YARN基础+Yarn组件+Yarn架构和工作流程+Yarn三种调度器+MR流程+zookeeper
Posted ListenerDMT
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了YARN基础+Yarn组件+Yarn架构和工作流程+Yarn三种调度器+MR流程+zookeeper相关的知识,希望对你有一定的参考价值。
目录
2、第二种Capacity Scheduler 容量调度器 (默认使用的)
一、YARN是什么
YARN负责Hadoop中得资源管理(包括cpu、内存、磁盘、网络IO等),以及调度运行在yarn上的任务。
二、YARN主要组件说明
YARN的主要组件:ResourceManager、NodeManager、ApplicationMaster和Container
1、ResourceManager(RM)
主要负责处理客户端请求对各NM上的资源进行统一调度和管理,给ApplicationMaster分配空闲的Container 运行并监控其运行状态。
主要由两个组件构成 调度器(Scheduler) 和应用程序管理器(Applications Manager)
调度器 ---》根据各个应用程序资源需求进行分配(分配的资源封装在Container 中)。
应用程序管理器--》YARN资源控制框架的中心模块,负责集群中所有资源的统一的管理和分配。
2、NodeManager(NM)
相当于ResourceManager在每台机器上的代理。定时向RM汇报本节点资源的使用情况和Container 的运行状态,它还会处理来自ApplicationMaster的Container 启动或停止请求。
3、ApplicationMaster(AM)
YARN中每启动一个任务就会启动一个AM,它可以负责向RM申请资源,请求NM启动Container,并告诉Container做什么,,它还可以重启失败的任务。
4、Container
(1)container是YARN中资源的抽象,它封装了某个节点上的一定的资源(cpu、内存、磁盘、网络等),YARN中所有的应用都是在其上运行的,包括AM
(2)Container是由AM向RM申请的,由RM中的scheduler分配给AM
三、YARN的架构和工作流程
1、运行流程图如图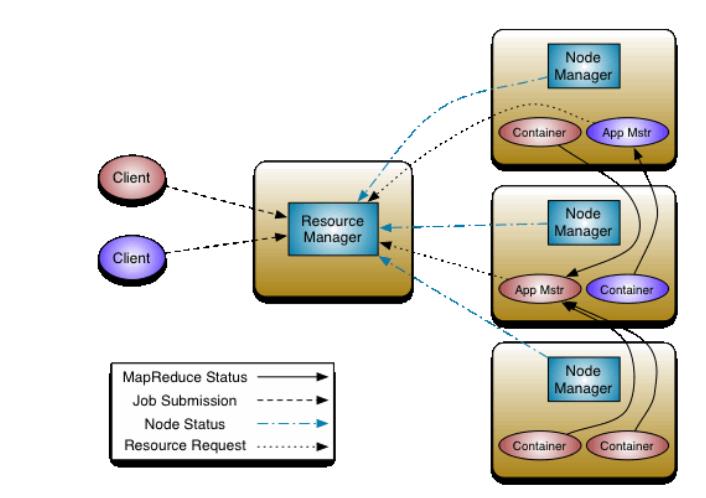
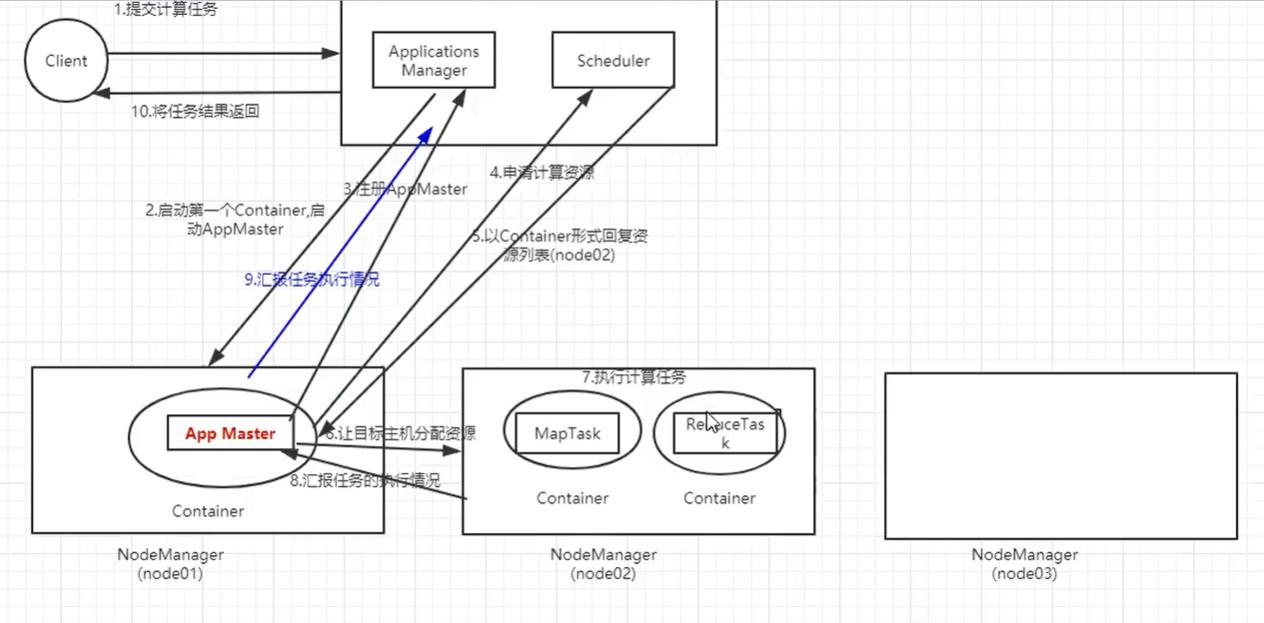
2、运行流程解释
(1)Client向RM提交计算任务,例如wordcount案例
(2)RM收到这个计算任务后,首先会进行权限的检查,再查看一下整个集群的负载情况,判断集群是否有能力承担计算任务
(3)Application Manager找一台NM,在这台主机上启动一个Container,并在Container上启动App Master
(4)AM向RM进行一个注册,使得用户可以直接通过RM来查看程序运行状态
(5)AM计算执行任务所需要资源,并向RM中的Scheduler申请
(6)Scheduler 以Container形式向AM回复资源列表
(7)AM让目标主机分配资源
(8)目标主机启动Container去执行具体的计算任务(可能在不同的Container上有MapTask或者Reduce Task)
(9)在任务执行的同时,执行任务的主机还会向AM汇报任务执行情况
(10)AM收到情况的时候也可以向RM汇报执行情况
(11)在遇到特殊情况时,比如任务失败,AM还可以去重启任务
(12)任务执行成功后,AM收到消息汇报,然后再汇报给RM并申请注销关闭,RM在将结果返回给客户端
总结:简单来说 启动AM并申领资源,然后运行任务直到完成。
3、几个简单问题
(1)AM在哪个进程所在节点运行?
NM
(2)AM要申请Container吗?向谁申请?
要,向RM
(3)第一个Container运行的什么?
