Flink 完美搭档:数据存储层上的 Pravega
Posted ludongguoa
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Flink 完美搭档:数据存储层上的 Pravega相关的知识,希望对你有一定的参考价值。
文章整理 :加米谷大数据
本文将从大数据架构变迁历史,Pravega 简介,Pravega 进阶特性以及车联网使用场景这四个方面介绍 Pravega,重点介绍 DellEMC 为何要研发 Pravega,Pravega 解决了大数据处理平台的哪些痛点以及与 Flink 结合会碰撞出怎样的火花。
大数据架构变迁
Lambda 架构之痛
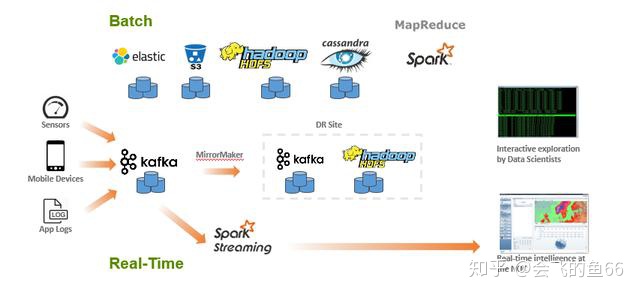
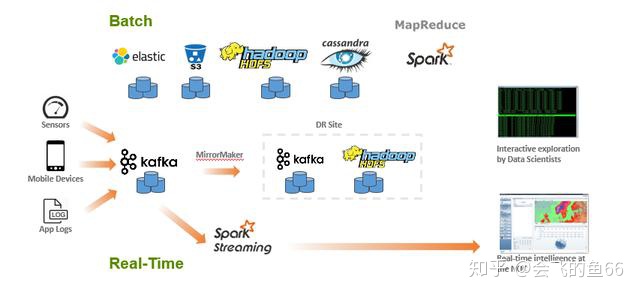
如何有效地提取和提供数据,是大数据处理应用架构是否成功的关键之处。由于处理速度和频率的不同,数据的摄取需要通过两种策略来进行。上图就是典型的 Lambda架构:把大数据处理架构分为批处理和实时流处理两套独立的计算基础架构。
对于实时处理来说,来自传感器,移动设备或者应用日志的数据通常写入消息队列系统(如 Kafka), 消息队列负责为流处理应用提供数据的临时缓冲。然后再使用 Spark Streaming 从 Kafka 中读取数据做实时的流计算。但由于 Kafka 不会一直保存历史数据,因此如果用户的商业逻辑是结合历史数据和实时数据同时做分析,那么这条流水线实际上是没有办法完成的。因此为了补偿,需要额外开辟一条批处理的流水线,即图中" Batch "部分。
对于批处理这条流水线来说,集合了非常多的的开源大数据组件如 ElasticSearch, Amazon S3, HDFS, Cassandra 以及 Spark 等。主要计算逻辑是是通过 Spark 来实现大规模的 Map-Reduce 操作,优点在于结果比较精确,因为可以结合所有历史数据来进行计算分析,缺点在于延迟会比较大。
这套经典的大数据处理架构可以总结出三个问题:
- 两条流水线处理的延迟相差较大,无法同时结合两条流水线进行迅速的聚合操作,同时结合历史数据和实时数据的处理性能低下。
- 数据存储成本大。而在上图的架构中,相同的数据会在多个存储组件中都存在一份或多份拷贝,数据的冗余无疑会大大增加企业客户的成本。并且开源存储的数据容错和持久化可靠性一直也是值得商榷的地方,对于数据安全敏感的企业用户来说,需要严格保证数据的不丢失。
- 重复开发。同样的处理流程被两条流水线进行了两次,相同的数据仅仅因为处理时间不同而要在不同的框架内分别计算一次,无疑会增加数据开发者重复开发的负担。
流式存储的特点
在正式介绍 Pravega 之前,首先简单谈谈流式数据存储的一些特点。
如果我们想要统一流批处理的大数据处理架构,其实对存储有混合的要求。
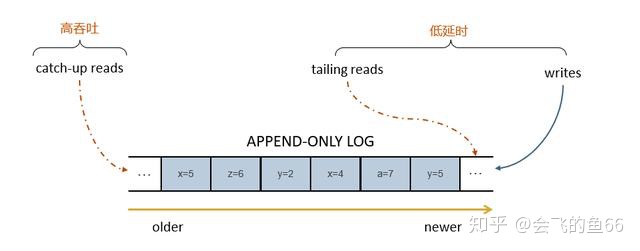
- 对于来自序列旧部分的历史数据,需要提供高吞吐的读性能,即 catch-up read
