强化学习笔记 DDPG (Deep Deterministic Policy Gradient)
Posted UQI-LIUWJ
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了强化学习笔记 DDPG (Deep Deterministic Policy Gradient)相关的知识,希望对你有一定的参考价值。
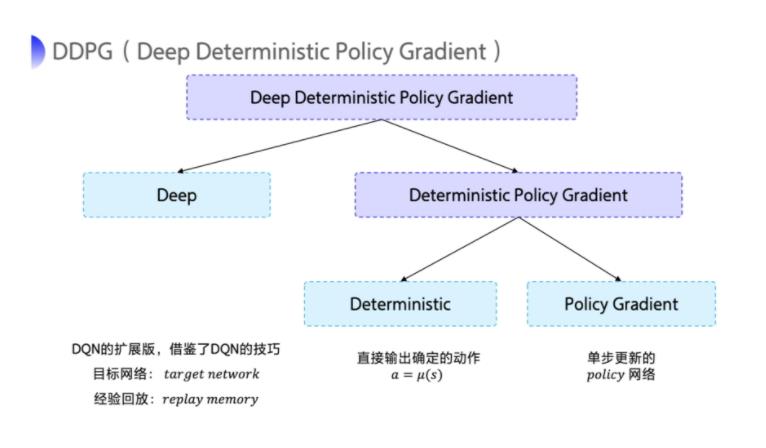
1 总述
总体来讲,和actor-critic 差不多,只不过这里用了target network 和experience relay
强化学习笔记 experience replay 经验回放_UQI-LIUWJ的博客-CSDN博客
强化学习笔记:Actor-critic_UQI-LIUWJ的博客-CSDN博客
DQN 笔记 State-action Value Function(Q-function)_UQI-LIUWJ的博客-CSDN博客
2 模型介绍
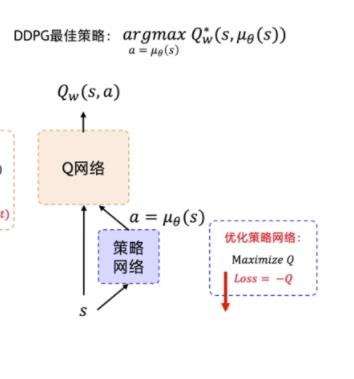
2.1 整体架构
看模型架构和actor-critic 类似,也是训练一个actor 网络(策略网络)以及一个critic网络(DQN)
2.2 目标网络+经验回放
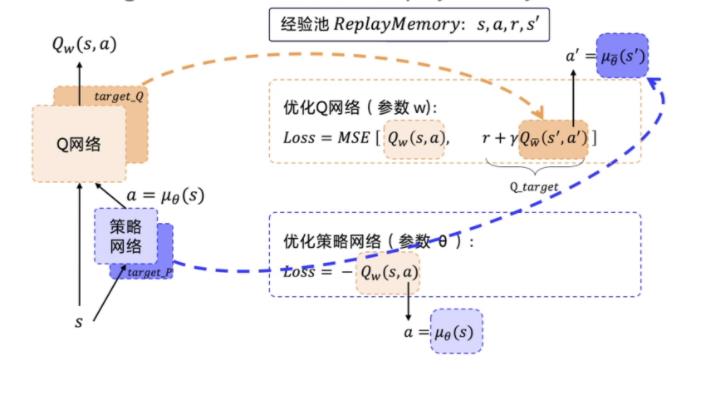
在第十二章 深度确定性策略梯度 (DDPG) 算法 (datawhalechina.github.io) 里面的说法是,actor和critic网络各有一个target network,但由于actor网络是一个policy gradient,所以个人觉得,只给actor网络目标网络就行了?
因为 DDPG 使用了经验回放这个技巧,所以 DDPG 是一个 off-policy 的算法。
以上是关于强化学习笔记 DDPG (Deep Deterministic Policy Gradient)的主要内容,如果未能解决你的问题,请参考以下文章
强化学习笔记 Ornstein-Uhlenbeck 噪声和DDPG