AM
四、YARN的调度器
1、 第一种 FIFO Scheduler 队列调度器
先进先出,容易导致大的任务占用集群所有的资源,其它任务被阻塞
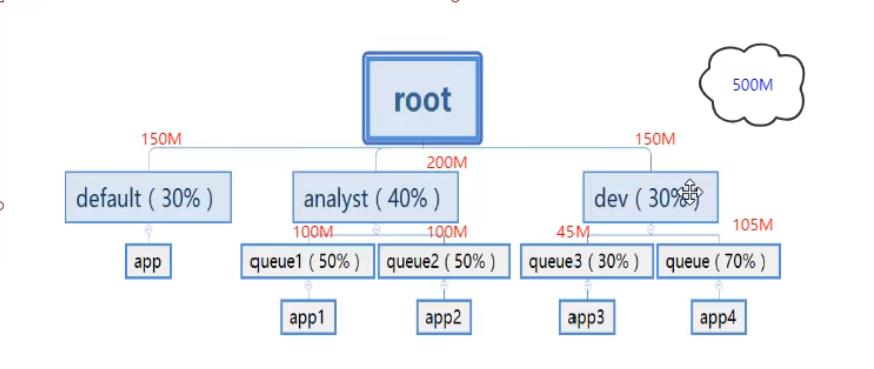
2、第二种Capacity Scheduler 容量调度器 (默认使用的)
如下:实现一种动态的分配
3、第三种 Fair Scheduler 公平调度器
公平分配 ,每个用户平均分配,用户下job也平均分配

五、关于MapReduce流程
map:映射,把一个任务拆解成多个
reduce:聚合,把拆解开的任务做最后的聚合
MR运行中的进程 YarnChild(MapTask ReduceTask)
MRAppMaster MapTask ReduceTask 都是以进程的方式运行的,那么进程申请资源,运行,释放资源,这就是MR慢的一个原因
六、思考题
1、关于进程和线程的区别
(1)进程是执行中的一段程序,而进程中执行的每一个任务即为一个线程。
(2)一个线程 属于一个进程,一个进程可以包含多个线程
(3)线程没有地址空间,它是包含在进程的地址空间里
(4)线程的开销代价比进程小
2、关于zookeeper
(1)zookeeper的作用
它是一个开源的分布式协调服务框架,主要用来解决分布式集群中的应用系统的一致性问题和数据管理问题
(2) zookeeper角色及作用
zookeeper架构如下
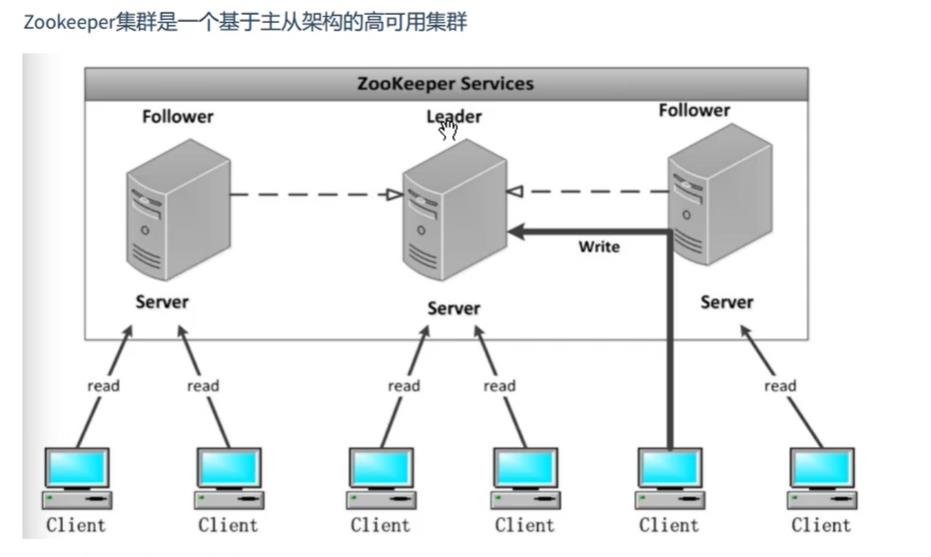
每个服务器承担如下三个角色之一
(1)Leader:一个ZK集只会有一个实际工作的Leader,它会发起并维护与各个Follower及Observe间的心跳。所有的写操作只能Leader完成,并由它广播给其它服务器,也可投票
(2)Follower:一个ZK集群可由多个Follower,它会响应Leader心跳,Follower可处理读请求,对于写请求必须转发给Leader处理,并且负责在Leader处理写请求时,进行投票。
(3)Observe:与Follower类似,但是没有投票权。
注:Follower和Observe统称为Learner
(3)zookeeper有几种状态,分别是什么?
共有四种状态
(1) LOOKING:寻找 Leader 状态。当服务器处于该状态时,它会认为当前服务器没有 Leader,因此需要进入 Leader 选举状态。
(2)FOLLOWING:跟随者状态。表明当前服务器角色是 Follower。
(3)LEADING:领导者状态。表明当前服务器角色是 Leader。
(4)OBSERVING:观察者状态。表明当前服务器角色是 Observer。
(4)zookeeper选举的流程和算法
比如
目前有5台服务器,每台服务器均没有数据,它们的编号分别是1,2,3,4,5,按编号依次启动,它们的选择举过程如下:
- 服务器1启动,给自己投票,然后发投票信息,由于其它机器还没有启动所以它收不到反馈信息,服务器1的状态一直属于Looking(选举状态)。
- 服务器2启动,给自己投票,同时与之前启动的服务器1交换结果,由于服务器2的编号大所以服务器2胜出,但此时投票数没有大于半数,所以两个服务器的状态依然是LOOKING。
- 服务器3启动,给自己投票,同时与之前启动的服务器1,2交换信息,由于服务器3的编号最大所以服务器3胜出,此时投票数正好大于半数,所以服务器3成为领导者,服务器1,2成为小弟。
- 服务器4启动,给自己投票,同时与之前启动的服务器1,2,3交换信息,尽管服务器4的编号大,但之前服务器3已经胜出,所以服务器4只能成为小弟。