- 对于来自序列新部分的实时数据,需要提供低延迟的 append-only 尾写 tailing write 以及尾读 tailing read
重构的流式存储架构
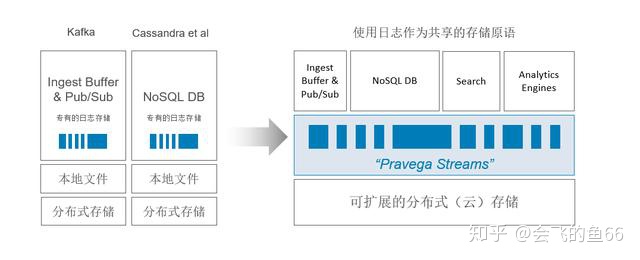
像 Kafka,Cassandra 等分布式存储组件来说,其存储架构都从上往下遵循从专有的日志存储,到本地文件,再到集群上的分布式存储的这种模式。
而 Pravega 团队试图重构流式存储的架构,引入 Pravega Stream 这一抽象概念作为流式数据存储的基本单位。Stream 是命名的、持久的、仅追加的、无限的字节序列。
如上图所示,存储架构最底层是基于可扩展分布式云存储,中间层表示日志数据存储为 Stream 来作为共享的存储原语,然后基于 Stream 可以向上提供不同功能的操作:如消息队列,NoSQL,流式数据的全文搜索以及结合 Flink 来做实时和批分析。换句话说,Pravega 提供的 Stream 原语可以避免现有大数据架构中原始数据在多个开源存储搜索产品中移动而产生的数据冗余现象,其在存储层就完成了统一的数据湖。
重构的大数据架构
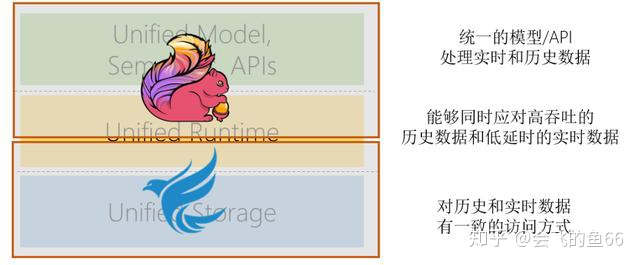
我们提出的大数据架构,以 Apache Flink 作为计算引擎,通过统一的模型/API来统一批处理和流处理。以 Pavega 作为存储引擎,为流式数据存储提供统一的抽象,使得对历史和实时数据有一致的访问方式。两者统一形成了从存储到计算的闭环,能够同时应对高吞吐的历史数据和低延时的实时数据。同时 Pravega 团队还开发了 Flink-Pravega Connector,为计算和存储的整套流水线提供 Exactly-Once 的语义。
Pravega 简介
Pravega 的设计宗旨是为流的实时存储提供解决方案。应用程序将数据持久化存储到 Pravega 中,Pravega 的 Stream 可以有无限制的数量并且持久化存储任意长时间,使用同样的 Reader API 提供尾读 (tail read) 和追赶读 (catch-up read) 功能,能够有效满足离线计算和实时计算两种处理方式的统一。
Pravega 基本概念
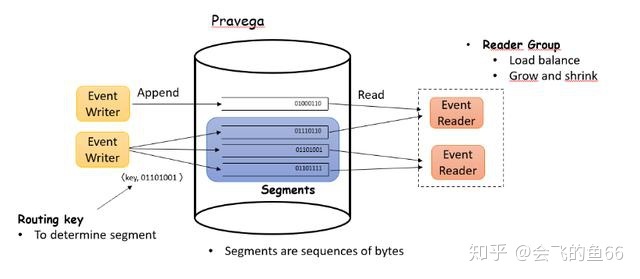
结合上图简要介绍 Pravega 的基本概念:
- Stream
Pravega 会把写入的数据组织成 Stream,Stream 是命名的、持久的、仅追加的、无限的字节序列。
- Stream Segments
Pravega Stream 会划分为一个或多个 Segments,相当于 Stream 中数据的分片,它是一个 append-only 的数据块,而 Pravega 也是基于 Segment 基础上实现自动的弹性伸缩。Segment 的数量也会根据数据的流量进行自动的连续更新。
- Event
Pravega\'s client API 允许用户以 Event 为基本单位写入和读取数据,Event 具体是Stream 内部字节流的集合。如 IOT 传感器的一次温度记录写入 Pravega 就可以理解成为一个 Event.
