Pravega Flink Connector Table API 进阶功能探秘
Posted 过往记忆
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Pravega Flink Connector Table API 进阶功能探秘相关的知识,希望对你有一定的参考价值。
▼ 关注「Apache Flink」,获取更多技术干货 ▼
摘要:本文整理自戴尔科技集团软件工程师周煜敏在 Flink Forward Asia 2021 分享的议题《Pravega Flink Connector Table API 进阶功能探秘》,文章内容为:
Pravega Schema Registry 项目介绍
Catalog API 集成
Debezium 支持
社区联合白皮书发布
Tips:点击「阅读原文」获取 FFA 2021 峰会资料~
在 Flink Forward Asia 2020 上,我们团队分享了议题《Pravega Flink Connector 的过去、现在和未来》,介绍了 Pravega Flink Connector FLIP-95 Table API 从零到一的一个过程,使得 Pravega stream 能够与 Flink table API 建立链接并相互转化,用户可以使用简单的 SQL 语句对 Pravega stream 中的数据进行查询和写入。一年多过去了,我们也在推动流表一体化的基础上做了一些进阶的功能,进一步丰富了使用场景,简化了使用难度。接下来,本篇文章就以 Catalog API 集成以及 Debezium 支持这两个新功能为例,带大家对这些进阶功能的技术细节进行深入探秘。
一、Pravega Schema Registry
项目介绍
Pravega Schema Registry ,这也是 Pravega 生态社区在 2020 年推出的一个新功能,类似 Confluent Schema Registry 和 AWS Glue,是一个利用 Pravega 来存储和管理数据 schema 结构的通用的解决方案。依托 Pravega Schema Registry 功能,在connector 中就可以实现 Catalog API, 实现 Pravega catalog 的功能。使得用户无需重写 CREATE TABLE 的建表 DDL 建立与 Pravega stream 的连接就能使用 Flink 直接以 SQL 访问数据。
1. 项目动机