- 服务器5启动,后面的逻辑同服务器4成为小弟。
Hadoop Yarn 一文搞懂 Yarn架构原理和工作机制
@
详解Yarn基础架构及其设计思想
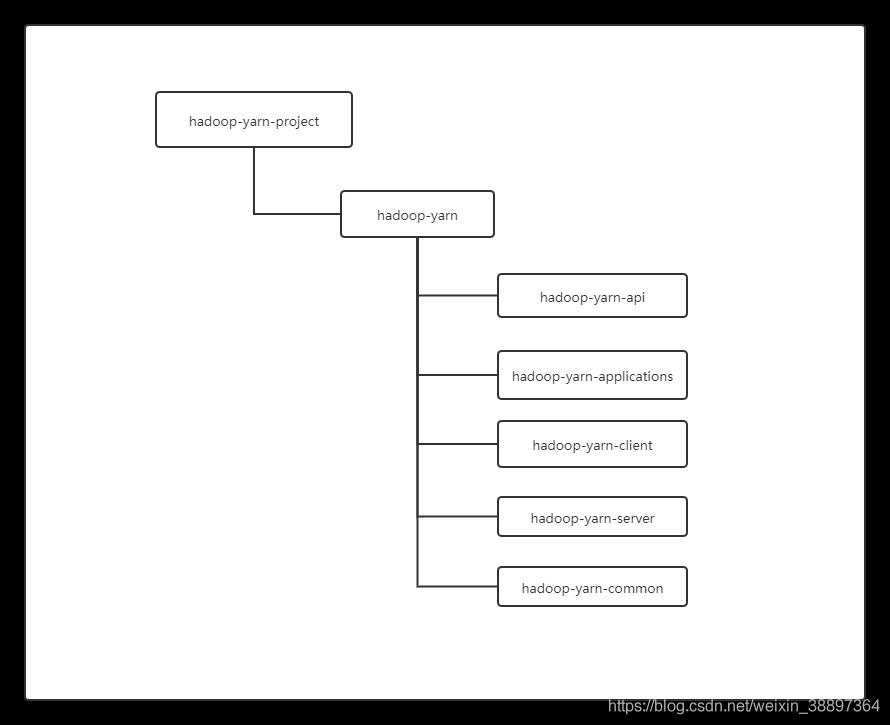
1.Hadoop Yarn 目录组织结构
- YARN API(hadoop-yarn-api 目录):给出了 YARN 内部涉及的 4 个主要 RPC 协议的 Java 声明和 Protocol Buffers 定义,这 4 个 RPC 协议分别是 ApplicationClientProtocol、 ApplicationMasterProtocol、ContainerManagementProtocol 和 ResourceManagerAdmi nistrationProtocol。
- YARN Common(hadoop-yarn-common 目录):该部分包含了 YARN 底层库实现, 包括事件库、服务库、状态机库、Web 界面库等;
- YARN Applications(hadoop-yarn-applications 目录):该部分包含了两个 Application 编程实例,分别是 distributedshell 和 Unmanaged AM;
- YARN Client(hadoop-yarn-client 目录):该部分封装了几个与 YARN RPC 协议交互 相关的库,方便用户开发应用程序;
- YARN Server(hadoop-yarn-server 目录):该部分给出了 YARN 的核心实现,包括 ResourceManager、NodeManager、资源管理器等核心组件的实现。
2.Yarn 产生背景
2.1 MRv1局限性
我们都知道Yarn是MRV2中才有的Hadoop组成部分,是MRv1存在各种局限性导致,其局限性大致概括为以下方面:
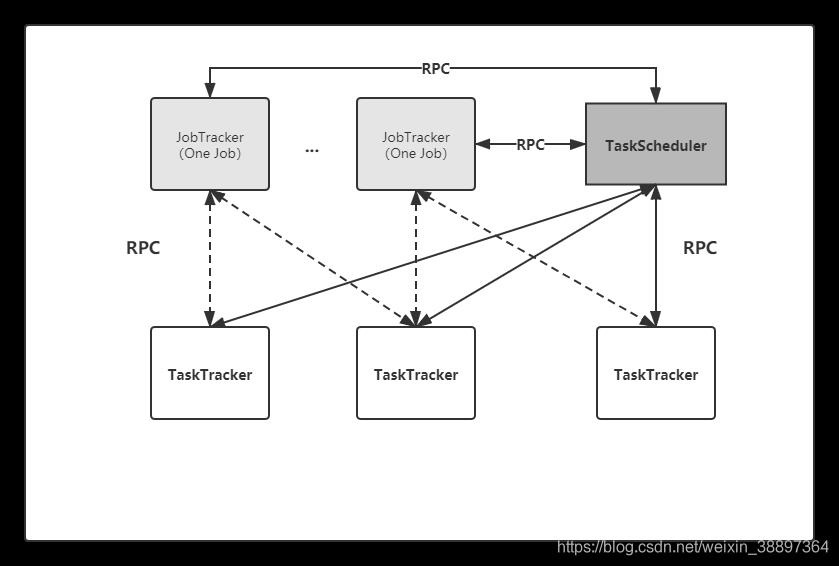
- 拓展性差:在MRv1中,JobTracker同时兼备了资源管理和作业控制两个功能,这 成为系统的一个最大瓶颈,严重制约了 Hadoop 集群扩展性。
- 可靠性差。MRv1 采用了 master/slave 结构,其中,master 存在单点故障问题,一旦 它出现故障将导致整个集群不可用。
- 资源利用率低。MRv1 采用了基于槽位的资源分配模型,槽位是一种粗粒度的资源 划分单位,通常一个任务不会用完槽位对应的资源,且其他任务也无法使用这些空 闲资源。此外,Hadoop 将槽位分为 Map Slot 和 Reduce Slot 两种,且不允许它们之 间共享,常常会导致一种槽位资源紧张而另外一种闲置(比如一个作业刚刚提交时, 只会运行 Map Task,此时 Reduce Slot 闲置)。
- 无法支持多种计算框架。随着互联网高速发展,MapReduce 这种基于磁盘的离线计 算框架已经不能满足应用要求,从而出现了一些新的计算框架,包括内存计算框架、 流式计算框架和迭代式计算框架等,而 MRv1 不能支持多种计算框架并存。
正是由于 MRv2 将资源管理功能抽象成了一个 独立的通用系统 YARN,直接导致下一代 MapReduce 的核心从单一的计算框架 MapReduce转移为通用的资源管理系统 YARN。
2.2 轻量级弹性计算平台
随着互联网的高速发展,基于数据密集型应用的计算框架不断出现,从支持离线处理 的 MapReduce,到支持在线处理的 Storm,从迭代式计算框架 Spark 到流式处理框架 S4,等等。各种框架有其应用的场景。而在实际互联网公司中,这几种框架不是选其一,而是根据场景有不同的选择共同构建整个计算框架。考虑成本、运维、数据共享等等因素,实际更希望的是将这些框架都部署到一个公共的集群中,共享集群资源,并对资源进行统一管理,同时采用某种资源隔离方案(如轻量级 cgroups)对各个任务进行隔离,这样便诞生了轻量级弹性计算平台。YARN 便是弹性计算平台的典型代表。
