Flink Sort-Shuffle 实现简介
Posted 阿里云云栖号
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Flink Sort-Shuffle 实现简介相关的知识,希望对你有一定的参考价值。
简介:Sort-Shuffle 使 Flink 在应对大规模批数据处理任务时更加游刃有余
本文介绍 Sort-Shuffle 如何帮助 Flink 在应对大规模批数据处理任务时更加游刃有余。主要内容包括:
- 数据 Shuffle 简介
- 引入 Sort-Shuffle 的意义
- Flink Sort-Shuffle 实现
- 测试结果
- 调优参数
- 未来展望
Flink 作为批流一体的大数据计算引擎,大规模批数据处理也是 Flink 数据处理能力的重要组成部分。随着 Flink 的版本迭代,其批数据处理能力也在不断增强,sort-shuffle 的引入,使得 Flink 在应对大规模批数据处理任务时更加游刃有余。
一、数据 Shuffle 简介
数据 shuffle 是批数据处理作业的一个重要阶段,在这一阶段中,上游处理节点的输出数据会被持久化到外部存储中,之后下游的计算节点会读取这些数据并进行处理。这些持久化的数据不仅仅是一种计算节点间的数据交换形式,还在错误恢复中发挥着重要作用。
目前,有两种批数据 shuffle 模型被现有的大规模分布式计算系统采用,分别是基于 hash 的方式以及基于 sort 的方式:
- 基于 hash 方式的核心思路是将发送给下游不同并发消费任务的数据写到单独的文件中,这样文件本身就成了一个自然的区分不同数据分区的边界;
- 基于 sort 方式的核心思路是先将所有分区的数据写在一起,然后通过 sort 来区分不同数据分区的边界。
我们在 Flink 1.12 版本将基于 sort 的批处理 shuffle 实现引入了 Flink 并在后续进行了持续的性能与稳定性优化;到 Flink 1.13 版本,sort-shuffle 已经实现生产可用。
二、引入 Sort-Shuffle 的意义
我们之所以要在 Flink 中引入 sort-shuffle 的实现,一个重要的原因是 Flink 原本的基于 hash 的实现对大规模批作业不可用。这个也是被现有的其他大规模分布式计算系统所证明的:
- 稳定性方面:对于高并发批作业,基于 hash 的实现会产生大量的文件,并且会对这些文件进行并发读写,这会消耗很多资源并对文件系统会产生较大的压力。文件系统需要维护大量的文件元数据,会产生文件句柄以及 inode 耗尽等不稳定风险。
- 性能方面:对于高并发批作业,并发读写大量的文件意味着大量的随机 IO,并且每次 IO 实际读写的数据量可能是非常少的,这对于 IO 性能是一个巨大的挑战,在机械硬盘上,这使得数据 shuffle 很容易成为批处理作业的性能瓶颈。
通过引入基于 sort 的批数据 shuffle 实现,并发读写的文件数量可以大大降低,有利于实现更好的数据顺序读写,从而能够提高 Flink 大规模批处理作业的稳定性与性能。除此之外,新的 sort-shuffle 实现还可以减小内存缓冲区的消耗。对于基于 hash 的实现,每个数据分区都需要一块读写缓冲区,内存缓冲区消耗和并发成正比。而基于 sort 的实现则可以做到内存缓冲区消耗和作业并发解耦(尽管更大的内存可能会带来更高的性能)。
更为重要的一点是我们实现了新的存储结构与读写 IO 优化,这使得 Flink 的批数据 shuffle 相比于其他的大规模分布式数据处理系统更具优势。下面的章节会更为详细的介绍 Flink 的 sort-shuffle 实现以及所取得的结果。
三、Flink Sort-Shuffle 实现