Pravega stream 中存储的是序列化后的原始二进制数据,这就需要读端和写端双方对写入的数据的 schema 有一个共识。这一点在数据和开发规模较小的时候还容易解决,但是当负载的规模随着业务增长不断扩大的时候,面对成千上百的 stream 的读写,多个开发部门互相协作的情况,就比较困难了。这就需要 Pravega Schema Registry 的组件来完成 schema 一致性的保证。
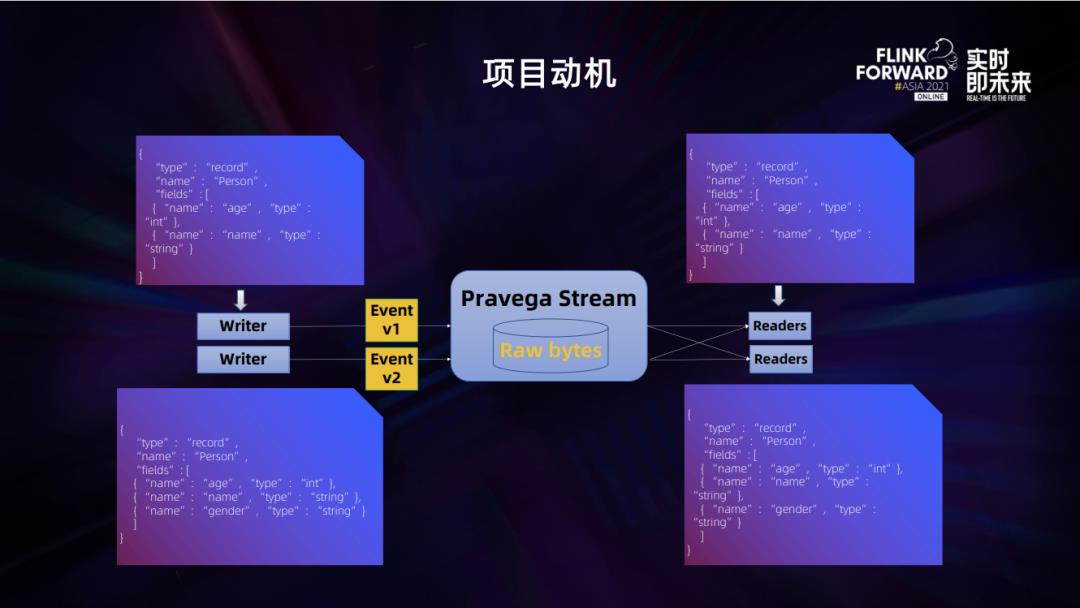
如上图所示,当 writer 写入了 event 的时候,reader 要以相同的 schema 去反序列化这样一个 event ,才能从二进制中拿到准确的数据。有些敏感的信息可能甚至会在元数据的基础上进一步进行加密编码的保护。
我们就需要去针对 Pravega 的 stream 有一个中心化的 schema 元数据,包括编码格式的存储,能够让 writer 进行写入和定义,然后所有的 reader 可以对其进行读取,获取到数据的结构和反序列方法,达成 schema 的共识。
我们也希望这种元数据的存储可以不依赖一个额外的组件,最好能够利用 Pravega 本身,不但节约了运维的代价,还能够利用到 Pravega 本身的高效的,持久化的存储特性。
更进一步,一个很常见的业务场景是 schema 的变更。在同一个 stream 当中,随着业务的拓展,写入的半结构数据可能会引入新增的或者改变一些字段来支持更多的业务流程和作业。这在许多的格式标准,例如 Avro 中也有相应的兼容性配置。具体来看,当另一个 writer 写入了新 schema 的数据,我们不仅需要保证原有线上的 reader 能够继续工作,对新增的需要利用到新字段的 reader 也能够支持数据的读取。因此,Pravega Schema Registry 的存在最好能够保证无需等到读取端真正去尝试反序列化才能得知变更,而是在写入端配置格式兼容性,注册新 schema 的时候就去做一些干预,就能够更快速地进行一些对于读写客户端应用的管理。
2. 项目介绍
基于这样的一些动机,我们就开发了 Pravega Schema Registry 这样一个项目。
它是存储和管理 Pravega 中半结构化数据的 schema,然后也提供了 RESTful 接口来管理存储的 schema,数据的编码格式,兼容性策略的功能。我们提供的接口抽象是非常开放的,不仅内置了 Avro、protobuf、Json 等常见的序列化格式,lz4、snappy 等常见的压缩算法之外,也支持一些自定义的序列化方法。这样的抽象相比于业界其他一些类似的项目,是一个更通用的解决方案。我们在所有的序列化管理中,都可以自定义相应的编码格式与兼容性策略,方便用户自由地使用任何序列化方式来处理数据。整个项目是以 Pravega Key Value Table 的功能进行存储的,这也是 Schema Registry 的底层实现。Pravega Key Value Table 在之前也只是 Pravega 内部存储元数据的组件之一,慢慢的我们开发了公共的 API,并且在 0.8 版本变为 public 可用,并在 0.10 版本进入了一个 beta 的稳定版本。