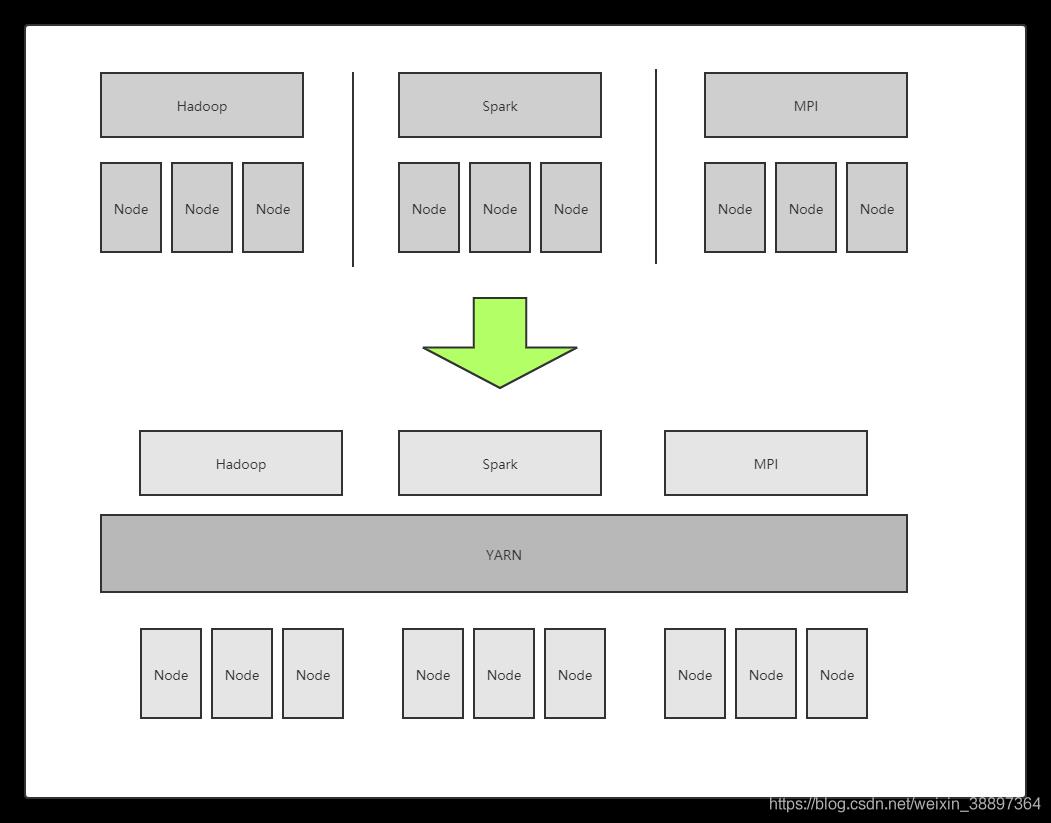
YARN 实际上是一个弹性计算平台,它的目标已经不再局限于支持 MapReduce 一种计算框架,而是朝着对多种框架进行统一管理的方向发展。
相比于“一种计算框架一个集群”的模式,共享集群的模式存在多种好处:
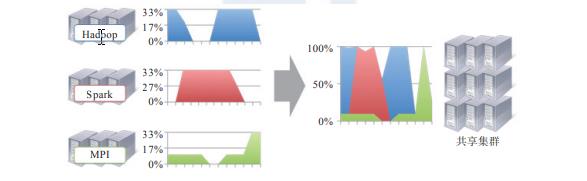
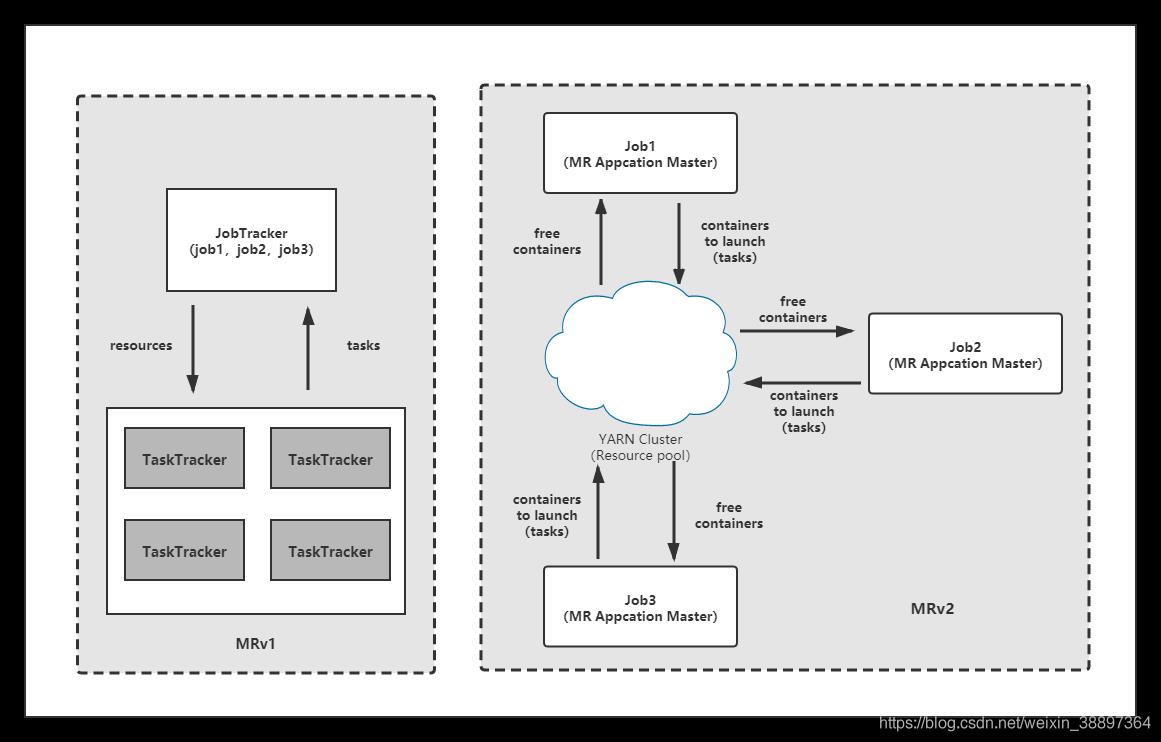
- 资源利用率高。如果每个框架一个集群,见下图,则往往由于应用程序数量 和资源需求的不均衡性,使得在某段时间内,有些计算框架的集群资源紧张,而另 外一些集群资源空闲。共享集群模式则通过多种框架共享资源,使得集群中的资源 得到更加充分的利用;
- 运维成本低。如果采用“一个框架一个集群”的模式,则可能需要多个管理员管理 这些集群,进而增加运维成本,而共享模式通常需要少数管理员即可完成多个框架 的统一管理。
- 数据共享。随着数据量的暴增,跨集群间的数据移动不仅需花费更长的时间,且硬 件成本也会大大增加,而共享集群模式可让多种框架共享数据和硬件资源,将大大 减小数据移动带来的成本。
3YARN基本设计思想
3.1 基本框架对比
在 Hadoop 1.0 中,JobTracker 由资源管理(由 TaskScheduler 模块实现)和作业控制(由 JobTracker 中多个模块共同实现)两部分组成。当前 Hadoop MapReduce 之所以在可扩展性、资源利用率和多框架支持等方面存在不足,正是由于 Hadoop 对 JobTracker 赋予的功能过多而造成负载过重(正如一些公司既想要打工人能够做开发还要能做产品最好还能写前端并做UI的话,美名曰,“全栈”)。此外,从设计角度上看,Hadoop 未能够将资 源管理相关的功能与应用程序相关的功能分开,造成 Hadoop 难以支持多种计算框架。
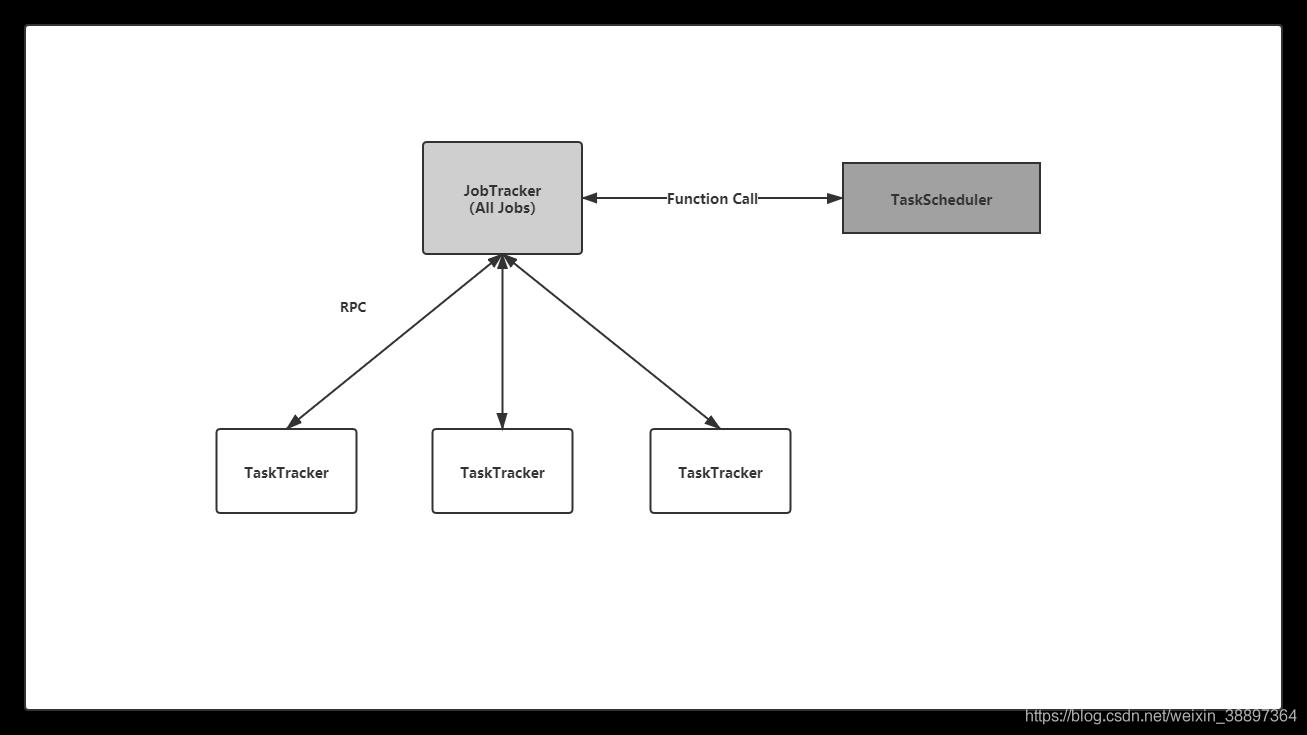
而Hadoop2.x框架的基本设计思想是将 JobTracker 的两个主要功能,即资源管理和作业控制(包括作业监控、容错等),分拆成两独立的进程。资源管理进 程与具体应用程序无关,它负责整个集群的资源(内存、CPU、磁盘等)管理,而作业控 制进程则是直接与应用程序相关的模块,且每个作业控制进程只负责管理一个作业。这样, 通过将原有 JobTracker 中与应用程序相关和无关的模块分开,不仅减轻了 JobTracker 负载, 也使得 Hadoop 支持更多的计算框架。
从资源管理角度看,MRv2 框架实际上衍生出了一个资源统一管理平台 YARN,它使得 Hadoop 不再局限于仅支持 MapReduce 一种计算模型,而是可无限融入多 种计算框架,且对这些框架进行统一管理和调度。
4 YARN基本架构
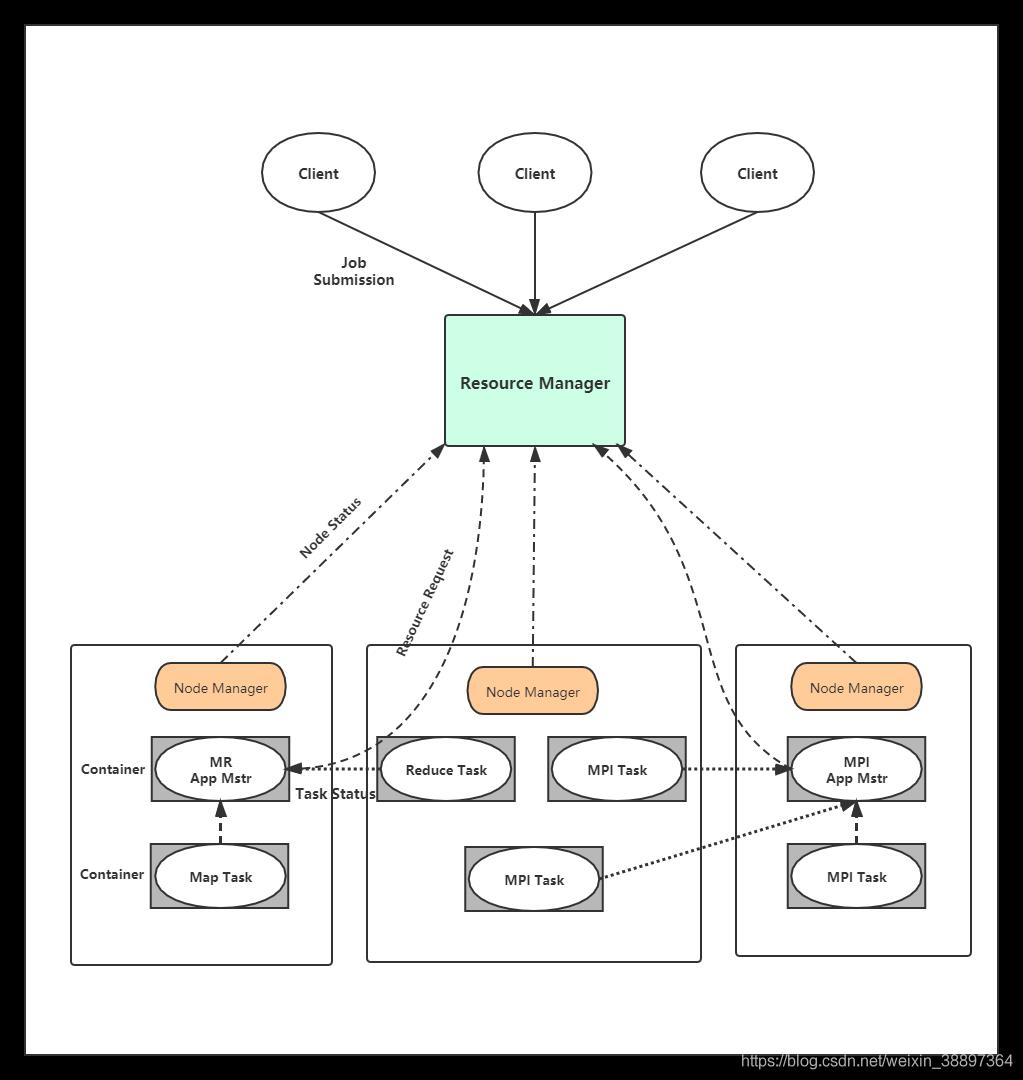
4.1 YARN基本组成结构
