Flink分区策略
Posted 月疯
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Flink分区策略相关的知识,希望对你有一定的参考价值。
分区策略决定了一条数据如何发给下游,Flink中提供八大分区策略。
1、BroadcastPartitioner广播分区会将上游数据输出到下游算子的每个实例(),适合于大数据和小数据集做JOIN场景。
2、CustomPartitionerWrapper自定义分区需要用户根据自己实现Partitioner接口,来定义自己的分区逻辑。
3、ForwarPartitioner用户将记录输出到下游本地的算子实例。它要求上下游算子并行度一样。简单的说,ForwarPartitioner可以来做控制台打印。
4、GlobaPartitioner数据会被分发到下游算子的第一个实例中进行处理
5、KeyGroupStreamPartitioner Hash分区器,会将数据按照key的Hash值输出到下游的实例中
6、RebalancePartitioner数据会被循环发送到下游的每一个实例额的Task中进行处理。
7、RescalePartitioner这种分区器会根据上下游算子的并行度,循环的方式输出到下游算子的每个实例。这里有点难理解,家核上游并行度为2,编号为A和B。下游并行度为4,编号为1,2,3,4.那么A则把数据循环发送给1,和2,B则把数据循环发送给3和4.
8、ShufflePartitioner数据会被随即分发到下游算子的每一个实例中进行处理。
RescalePartitioners注释:
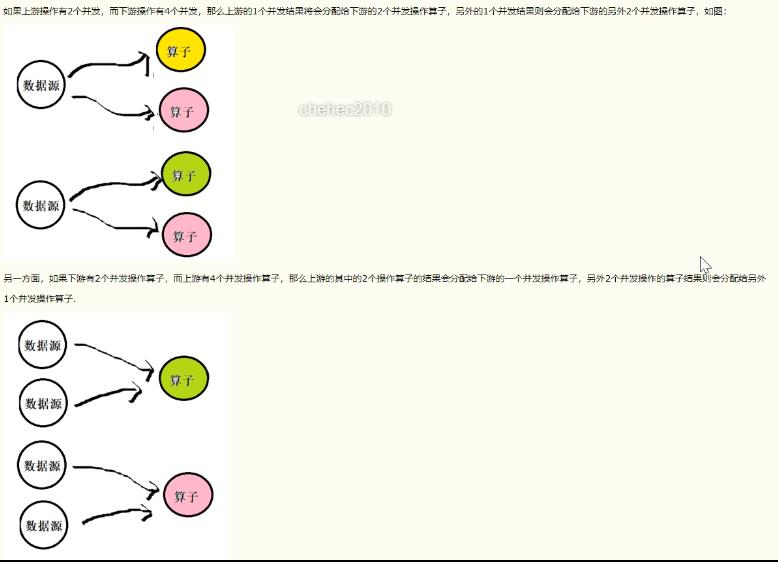
ChannelSelector: 接口,决定将记录写入哪个Channel。有3个方法:
void setup(int numberOfChannels): 初始化输出Channel的数量。
int selectChannel(T record): 根据当前记录以及Channel总数,决定应将记录写入下游哪个Channel。八大分区策略的区别主要在这个方法的实现上。
boolean isBroadcast(): 是否是广播模式。决定了是否将记录写入下游所有Channel。
StreamPartitioner:抽象类,也是所有流分区器GlobalPartitioner,ShufflePartitioner,RebalancePartitioner,RescalePartitioner,BroadcastPartitioner,ForwardPartitioner,KeyGroupStreamPartitioner,CustomPartitioner的基类。注意:Operator就是算子的意思
这里以及下边提到的Channel可简单理解为下游Operator的某个实例。
Flink 中改变并行度,默认RebalancePartitioner分区策略。
代码demo:
package Flink_API;
import org.apache.flink.api.common.functions.Partitioner;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.streaming.api.TimeCharacteristic;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.ProcessFunction;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer010;
import org.apache.flink.streaming.util.serialization.KeyedDeserializationSchema;
import org.apache.flink.util.Collector;
import java.io.Serializable;
import java.util.Properties;
public class TestPartitiner
public static void main(String[] args) throws Exception
//创建运行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//Flink是以数据自带的时间戳字段为准
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
//设置并行度
env.setParallelism(1);
Properties consumerProperties = new Properties();
consumerProperties.setProperty("bootstrap.severs", "page01:9001");
consumerProperties.setProperty("grop.id", "browsegroup");
DataStreamSource<String> dataStreamSource = env.addSource(new FlinkKafkaConsumer010<String>("browse_topic", (KeyedDeserializationSchema<String>) new SimpleStringSchema(), consumerProperties));
DataStream<UserBrowseLog> processData = dataStreamSource.process(new ProcessFunction<String, UserBrowseLog>()
@Override
public void processElement(String s, Context context, Collector<UserBrowseLog> collector) throws Exception
try
UserBrowseLog browseLog = com.alibaba.fastjson.JSON.parseObject(s, UserBrowseLog.class);
if (browseLog != null)
collector.collect(browseLog);
catch (Exception e)
System.out.print("解析Json——UserBrowseLog异常:" + e.getMessage());
).setParallelism(2).name("processData");
//上游2个算子,下游10个算子
// //1、采用Global分区策略重分区
// processData.global().print().setParallelism(10).name("print");
// //2、采用SHUFFLE分区策略重分区(随机的)
// processData.shuffle().print().setParallelism(10).name("print");
// //3、采用rebalance分区策略重分区(默认的轮训分区器)
// processData.rebalance().print().setParallelism(10).name("print");
// //4、采用rescale分区策略重分区(默认的轮训分区器)
// processData.rescale().print().setParallelism(10).name("print");
// //5、采用broadcast分区策略重分区(默认的轮训分区器)
// processData.broadcast().print().setParallelism(10).name("print");
// //6、forward
// processData.forward().print().setParallelism(10).name("print");
// //7、hash
// processData.keyBy("userID").print().setParallelism(10).name("print");
//8、custom
processData.partitionCustom(new CustomPartitioner(),"userID").print().setParallelism(10).name("print");
//打印结果
processData.print();
//程序的入口类
env.execute("TestPartitiner");
public static class CustomPartitioner implements Partitioner<String>
@Override
public int partition(String s, int i)
System.out.print(i);
if(s.equals("user_1"))
return 0;
else
return 1;
//浏览类
public static class UserBrowseLog implements Serializable
private String userID;
private String eventTime;
private String eventType;
private String productID;
private Integer productPrice;
public String getUserID()
return userID;
public void setUserID(String userID)
this.userID = userID;
public String getEventTime()
return eventTime;
public void setEventTime(String eventTime)
this.eventTime = eventTime;
public String getEventType()
return eventType;
public void setEventType(String eventType)
this.eventType = eventType;
public String getProductID()
return productID;
public void setProductID(String productID)
this.productID = productID;
public Integer getProductPrice()
return productPrice;
public void setProductPrice(Integer productPrice)
this.productPrice = productPrice;
@Override
public String toString()
return "UserBrowseLog" +
"userID='" + userID + '\\'' +
", eventTime='" + eventTime + '\\'' +
", eventType='" + eventType + '\\'' +
", productID='" + productID + '\\'' +
", productPrice=" + productPrice +
'';
以上是关于Flink分区策略的主要内容,如果未能解决你的问题,请参考以下文章