Pravega Schema Registry 这一个项目其实也保持着相对的独立性,除了底层的实现使用了 Pravega key value table 之外,上层的所有抽象都是独立且不限于 Pravega 的,整个项目也不开源在 Pravega 内部,而是作为生态中的单独的一个项目。这样就可以被更多通用的存储系统,包括常见的文件和对象存储,作为 schema 管理的解决方案。
3. 系统架构
整个项目的系统架构如图所示。
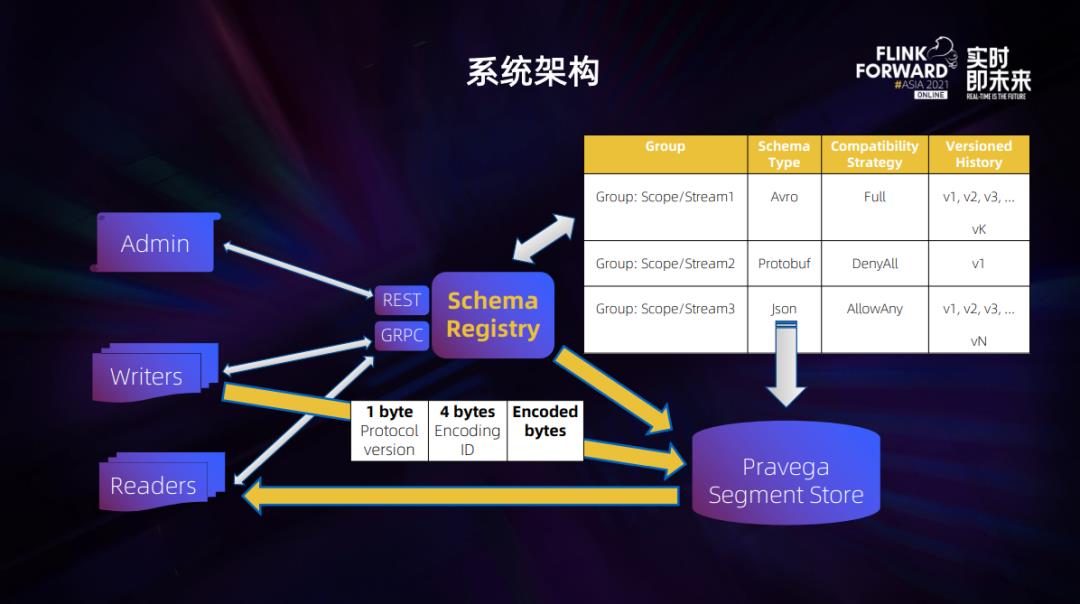
Schema Registry 可以通过 RESTful API 以及 GRPC 协议与 client 端进行互动。Group 对应一个 schema 管理的单元,在 Pravega 就对应一个Stream,其中会存储默认的序列化格式、兼容性配置以及多版本的序列化信息和编码信息。正如之前提到的,这些信息会以键值对的形式存储在 Pravega segment 上。
从数据链路来看,写端需要使用一个特殊的带有 protocol version 和 encoding id 的 header bytes 的 event 序列化方法,这样 Schema Registry 才可以从中介入,去注册或是验证数据的 schema,查看是否符合编码和兼容性要求,然后才能允许 schema 合法的数据进入 Pravega stream 的存储当中。同样,读端也需要用这样的特殊的反序列化进行读取。
二、Catalog API 集成
有了 Schema Registry,其实 Catalog 和 Pravega 映射关系也就比较明显了。
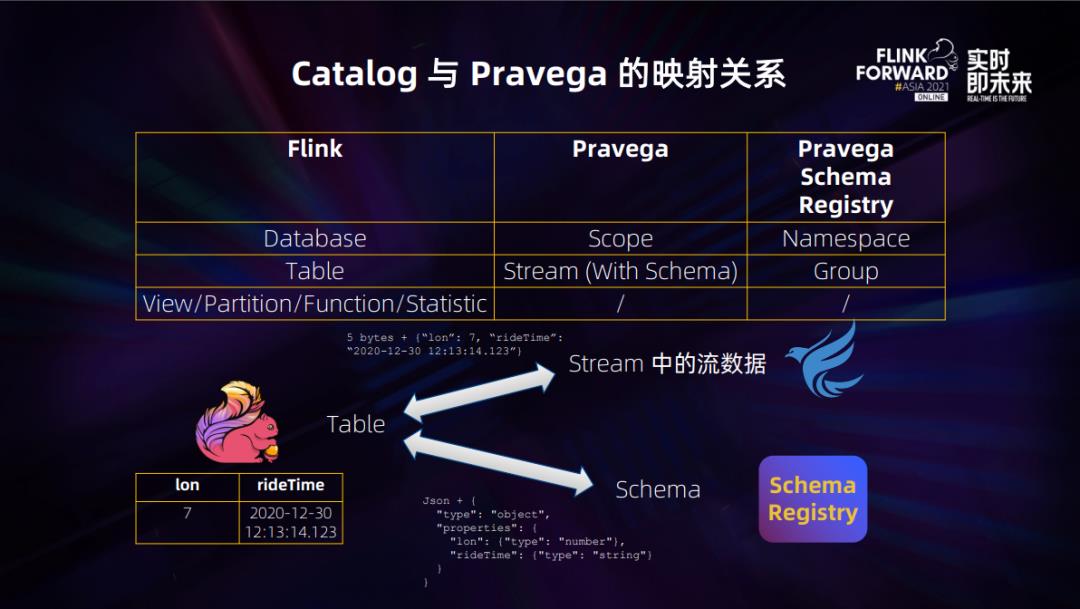
如图所示,stream 中的流数据加上 Schema Registry 存储的 schema,我们就可以成功地反序列化并根据表结构合成 Flink Catalog 中的一张表,同样对于表到流的转换也可以以相反的链路完成。因此,对于传统的 Catalog 操作例如建表、删表、删库等操作就可以抽象为对于 Pravega 和 Schema Registry 的元数据变更。
基于这样的理论,我们就初步实现了catalog 的接口,使得用户可以使用以下的 DDL 建立 catalog ,使用 SQL 就可以操作 Pravega 的元数据。
CREATE CATALOG pravega_catalog WITH(