和其他分布式系统的批数据 sort-shuffle 实现类似,Flink 的整个 shuffle 过程分为几个重要的阶段,包括写数据到内存缓冲区、对内存缓冲区进行排序、将排好序的数据写出到文件以及从文件中读取 shuffle 数据并发送给下游。但是,与其他系统相比,Flink 的实现有一些根本性的不同,包括多段数据存储格式、省掉数据合并流程以及数据读取 IO 调度等。这些都使得 Flink 的实现有着更优秀的表现。
1. 设计目标
在 Flink sort-shuffle 的整个实现过程中,我们把下面这些点作为主要的设计目标加以考量:
1.1 减少文件数量
正如上面所讨论的,基于 hash 的实现会产生大量的文件,而减少文件的数量有利于提高稳定性和性能。Sort-Spill-Merge 的方式被分布式计算系统广泛采纳以达到这一目标,首先将数据写入内存缓冲区,当内存缓冲区填满后对数据进行排序,排序后的数据被写出到一个文件中,这样总的文件数量是:(总数据量 / 内存缓冲区大小),从而文件数量被减少。当所有数据写出完成后,将产生的文件合并成一个文件,从而进一步减少文件数量并增大每个数据分区的大小(有利于顺序读取)。
相比于其他系统的实现,Flink 的实现有一个重要的不同,即 Flink 始终向同一个文件中不断追加数据,而不会写多个文件再进行合并,这样的好处始终只有一个文件,文件数量实现了最小化。
1.2 打开更少的文件
同时打开的文件过多会消耗更多的资源,同时容易导致文件句柄不够用的问题,导致稳定性变差。因此,打开更少的文件有利于提升系统的稳定性。对于数据写出,如上所述,通过始终向同一个文件中追加数据,每个并发任务始终只打开一个文件。对于数据读取,虽然每个文件都需要被大量下游的并发任务读取,Flink 依然通过只打开文件一次,并在这些并发读取任务间共享文件句柄实现了每个文件只打开一次的目标。
1.3 最大化顺序读写
文件的顺序读写对文件的 IO 性能至关重要。通过减少 shuffle 文件数量,我们已经在一定程度上减少了随机文件 IO。除此之外,Flink 的批数据 sort-shuffle 还实现了更多 IO 优化来最大化文件的顺序读写。在数据写阶段,通过将要写出的数据缓冲区聚合成更大的批并通过 wtitev 系统调用写出从而实现了更好的顺序写。在数据读取阶段,通过引入读取 IO 调度,总是按照文件的偏移顺序服务数据读取请求从而最大限度的实现的文件的顺序读。实验表明这些优化极大的提升了批数据 shuffle 的性能。
1.4 减少读写 IO 放大
传统的 sort-spill-merge 方式通过将生成的多个文件合并成一个更大的文件从增大读取数据块的大小。这种实现方案虽然带来了好处,但也有一些不足,最终要的一点便是读写 IO 放大,对于计算节点间的数据 shuffle 而言,在不发生错误的情况下,本身只需要写入和读取数据一次,但是数据合并使得相同的数据被读写多次,从而导致 IO 总量变多,并且存储空间的消耗也会变大。
Flink 的实现通过不断向同一个文件中追加数据以及独特的存储结构规避了文件和并的过程,虽然单个数据块的大小小于和并后的大小,但由于规避了文件合并的开销再结合 Flink 独有的 IO 调度,最终可以实现比 sort-spill-merge 方案更高的性能。
1.5 减少内存缓冲区消耗
类似于其他分布式计算系统中 sort-shuffle 的实现,Flink 利用一块固定大小的内存缓冲区进行数据的缓存与排序。这块内存缓冲区的大小是与并发无关的,从而使得上游 shuffle 数据写所需要的内存缓冲区大小与并发解耦。结合另一个内存管理方面的优化 FLINK-16428 可以同时实现下游 shuffle 数据读取的内存缓冲区消耗并发无关化,从而可以减少大规模批作业的内存缓冲区消耗。(注:FLINK-16428 同时适用于批作业与流作业)
2. 实现细节
2.1 内存数据排序