YARN 总体上仍然是 Master/Slave 结构,在整个资源管理框架中,ResourceManager 为 Master,NodeManager 为 Slave,ResourceManager 负责对各个 NodeManager 上的资源进行 统一管理和调度。当用户提交一个应用程序时,需要提供一个用以跟踪和管理这个程序的 ApplicationMaster,它负责向 ResourceManager 申请资源,并要求 NodeManger 启动可以占 用一定资源的任务。由于不同的 ApplicationMaster 被分布到不同的节点上,因此它们之间 不会相互影响。
YARN 主要由 ResourceManager、NodeManager、 ApplicationMaster(图中给出了 MapReduce 和 MPI 两种计算框架的 ApplicationMaster,分 别为 MR AppMstr 和 MPI AppMstr)和 Container 等几个组件构成。
-
1. ResourceManager(RM)
-
RM 是一个全局的资源管理器,负责整个系统的资源管理和分配。它主要由两个组件 构成:调度器(Scheduler)和应用程序管理器(Applications Manager,AM)。
- (1)调度器:调度器根据容量、队列等限制条件(如每个队列分配一定的资源,最多执行一定数量的作业等),将系统中的资源分配给各个正在运行的应用程序。
该调度器是 一个“纯调度器”,它不再从事任何与具体应用程序相关的工作,比如不负责监控或者跟踪 应用的执行状态等,也不负责重新启动因应用执行失败或者硬件故障而产生的失败任务, 这些均交由应用程序相关的 ApplicationMaster 完成。调度器仅根据各个应用程序的资源需求进行资源分配,而资源分配单位用一个抽象概念“资源容器”(Resource Container,简称 Container)表示,Container 是一个动态资源分配单位,它将内存、CPU、磁盘、网络等资源封装在一起,从而限定每个任务使用的资源量。
此外,该调度器是一个可插拔的组件, 用户可根据自己的需要设计新的调度器,YARN 提供了多种直接可用的调度器,比如 Fair Scheduler 和 Capacity Scheduler 等。
- (2)应用程序管理器
应用程序管理器负责管理整个系统中所有应用程序,包括应用程序提交、与调度器协商资源以启动 ApplicationMaster、监控 ApplicationMaster 运行状态并在失败时重新启动它等。
-
2.ApplicationMaster(AM)
用户提交的每个应用程序均包含一个 AM,主要功能包括:
❑ 与 RM 调度器协商以获取资源(用 Container 表示);
❑ 将得到的任务进一步分配给内部的任务;
❑ 与 NM 通信以启动 / 停止任务;
❑ 监控所有任务运行状态,并在任务运行失败时重新为任务申请资源以重启任务。
- 3. NodeManager(NM)
NM 是每个节点上的资源和任务管理器,一方面,它会定时地向 RM 汇报本节点上的资源使用情况和各个 Container 的运行状态;另一方面,它接收并处理来自 AM 的 Container 启动 / 停止等各种请求。
- 4.Container
Container 是 YARN 中的资源抽象,它封装了某个节点上的多维度资源,如内存、 CPU、磁盘、网络等,当 AM 向 RM 申请资源时,RM 为 AM 返回的资源便是用 Container 表示的。YARN 会为每个任务分配一个 Container,且该任务只能使用该 Container 中描述的 资源。Container是一个动态资源划分单位,是 根据应用程序的需求动态生成的。
目前YARN 仅支持 CPU 和内存两种资源, 且使用了轻量级资源隔离机制 Cgroups 进行资源隔离。
5 YARN的通信机制
