 timestamp 小于 Watermark 的数据,都已经到达了,因此,window 的执行也是由 Watermark 触发的。
- Watermark 可以理解成一个延迟触发机制,我们可以设置 Watermark 的延时时长 t,每次系统会校验已经到达的数据中最大maxEventTime,然后认定 eventTime小于 maxEventTime - t 的所有数据都已经到达,如果有窗口的停止时间等于maxEventTime – t,那么这个窗口被触发执行。
2.2 Watermark的特点

- watermark 是一条特殊的数据记录
- watermark 必须单调递增,以确保任务的事件时间时钟在向前推进,而不是在后退
- watermark 与数据的时间戳相关
2.3 Watermark的案例
如图,下面有一组乱序数据流,watermark=2,窗口大小为5:

- Watermark=maxEventTime - 2
- 每来一个数据都会计算一次Watermark,一旦Watermark 比当前未触发的窗口的停止时间要晚,那么就会触发相应窗口的执行。
- 如果运行过程中无法获取新的数据时间戳,那么没有被触发的窗口将永远都不被触发。
2.3 Watermark的设定
- 在 Flink 中,watermark 由应用程序开发人员生成,这通常需要对相应的领域有一定的了解
- 如果watermark设置的延迟太久,收到结果的速度可能就会很慢,解决办法是在水位线到达之前输出一个近似结果
- 而如果watermark到达得太早,则可能收到错误结果,不过 Flink 处理迟到数据的机制可以解决这个问题
3. State
3.1 状态的定义
我们先来看张图:
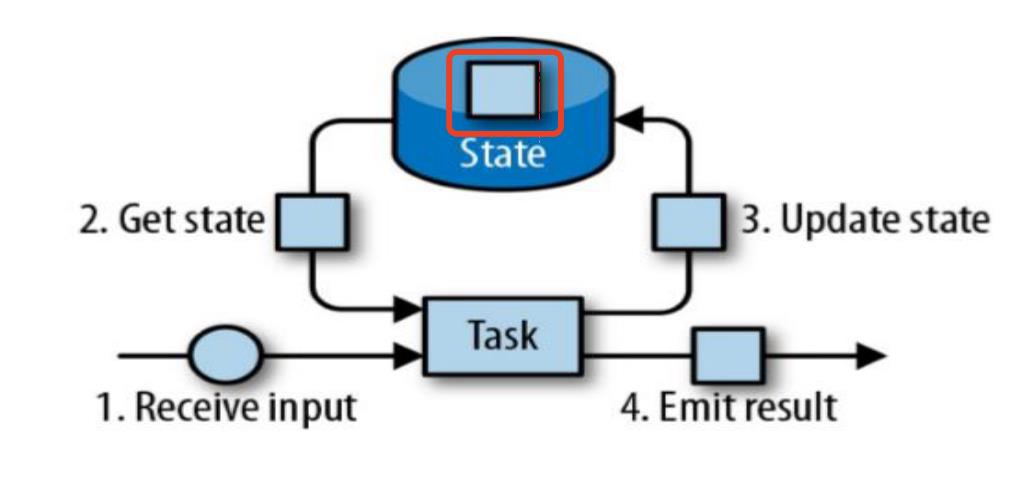
在流式计算框架中,对于简单的map、filter、flatmap这样简单的算子,我们的数据只需要来一条处理一条,处理过程不需要用到状态,而像reduce(),count(),sum()这样的算子,在处理数据时,虽然也是来一条处理一条,但是处理过程中需要获取之前的状态,根据之前的状态和刚输入的数据来计算新的计算结果。
- 由一个任务维护,并且用来计算某个结果的所有数据,都属于这个任务的状态。
- 可以认为状态就是一个本地变量(放在内存中),可以被任务的业务逻辑访问。
- Flink 会进行状态管理,包括状态一致性、故障处理以及高效存储和访问,以便开发人员可以专注于应用程序的逻辑。
3.2 状态的分类
- 在 Flink 中,状态始终与特定算子相关联
- 为了使运行时的 Flink 了解算子的状态,算子需要预先注册其状态
3.1.1 算子状态(Operator State)
所谓算子状态,就是算子状态的作用范围限定为算子任务,在同一个分区,访问的状态都是同一个状态,特点如下:
- 算子状态的作用范围限定为算子任务,由同一并行任务所处理的所有数据都可以访问到相同的状态
- 状态对于同一子任务而言是共享的
- 算子状态不能由相同或不同算子的另一个子任务访问
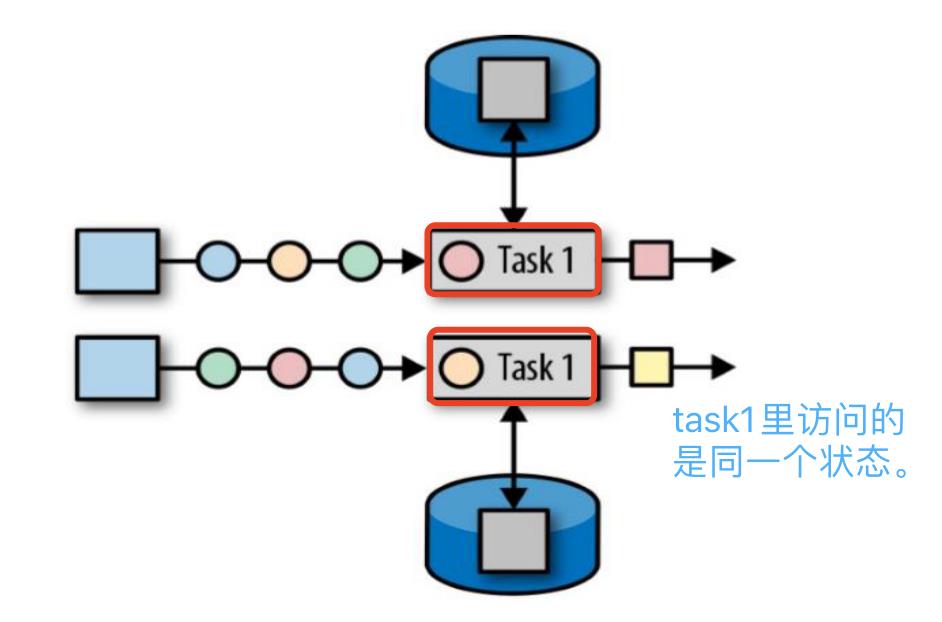
算子状态有以下几种:
- 列表状态(List state):将状态表示为一组数据的列表