'type' = 'pravega',
'default-database' = 'scope1',
'controller-uri' = 'tcp://localhost:9090',
'schema-registry-uri' = 'http://localhost:9092'
);实现难点
但是,当我们在初版的雏形上进一步打磨时,我们就遇到了三个实现细节上的难点。
第一个是 schema 和序列化的处理。Flink 在 1.12 版本之前,对于 Json 和 Avro 的数据与 Flink 表的行记录的内部抽象
RowData转换的过程是 Flink 在 format 下的内部且 private 类。因此我们想要重用这一部分代码来保持与 Flink 对于 schema 以及序列化转换行为的一致性,就不得不复制整个的类库。因此我们就向社区提出了这样一个想法,能不能把它抽象出来,并转换为 public 的类。经过与社区的讨论和沟通,我们也开了相应的 JIRA FLINK-19098[1]且贡献代码修复了这一问题,成功打通了在 Catalog table 转换的数据序列化的链路。第二点是同时支持 Avro 和 Json 的格式。在现有的 catalog 实现中,序列化方法其实是相对固定的,这其实与 Pravega Schema Registry 设计理念里面的通用性有些不一致。可能有些用户习惯使用 Avro,而其他的有些习惯使用 Json,我们如何兼顾这两者的需求,使得他们都能享受到 catalog 带来的便利呢?我们这里在 catalog 引入了 serialization format 的选项,打通了不但可以指定 Avro 和 Json,更可以添加 Flink 官方支持的所有序列化附加配置,例如 timestamp 的序列化格式,进一步定制应用于整个 catalog 序列的方法。
难点三就是我们通过 Schema Registry 处理的 event 开头会有五个 byte 的 header,导致没有办法直接使用 Flink 现成的 Json 和 Avro format 进行序列化,为了使用到 Schema Registry 提供的序列化器 API,我们就需要开发自己的一套 format factory 去调用。具体到实现,我们是将 Catalog table 中与序列化,也就是 Schema Registry API 所需要的相关参数,包括 namespace、group 等信息,沿袭到 format factory 参数当中去,也就相当于如下的建表 DDL。
CREATE TABLE clicks (
...
) WITH (
'connector' = 'pravega',
...
