Zookeeper架构及流程
Posted 奋斗哼哼
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Zookeeper架构及流程相关的知识,希望对你有一定的参考价值。
1. Zookeeper概述
zookeeper是一个分布式协调服务软件,最重要的特性是:全局数据一致性.
zookeeper集群包含三个角色:
- 主节点:leader
主节点主要负责:
①负责管理整个集群,保证全局数据一致性
②负责处理数据事务(包括增删改等)请求
③负责转发非事务(查)请求给从节点 - 从节点:follower
从节点主要负责:
①实时从主节点拉取数据,保证全局数据一致性
②负责处理非事务(查)请求
③负责转发事务(增删改)请求给主节点
④有投票选举权 - 观察者:observer
在这里,除了没有投票权,其作用和follow作用一样
2. Zookeeper自身选举流程
- 每个zookeeper节点都会投票给myid最大的那个机器.
- 没有选出主节点之前,每启动一个新的机器,都会选举一次
- 采用过半原则,得到票数超过集群的一半的节点,该节点即为主节点,其他节点为从节点.
3. Zookeeper架构图
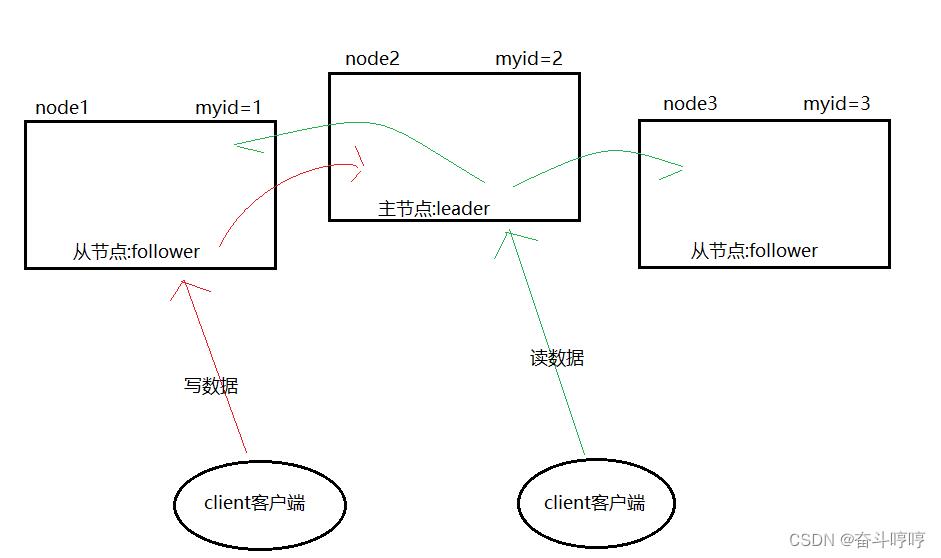
- 当客户端向node1提出增删改等数据请求时,因为node1为从节点(follower),并不负责处理事务型请求,所以node1会将请求转发给node2(主节点)进行处理.
- 当客户端向node2发出事务型请求时,直接由node2处理
- 当客户端向主节点发出非事务型(查/读)请求时,node2会将请求转发给node1或者node3进行处理.
- 当客户端直接向node1或者node3发出非事务(查)请求时,直接由node1或者node3处理.
Zookeeper主备切换
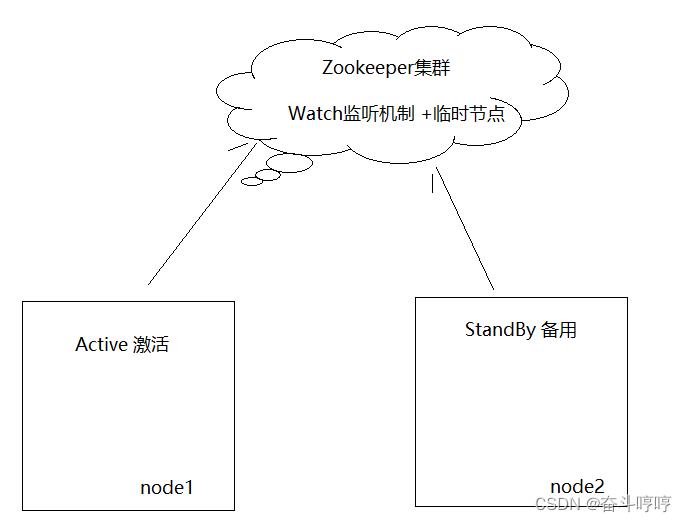
- 当集群启动时,所有主节点都会抢占式的去Zookeeper的指定节点下创建1个临时节点,谁抢到谁就是Active,其他的都是StandBy.