RPC 协议是连接各个组件的“大动脉”,了解不同组件之间的 RPC 协议有助于我们更深入地学习 YARN 框架。在 YARN 中,任何两个需相互通信的组件之间仅有一个 RPC 协 议,而对于任何一个 RPC 协议,通信双方有一端是 Client,另一端为 Server,且 Client 总 是主动连接 Server 的,因此,YARN 实际上采用的是拉式(pull-based)通信模型。YARN 主要由以 下几个 RPC 协议组成:
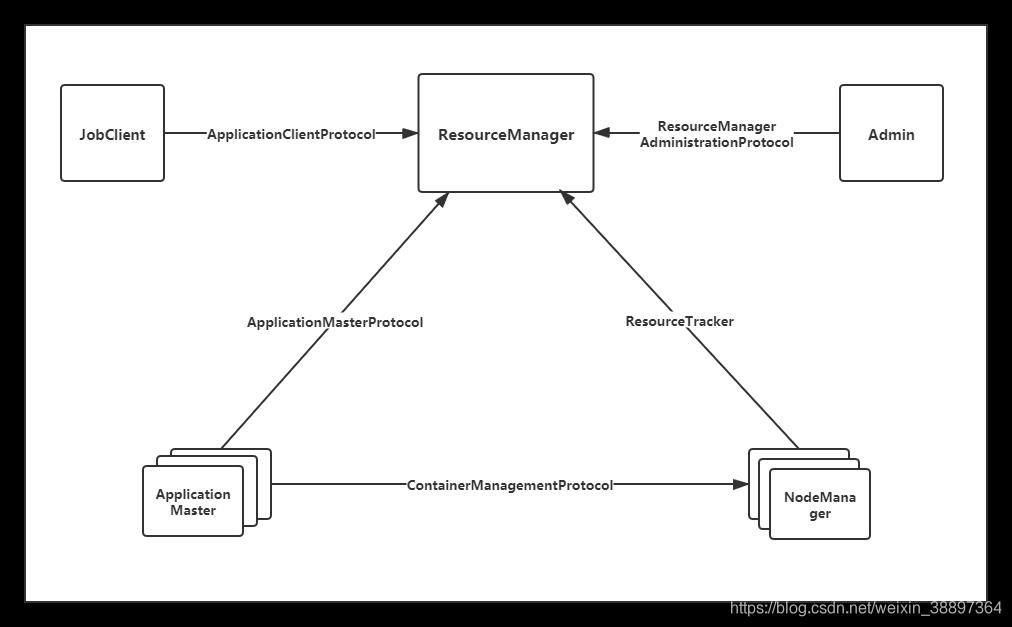
- JobClient(作业提交客户端)与 RM 之间的协议 —ApplicationClientProtocol : JobClient 通过该 RPC 协议提交应用程序、查询应用程序状态等。
- Admin(管理员)与 RM 之间的通信协议—ResourceManagerAdministrationProtocol: Admin 通过该 RPC 协议更新系统配置文件,比如节点黑白名单、用户队列权限等。
- **AM 与 RM 之间的协议—ApplicationMasterProtocol **:AM 通过该 RPC 协议向 RM 注册和撤销自己,并为各个任务申请资源。
- AM 与 NM 之 间 的 协 议 —ContainerManagementProtocol :AM 通 过 该 RPC 要 求 NM 启动或者停止 Container,获取各个 Container 的使用状态等信息。
- NM 与 RM 之间的协议—ResourceTracker :NM 通过该 RPC 协议向 RM 注册,并 定时发送心跳信息汇报当前节点的资源使用情况和 Container 运行情况。
6 YARN 工作流程
运行在 YARN 上的应用程序主要分为两类 :短应用程序和长应用程序,其中,
短应 用程序是指一定时间内(可能是秒级、分钟级或小时级,尽管天级别或者更长时间的也存 在,但非常少)可运行完成并正常退出的应用程序。比如:MapReduce作业。
长应用程序是指不出意外,永不终止运行的 应用程序,通常是一些服务,比如 Storm Service(主要包括 Nimbus 和 Supervisor 两类服 务),HBase Service(包括 Hmaster 和 RegionServer 两类服务) 等。
尽管这两类应用程序作用不同,一类直接运行数据处理程序,一类用于部署服务(服务之上再运行数据处理程序),但运行在 YARN 上的流程是相同的。
当用户向 YARN 中提交一个应用程序后,YARN 将分两个阶段运行该应用程序 :第一 个阶段是启动 ApplicationMaster ;第二个阶段是由 ApplicationMaster 创建应用程序,为它 申请资源,并监控它的整个运行过程,直到运行完成。
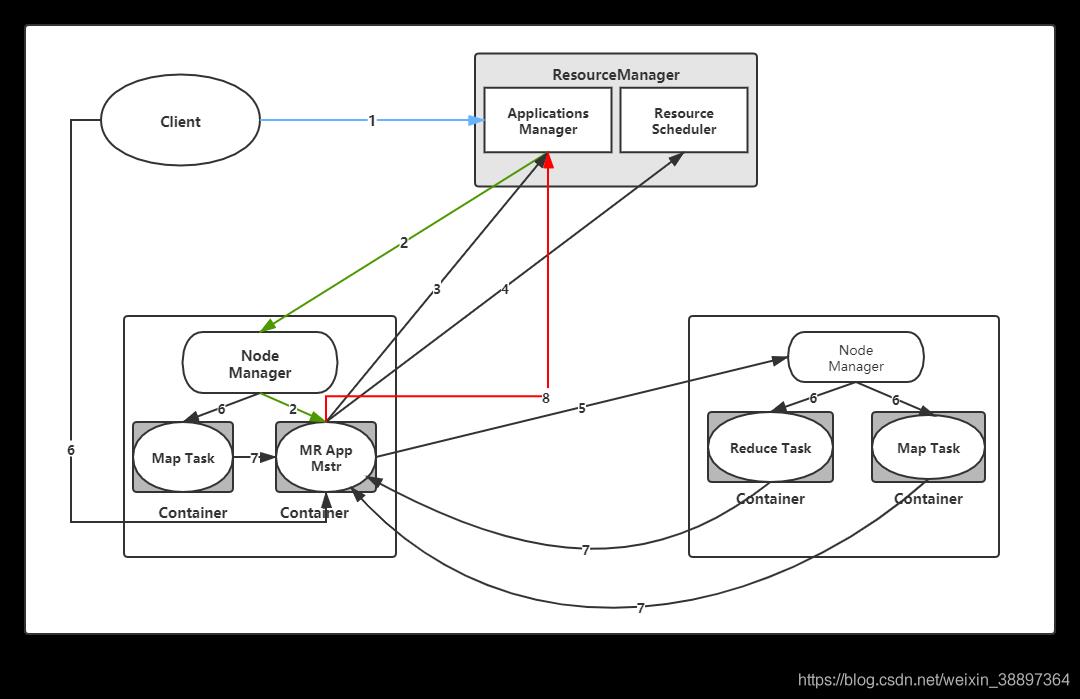
步骤:
- 1.用 户 向 YARN 中 提 交 应 用 程 序, 其 中 包 括 MRAppMaster 程 序、 启 动 MRAppMaster 的命令、用户程序等。(MRAppMstr 程序在客户端生成,这一步已经将应用程序先行程序提交到RM的Application Manager模块进行处理,但此时运行程序所需的jar包、环境变量、切片信息等提交到HDFS之上,需要等MRAPPMstr返回一个可用的Container的时候在节点提交执行。可以理解为惰性处理,减少资源占用,做到需要什么提交什么)
- 2.ResourceManager 为该应用程序分配第一个 Container,并与对应的 Node-Manager 通信,要求它在这个 Container 中启动应用程序的MRAppMaster。(APPMaster就是先头兵,这时的操作是RM的ApplicationManager来进行处理)