在 shuffle 数据的 sort-spill 阶段,每条数据被首先序列化并写入到排序缓冲区中,当缓冲区被填满后,会对缓冲区中的所有二进制数据按照数据分区的顺序进行排序。此后,排好序的数据会按照数据分区的顺序被写出到文件中。虽然,目前并没有对数据本身进行排序,但是排序缓冲区的接口足够的泛化,可以实现后续潜在的更为复杂的排序要求。排序缓冲区的接口定义如下:
public interface SortBuffer
*/** Appends data of the specified channel to this SortBuffer. \\*/*
boolean append(ByteBuffer source, int targetChannel, Buffer.DataType dataType) throws IOException;
*/** Copies data in this SortBuffer to the target MemorySegment. \\*/*
BufferWithChannel copyIntoSegment(MemorySegment target);
long numRecords();
long numBytes();
boolean hasRemaining();
void finish();
boolean isFinished();
void release();
boolean isReleased();
在排序算法上,我们选择了复杂度较低的 bucket-sort。具体而言,每条序列化后的数据前面都会被插入一个 16 字节的元数据。包括 4 字节的长度、4 字节的数据类型以及 8 字节的指向同一数据分区中下一条数据的指针。结构如下图所示:

当从缓冲区中读取数据时,只需要按照每个数据分区的链式索引结构就可以读取到属于这个数据分区的所有数据,并且这些数据保持了数据写入时的顺序。这样按照数据分区的顺序读取所有的数据就可以达到按照数据分区排序的目标。
2.2 文件存储结构
如前所述,每个并行任务产生的 shuffle 数据会被写到一个物理文件中。每个物理文件包含多个数据区块(data region),每个数据区块由数据缓冲区的一次 sort-spill 生成。在每个数据区块中,所有属于不同数据分区(data partition,由下游计算节点不同并行任务消费)的数据按照数据分区的序号顺序进行排序聚合。下图展示了 shuffle 数据文件的详细结构。其中(R1,R2,R3)是 3 个不同的数据区块,分别对应 3 次数据的 sort-spill 写出。每个数据块中有 3 个不同的数据分区,分别将由(C1,C2,C3)3 个不同的并行消费任务进行读取。也就是说数据 B1.1,B2.1 及 B3.1 将由 C1 处理,数据 B1.2,B2.2 及 B3.2 将由 C2 处理,而数据 B1.3,B2.3 及 B3.3 将由 C3 处理。
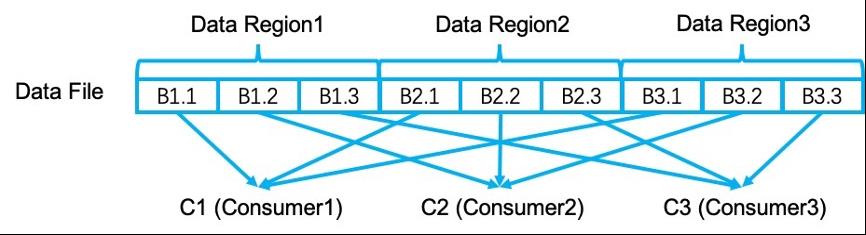
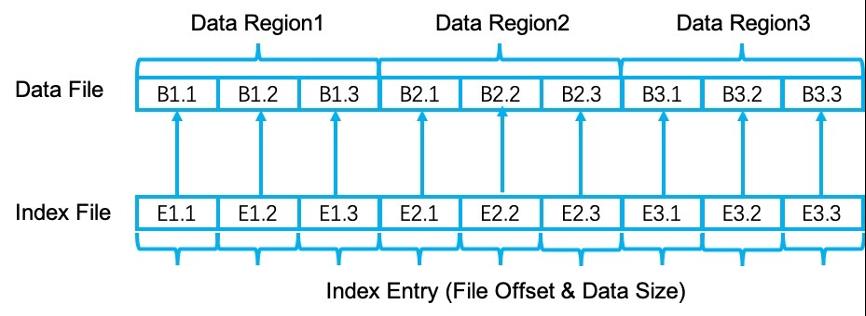
类似于其他的分布式处理系统实现,在 Flink 中,每个数据文件还对应一个索引文件。索引文件用来在读取时为每个消费者索引属于它的数据(data partition)。索引文件包含和数据文件相同的 data region,在每个 data region 中有与 data partition 相同数量的索引项,每个索引项包含两个部分,分别对应到数据文件的偏移量以及数据的长度。作为一个优化。Flink 为每个索引文件缓存最多 4M 的索引数据。数据文件与索引文件的对应关系如下:
2.3 读取 IO 调度
为了进一步提高文件 IO 性能,基于上面的存储结构,Flink 进一步引入了 IO 调度机制,类似于磁盘调度的电梯算法,Flink 的 IO 调度总是按照 IO 请求的文件偏移顺序进行调度。更具体来说,如果数据文件有 n 个 data region,每个 data region 有 m 个 data partition,同时有 m 个下游计算任务读取这一数据文件,那么下面的伪代码展示了 Flink 的 IO 调度算法的工作流程:
*// let data_regions as the data region list indexed from 0 to n - 1*
*// let data_readers as the concurrent downstream data readers queue indexed from 0 to m - 1*
for (data_region in data_regions)
data_reader = poll_reader_of_the_smallest_file_offset(data_readers);
if (data_reader == null)
break;
reading_buffers = request_reading_buffers();
if (reading_buffers.isEmpty())
break;
read_data(data_region, data_reader, reading_buffers);
2.4 数据广播优化
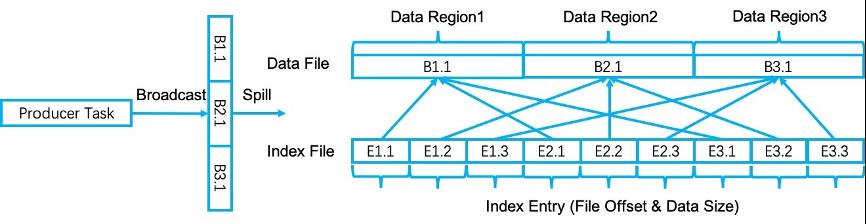
数据广播是指发送相同的数据给下游计算节点的所有并行任务,一个常见的应用场景是 broadcast-join。Flink 的 sort-shuffle 实现对这一过程进行了优化,使得在包括内存排序缓冲区和 shuffle 文件中,广播数据只保存一份,这可以大大提升数据广播的性能。更具体来说,当写入一条广播数据到排序缓冲区时,这条数据只会被序列化并且拷贝一次,同样在将数据写出到 shuffle 文件时,也只会写一份数据。在索引文件中,对于不同 data partition 的数据索引项,他们均指向数据文件中的同一块数据。下图展示了数据广播优化的所有细节:
2.5 数据压缩
数据压缩是一个简单而有效的优化手段,测试结果显示数据压缩可以提高 TPC-DS 总体性能超过 30%。类似于 Flink 的基于 hash 的批处理 shuffle 实现,数据压缩是以网络缓冲区(network buffer)为单位进行的,数据压缩不跨 data partition,也就是说发给不同下游并行任务的数据分开压缩,压缩发生在数据排序后写出前,下游消费任务在收到数据后进行解压。下图展示了数据压缩的整个流程:

四、测试结果
1. 稳定性
新的 sort-shuffle 的实现极大的提高 Flink 运行批处理作业的稳定性。除了解决了潜在的文件句柄以及 inode 耗尽的不稳定问题外,还解决了一些 Flink 原有 hash-shuffle 存在的已知问题,如 FLINK-21201(创建过多文件导致主线程阻塞),FLINK-19925(在网络 netty 线程中执行 IO 操作导致网络稳定性受到影响)等。
2. 性能
我们在 1000 规模的并发下运行了 TPC-DS 10T 数据规模的测试,结果表明,相比于 Flink 原本的批数据 shuffle 实现,新的数据 shuffle 实现可以实现 2-6 倍的性能提升,如果排除计算时间,只统计数据 shuffle 时间可以是先最高 10 倍的性能提升。下表展示了性能提升的详细数据:
| Jobs | Time Used for Sort-Shuffle (s) | Time Used for Hash-Shuffle (s) | Speed up Factor |
|---|---|---|---|
| q4.sql | 986 | 5371 | 5.45 |
| q11.sql | 348 | 798 | 2.29 |
| q14b.sql | 883 | 2129 | 2.51 |
| q17.sql | 269 | 781 | 2.90 |
| q23a.sql | 418 | 1199 | 2.87 |
| q23b.sql | 376 | 843 | 2.24 |