- 所有的StandBy状态的节点都会实时监听Zookeeper下的那个临时文件的信息,即:注册监听
- 当前Active节点(例如node1)会话断开时,该临时节点消失,即:事件触发
- 此时其他Standby节点(例如node2)就知道了node1宕机了,就会从Standby状态变为Active状态,并开始工作.
Watch监听机制
- 先注册监听事件
- 当监听事件被触发时会获取结果.即:先注册, 后触发, 然后获取结果.
- Zookeeper的Watch监听机制是一次触发的,触发一次之后,该监听事件消失,再次使用需要重新监听.
Kafka-kraft模式架构及部署流程
一. Kafka-kraft架构
由于Kafka依赖于zookeeper集群做元数据管理,2.8版本以后kafka引入kraft代替zk,图为zk模式的架构和kraft模式的架构对比
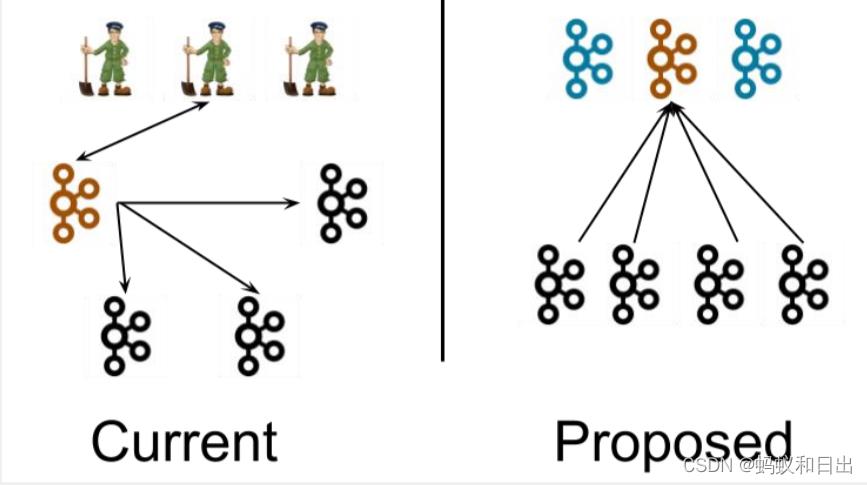
左图为 Kafka 现有架构,元数据在 zookeeper 中,运行时动态选举 controller,由 controller 进行 Kafka 集群管理。右图为 kraft 模式架构,不再依赖 zookeeper 集群, 而是用三台 controller 节点代替 zookeeper,元数据保存在 controller 中,由 controller 直接进行 Kafka 集群管理。
这样做的好处有以下几个:
- Kafka 不再依赖外部框架,而是能够独立运行;
- controller 管理集群时,不再需要从 zookeeper 中先读取数据,集群性能上升;
- 由于不依赖 zookeeper,集群扩展时不再受到 zookeeper 读写能力限制;
二. Kafka-kraft部署流程
1. 下载并安装2.8版本以后的kafka,并切换到config/kraft目录下

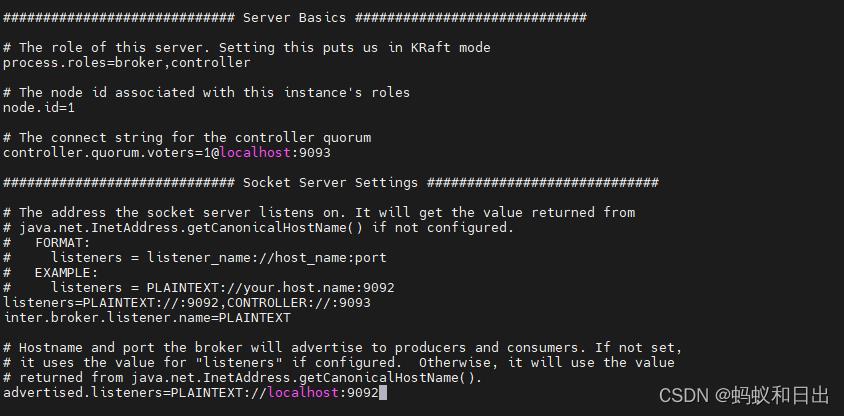
2. 修改server.properties文件
3. 生成存储目录唯一id
bin/kafka-storage.sh random-uuid
4. 用该id格式化kafka存储目录
bin/kafka-storage.sh format -t 6iKNOdeiSvaaypYCcWKsYw -c config/kraft/server.properties5. 启动kafka
bin/kafka-server-start.sh -daemon config/kraft/server.properties以上是关于Zookeeper架构及流程的主要内容,如果未能解决你的问题,请参考以下文章