- 3.MRAppMaster 首先向 ResourceManager 注册, 这样用户可以直接通过ResourceManage 查看应用程序的运行状态,然后它将为各个任务申请资源,并监控它的运行状态,直到整个应用运行结束。
- 4.MRAppMaster 采用轮询的方式通过 RPC 协议向 ResourceManager 申请和 领取资源。
- 5.一旦 MRAppMaster 申请到资源后,便与对应的 NodeManager 通信,要求 它启动任务。(理解集群中不同节点的资源动态变动,可用Container以及不同的Task可以在不同的节点运行)
- 6.NodeManager 为任务设置好运行环境(包括环境变量、JAR 包、二进制程序 等)后,将任务启动命令写到一个脚本中,并通过运行该脚本启动任务。(此时,客户端才真正上传具体Task需要的Jar包等等运行资源,同时NodeManager通过调用资源运行对应的Task任务);
- 7.各个任务通过某个 RPC 协议向 MRAppMaster 汇报自己的状态和进度,以 让 MRApplicationMaster 随时掌握各个任务的运行状态,从而可以在任务失败时重新启动任务。 在应用程序运行过程中,用户可随时通过 RPC 向 MRAppMaster 查询应用程序的当 前运行状态。
- 步骤4~7是重复执行的
- 8.应用程序运行完成后,MRAppMaster 向 ResourceManager 注销并关闭自己。
可将 YARN 看做一个云操作系统,它负责为应用程序启 动 ApplicationMaster(相当于主线程),然后再由 ApplicationMaster 负责数据切分、任务分配、 启动和监控等工作,而由 ApplicationMaster 启动的各个 Task(相当于子线程)仅负责自己的计 算任务。当所有任务计算完成后,ApplicationMaster 认为应用程序运行完成,然后退出。
实例运行
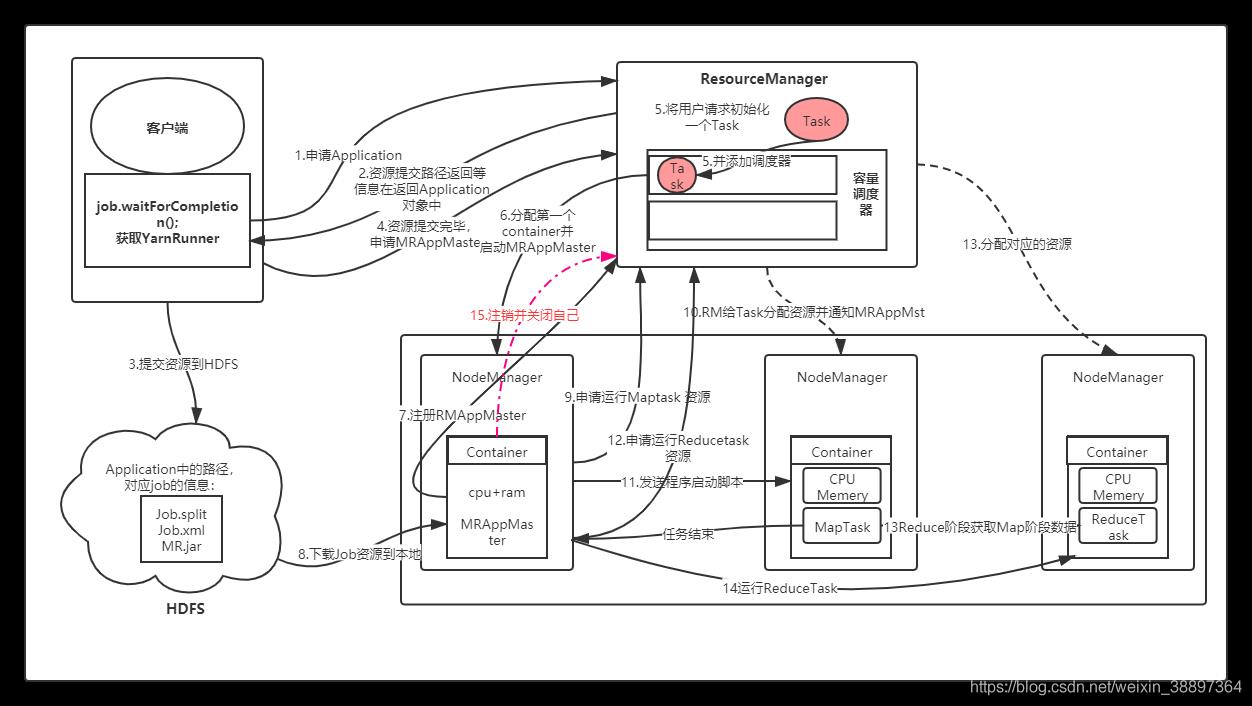
- step1.客户端程序提交任务到自身所在的节点;
- step2:客户端获取一个YARNRunner向ResourceManager(以下简称RM)申请一个Application
- step3:RM将该应用程序的资源路径返回给YARNRunner;
- step4:客户端程序将运行所需的资源提交到YARN上,提交的内容包括:MRAppMaster程序(MRAppMaster运行程序)、MRAppMaster启动脚本程序、用户程序(真正的MapReduce处理程序)等。RM内部分别管理ApplicationManager和ResourceManager管理对象,分别负责和MRAppMaster交互与Resource资源的管理。
- step5:资源提交完毕,并将应用程序作为一个Task放置在调度器中。RM为提交的程序选择一个空闲的NodeManager(以下简称NM)分配第一个Container,并与对应的NM通信,要求NM在当前容器中运行MRAppMaster。(MRAppMaster负责这个程序的运行状态及进度监控调度等等)。
- step6:MRAppMaster启动之后先向RM注册自己。
- step7:然后通过轮询方式通过RPC协议向RM为自己内部的任务申请资源和领取资源,通过HDFS复制一份Job需要的相关信息,并依据信息向RM申请运行任务的资源。