- 联合列表状态(Union list state):也将状态表示为数据的列表。它与常规列表状态的区别在于,在发生故障时,或者从保存点(savepoint)启动应用程序时如何恢复
- 广播状态(Broadcast state):如果一个算子有多项任务,而它的每项任务状态又都相同,那么这种特殊情况最适合应用广播状态。
3.1.2 键控状态(Keyed State)
键控状态是指根据数据流的key值来访问状态,特点如下:
- 键控状态是根据输入数据流中定义的键(key)来维护和访问的
- Flink 为每个 key 维护一个状态实例,并将具有相同键的所有数据,都分区到同一个算子任务中,这个任务会维护和处理这个 key 对应的状态
- 当任务处理一条数据时,它会自动将状态的访问范围限定为当前数据的 key
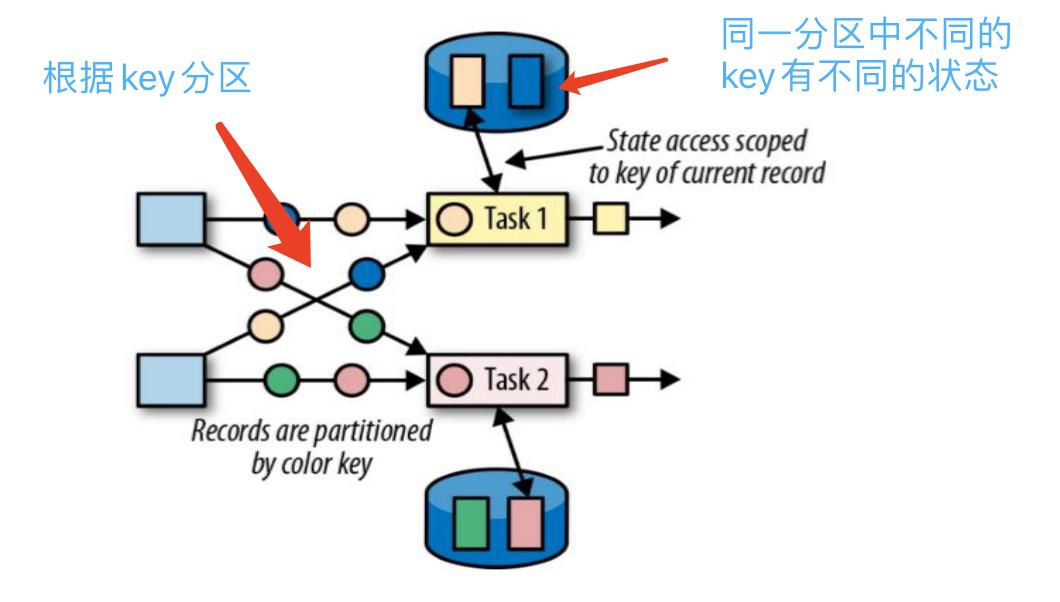
如图:根据key值进行分区操作,相同key的值在一个分区,不同key的值也在一个分区,但状态是根据key值维护的,即同一个分区的相同的key访问的是同一个key。
键控状态有以下几种:
- 值状态(Value state): 将状态表示为单个的值
- 列表状态(List state):将状态表示为一组数据的列表
- 映射状态(Map state):将状态表示为一组 Key-Value 对
- 聚合状态(Reducing state & Aggregating State):将状态表示为一个用于聚合操作的列表
3.3 状态后端(State Backends)
定义:状态的存储、访问以及维护,由一个可插入的组件决定,这个组件就叫做状态后端(state backend),状态后端主要负责两件事:本地的状态管理,以及将检查点(checkpoint)状态写入远程存储
状态后端端种类:
- MemoryStateBackend
内存级的状态后端,会将键控状态作为内存中的对象进行管理,将它们存储在TaskManager 的 JVM 堆上,而将 checkpoint 存储在 JobManager 的内存中,特点:快速、低延迟,但不稳定。
- FsStateBackend
将 checkpoint 存到远程的持久化文件系统(FileSystem)上,而对于本地状态,跟 MemoryStateBackend 一样,也会存在 TaskManager 的 JVM 堆上,同时拥有内存级的本地访问速度,和更好的容错保证。
- RocksDBStateBackend
将所有状态序列化后,存入本地的 RocksDB 中存储。
4. 总结
今天详细介绍了flink中time、watermark、state的原理和程序运行中的主要作用,为后续更好地了解flink容错机制和状态一致性保证做铺垫。
5. 参考文章
《尚硅谷Java版Flink》
《Flink入门与实战》
《PyDocs》(pyflink官方文档)
《Kafka权威指南》
《Apache Flink 必知必会》
《Apache Flink 零基础入门》
《Flink 基础教程》
以上是关于Flink学习中之timewatermarkstate的主要内容,如果未能解决你的问题,请参考以下文章