'format' = 'pravega-registry',
'pravega-registry.uri' = 'tcp://localhost:9092',
'pravega-registry.namespace' = 'scope1',
'pravega-registry.group-id' = 'stream1',
'pravega-registry.format' = 'Avro'
);然后在实现中拿到这些信息去调用 Schema Registry 的API,再拼接上之前提到的问题的修复,我们就完成了完整的二进制数据与 Flink RowData 的一个互操作。整个链路就通了。
[1] https://issues.apache.org/jira/browse/FLINK-19098
三、Debezium 支持
首先,我们来介绍一下整个大的 CDC 的一个概念。CDC的全称是 Change Data Capture,是确定和跟踪数据变更,然后采取行动的一种方法论。但实际上这是一个广义的概念。在现代更多的业界的实践经验当中,CDC 更多以相对狭义的技术名词出现,即针对数据库的场景,对于数据库的日志分析,然后将其转变成特定格式的数据流的一种新的技术。比如常见的实现,例如 Debezium 以及国内常用的 Canal 等。
Debezium 作为业界最广泛应用的 CDC 技术,它是基于 Kafka Connect 实现的,是将数据库行级的变更转换为事件流的分布式平台。现在业界的 CDC 技术的应用场景也非常广泛,有用于备份,容灾的数据同步,也有向多个下游系统的数据分发,也有对接数据湖的 ETL 集成。
1. 部署方式
目前 Debezium 有三种部署方式:
第一种,也是业界最常用的一种利用 Kafka Connect 进行部署。之前也提到,这也是 Debezium 创始之处就支持的一种使用方式,它是将 mysql 或者 Postgres DB 这样的传统数据库的 binlog 进行分析,通过 Kafka connect 的 Debezium source 实现导到 Apache Kafka 中。利用 Kafka 强大的生态,可以对接丰富的下游引擎,来做进一步的聚合计算和数仓数据湖的应用。
第二点,其实 Debezium 社区也看到了在消息队列和流存储领域的变化,慢慢地剥离 Kafka。它现在可以支持启动单独的 Debezium server 使用 source connector 连接下游的消息系统。现在已有集成的例如 Amazon Kinesis 以及 Google 的 PubSub。在 2021 年上半年,Debezium 社区发布了 1.6 版本,在这个发版中,Debezium 也正式接纳了我们 Pravega 社区的贡献。Pravega 端的 sink 也成为了 source connector 的实现之一,实现了与 Debezium 社区的牵手。
最后一种方式是将 Debezium 作为一个依赖库嵌入 Java 程序进行调用。比较有名的就是社区非常火热的云邪和雪尽老师负责的 Flink CDC connector。在无需长期存储或是重复利用 CDC 数据的场景中,这样轻量级的实现能移除消息队列部署运维的复杂性,同时依然保证计算的可靠性和容错性。
2. 写入方式

在 Debezium 与 Pravega 集成的过程中,我们保持了实现的完整性,也提供了普通写入和事务性写入两种写的方式。
Debezium server 在 source connector 中其实是一个周期性的、批量的拉取过程,就是接口端会收到一个 Debezium batch 的 upsert 流。从右图中可以看到,每一个括号内的都是一次拉取的 batch,其中黄色就代表update,白色的就代表 insert。
如果是普通的写,我们会对所有的不管是 insert 还是 update 的 event,以单独的 event 的方式顺序地写入。大家也不用担心在分布式环境下的顺序问题。因为每一个 Debezium event 都是带着数据库表中的 key 的。然后 Pravega 写入的时候,也可以携带相应的 routing key 来使得相同 key 的 event 落入同样的 segment,Pravega 能够保证相同 routing key 上的数据的有序性。
接下来看事务性的写入,对于每一个 Debezium batch,Pravega 都将其封装在一个 transaction 当中,在 batch complete 的时候提交这个 Pravega 的事务。这样当 Debezium server 发生 failover 的时候,由于 Pravega transaction 的原子性和幂等性保证,所有的 event 都能不重复地得到回放并输出,这样子就可以确保精确一次语义了。
在 1.6 版本之后,用户也可以使用表中所示的参数去配置 Debezium server,只需要填上相应的 Pravega 的连接参数,指定 scope 名称和事务性写入开关,就可以实时同步 MySQL 等数据库的一个 database 中所有表的变化,以 Debezium 的消息格式写入到与表名同名的 Pravega stream 当中。
3. Connector 集成
除了在 Debezium 中 Pravega 的贡献之外,为了利用 Flink 的流处理能力来消费数据,我们也需要在计算端的 Pravega Flink connector 端做相应的集成。
我们在现有的 FLIP-95 的 Table API 上实现了 Table Factory 来支持基本读写的功能。可能有些了解 Flink Table API 的人会问,社区已经提供了 debezium-json 这样的 format factory 的实现,似乎直接套用,指定相应的 format 就可以简单地使用了,又有什么难点呢?