| q25.sql | 413 | 873 | 2.11 |
| q29.sql | 354 | 1038 | 2.93 |
| q31.sql | 223 | 498 | 2.23 |
| q50.sql | 215 | 550 | 2.56 |
| q64.sql | 217 | 442 | 2.04 |
| q74.sql | 270 | 962 | 3.56 |
| q75.sql | 166 | 713 | 4.30 |
| q93.sql | 204 | 540 | 2.65 |
在我们的测试集群上,每块机械硬盘的数据读取以及写入带宽可以达到 160MB/s:
| Disk Name | SDI | SDJ | SDK |
|---|---|---|---|
| Writing Speed (MB/s) | 189 | 173 | 186 |
| Reading Speed (MB/s) | 112 | 154 | 158 |
注:我们的测试环境配置如下,由于我们有较大的内存,所以一些 shuffle 数据量小的作业实际数据 shuffle 仅为读写内存,因此上面的表格仅列出了一些 shuffle 数据量大,性能提升明显的查询:
| Number of Nodes | Memory Size Per Node | Cores Per Node | Disks Per Node |
|---|---|---|---|
| 12 | About 400G | 96 | 3 |
五、调优参数
在 Flink 中,sort-shuffle 默认是不开启的,想要开启需要调小这个参数的配置:taskmanager.network.sort-shuffle.min-parallelism。这个参数的含义是如果数据分区的个数(一个计算任务并发需要发送数据给几个下游计算节点)低于这个值,则走 hash-shuffle 的实现,如果高于这个值则启用 sort-shuffle。实际应用时,在机械硬盘上,可以配置为 1,即使用 sort-shuffle。
Flink 没有默认开启数据压缩,对于批处理作业,大部分场景下是建议开启的,除非数据压缩率低。开启的参数为 taskmanager.network.blocking-shuffle.compression.enabled。
对于 shuffle 数据写和数据读,都需要占用内存缓冲区。其中,数据写缓冲区的大小由 taskmanager.network.sort-shuffle.min-buffers 控制,数据读缓冲区由 taskmanager.memory.framework.off-heap.batch-shuffle.size 控制。数据写缓冲区从网络内存中切分出来,如果要增大数据写缓冲区可能还需要增大网络内存总大小,以避免出现网络内存不足的错误。数据读缓冲区从框架的 off-heap 内存中切分出来,如果要增大数据读缓冲区,可能还需要增大框架的 off-heap 内存,以避免出现 direct 内存 OOM 错误。一般而言更大的内存缓冲区可以带来更好的性能,对于大规模批作业,几百兆的数据写缓冲区与读缓冲区是足够的。
六、未来展望
还有一些后续的优化工作,包括但不限于:
1)网络连接复用,这可以提高网络的建立的性能与稳定性,相关 Jira 包括 FLINK-22643 以及 FLINK-15455;
2)多磁盘负载均衡,这有利于解决负载不均的问题,相关 Jira 包括 FLINK-21790 以及 FLINK-21789;
3)实现远程数据 shuffle 服务,这有利于进一步提升批数据 shuffle 的性能与稳定性;
4)允许用户选择磁盘类型,这可以提高易用性,用户可以根据作业的优先级选择使用 HDD 或者 SSD。
本文为阿里云原创内容,未经允许不得转载。
以上是关于Flink Sort-Shuffle 实现简介的主要内容,如果未能解决你的问题,请参考以下文章