- step8:MRAppMaster向RM申请MapTask需要的资源,RM分配对应的NM信息给MRAppMaster,MRAppMaster与对应的NM通信,将对应的程序脚本发送给NM。(NM会为任务设置好对应的运行环境,包括环境变量、JAR包、二进制程序等)。NM接受此脚本并开始启动对应的任务。开启对应的MapTask任务,MapTask会对数据进行分区排序。
- step9:MRAppMaster在所有MapTask任务结束,MRAppMaster向RM申请资源并运行ReduceTask,ReduceTask会从Maptask 获取运行数据,执行ReduceTask。
- step10 程序运行结束,MRAppmaster向RM注销并关闭自己。
7.多角度理解YARN
7.1并行计算
将 YARN 看做一个云操作系统,它负责为应用程序启 动 ApplicationMaster(相当于主线程),然后再由 ApplicationMaster 负责数据切分、任务分配、 启动和监控等工作,而由 ApplicationMaster 启动的各个 Task(相当于子线程)仅负责自己的计 算任务。当所有任务计算完成后,ApplicationMaster 认为应用程序运行完成,然后退出。
7.2资源管理系统
资源管理系统的主要功能是对集群中各类资源进行抽象,并根据各种应用程序或者服 务的要求,按照一定的调度策略,将资源分配给它们使用,同时需采用一定的资源隔离机制防止应用程序或者服务之间因资源抢占而相互干扰。YARN 正是一个资源管理系统,它的出现弱化了计算框架之争,引入 YARN 这一层后,各种计算框架可各自发挥自己的优势, 并由 YARN 进行统一管理,进而运行在一个大集群上。
7.3云计算
云计算包括以下几个层次的服务 :IaaS、PaaS 和 SaaS。
IaaS(Infrastructure-as-a-Service) :基础设施即服务。消费者通过 Internet 可以从完善的计算机基础设施获得服务。Iaas 通过网络向用户提供计算机(物理机和虚拟机)、存储空间、 网络连接、负载均衡和防火墙等基本计算资源 ;用户在此基础上部署和运行各种软件,包括操作系统和应用程序等。如阿里云、华为云等云平台。
PaaS(Platform-as-a-Service) :平台即服务。PaaS 是将软件研发的平台作为一种服务, 以 SaaS 的模式提交给用户。平台通常包括操作系统、编程语言的运行环境、数据库和 Web 服务器等,用户可以在平台上部署和运行自己的应用。通常而言,用户不能管理和控制底 层的基础设施,只能控制自己部署的应用。
SaaS(Software-as-a-Service):软件即服务。它是一种通过 Internet 提供软件的模式,用 户无需购买软件,而是向提供商租用基于 Web 的软件,来管理企业经营活动。云提供商在 云端安装和运行应用软件,云用户通过云客户端(比如 Web 浏览器)使用软件。
从云计算分层概念上讲,YARN 可看做 PAAS 层,它能够为不同类型的应用程序提供 统一的管理和调度。
总结
YARN 的设计理念和基本架构,包括 YARN 产生背 景、Hadoop 术语解释和版本变迁、YARN 架构和通信协议等。
从编程模型角度看,YARN 与传统并行编程模式非常像,但兼具了分布式和并行两个特点 ;从资源管理系统角度看, YARN 将扮演为上层计算框架提供计算资源的角色 ;从云计算角度看,YARN 可看做轻量 级的 PAAS 层。
以上是关于YARN基础+Yarn组件+Yarn架构和工作流程+Yarn三种调度器+MR流程+zookeeper的主要内容,如果未能解决你的问题,请参考以下文章
Hadoop Yarn 一文搞懂 Yarn架构原理和工作机制