起初我们也这么认为,但是事情远没有想象的那么简单。我们主要碰到的难点有两个。
其一是需要额外支持反序列为多个 event 的功能。
Debezium 提供的是一个 upsert 流,那在转化 Flink table 的 Rowdata 抽象时,对于 insert 的 event 是一个常见的一对一的反序列化的过程。但是对于 update ,我们就需要转换成更新前和更新后状态的两个 event。这和我们对于 connector 序列化的实现默认一对一是完全违背的。
由于 Pravega 自身的序列化器接口也是一个一对一的映射,并且为了保证 Pravega 序列化器与 Flink DeserializationSchema 接口的互操作性,我们也在上面做了不少的代码支持,方便用户使用。为了支持这一新的需求,我们就不得不重构之前的反序列化链路,将原有的反序列过程从 Pravega client 端上提到 Pravega connector 内部去做,从而利用如下带有 collector 的 deserialize 方法。
default void deserialize(byte[] message, Collector<T> out) throws IOException 同时整个代码修改的链路也需要非常小心,依然保证了原有的 Pravega 序列化器与 Flink API 转化 API 的兼容性,从而不影响线上用户的可升级性。
其次是 FLIP-107,关于 Table source 端 metadata 的支持。
Pravega Table Source 实现了 Flink 提供的 SupportsReadingMetadata 的接口,提供了这样一个支持。用户可以 from-format 的前缀来指定来自 format factory 本身的 metadata,例如 Debezium 的 ingestion timestamp,table 名称等元信息来完善和丰富表的信息。同时我们还支持了来自 Pravega 本身的 metadata,称为 EventPointer 来记录当前 event 在 stream 中的位置信息,记录这一信息也有助于用户存储这一数据,然后来完成后续的随机读取甚至建立索引的需求。整个包含了 metadata 的 create table 的建表的 DDL 如下,这些新建的列在 Flink Table 的抽象中会出现在原始数据结构的后面依次排列。
CREATE TABLE debezium_source (
// Raw Schema
id INT NOT NULL,
// Format metadata
origin_ts TIMESTAMP(3) METADATA FROM 'from_format.ingestion-timestamp' VIRTUAL,
origin_table STRING METADATA FROM 'from_format.source.table' VIRTUAL,
// Connector metadata
event_pointer BYTES METADATA VIRTUAL
);以上就是我们完整的从 Pravega 到 Connector 的 Debezium 支持的过程。
四、社区联合白皮书发布

滕昱 (左) - Pravega 中国社区创始人,戴尔科技集团 OSA 软件开发总监
秦江杰 (右) - Apache Flink PMC,阿里巴巴开源大数据团队生态技术负责人
数据库的 CDC 实时处理是大数据行业中非常重要的应用场景,例如数据同步、分发以及实时数仓等常见的应用。有了 Debezium 的集成之后,利用 Apache Flink 与 Debezium,Pravega 就可以作为统一的消息中间存储层的解决方案,满足用户的数据库同步的需求。该方案以 Pravega 作为消息中间件,能够充分发挥 Pravega 的实时持久化存储特性,能够在保证链路的毫秒级的实时性以及数据一致性的基础上,进一步提供数据的可靠存储以供其他应用的数据复用。同时利用 Apache Flink 下游的丰富生态,可以方便地接入更多的系统之中,从而满足各式各样的业务需求。整个集成的过程,是依靠了 Pravega 与 Flink 社区通力合作完成。
Pravega 社区也非常高兴可以联合 Flink 社区发布我们联手打造的 Pravega × Flink 构建数据库实时同步的开源解决方案白皮书。有兴趣的小伙伴可以点击链接获取详细信息。
https://flink-learning.org.cn

FFA 2021 直播回放 & 演讲 PDF 获取

更多 Flink 相关技术问题,可扫码加入社区钉钉交流群~

 戳我,获取 FFA 2021 峰会资料~
戳我,获取 FFA 2021 峰会资料~
以上是关于Pravega Flink Connector Table API 进阶功能探秘的主要内容,如果未能解决你的问题,请参考以下文章
Pravega Flink Connector Table API 进阶功能探秘
重磅!Flink 完美搭档:开源分布式流存储 Pravega
在流式系统中如何引入Watermark支持:以Pravega和Flink为例