- Routing Key
每一个 Event 都会有一个 Routing Key,它是用户自定义的一个字符串,用来对相似的 Event 进行分组。拥有相同 Routing Key 的 Event 都会被写入相同的 Stream Segment 中。Pravega 通过 Routing Key 来提供读写语义。
- Reader Group
用于实现读取数据的负载均衡。可以通过动态增加或减少 Reader Group 中 Reader的数量来改变读取数据的并发度。更为详细的介绍请参考 Pravega 官方文档:
Pravega 系统架构
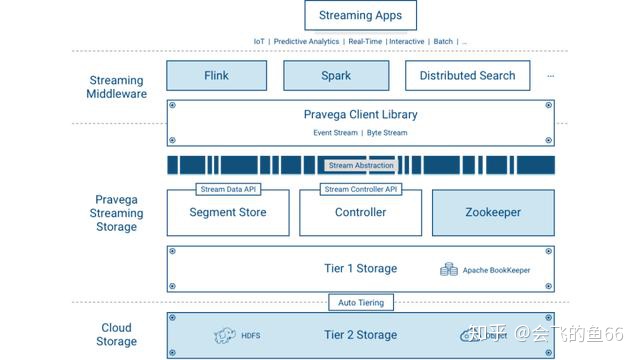
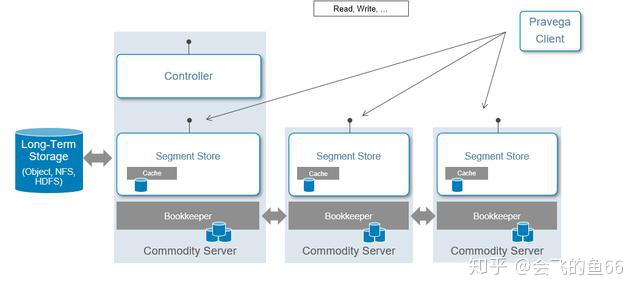
在控制层面,Controller 作为 Pravega 集群的主节点对数据层面的 Segment Store做管理,提供对流数据的创建,更新以及删除等操作。同时它还承担实时监测集群健康状态,获取流数据信息,收集监控指标等功能。通常集群中会有3份 Controller 来保证高可用。
在数据层面,Segment Store 提供读写 Stream 内数据的 API。在 Pravega 里面,数据是分层存储的:
- Tier 1 存储
Tier1 的存储通常部署在 Pravega 集群内部,主要是提供对低延迟,短期的热数据的存储。在每个 Segment Store 结点都有 Cache 以加快数据读取速率,Pravega 使用Apache Bookeeper 来保证低延迟的日志存储服务。
- Long-term 存储
Long-term 的存储通常部署在 Pravega 集群外部,主要是提供对流数据的长期存储,即冷数据的存储。不仅支持 HDFS,NFS,还会支持企业级的存储如 Dell EMC的 ECS,Isilon 等产品。
Pravega 进阶特性
读写分离
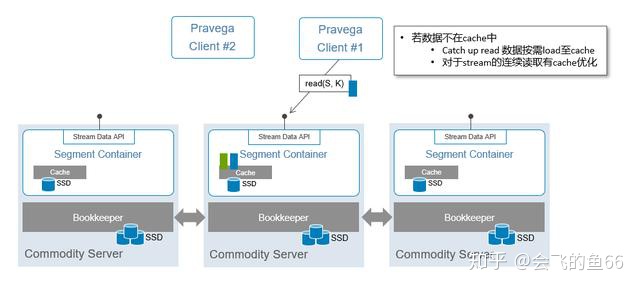
在 Tier1 存储部分,写入数据的时候通过 Bookkeeper 保证了数据已经在所有的 Segment Store 中落盘,保证了数据写入成功。
读写分离有助于优化读写性能:只从 Tier1 的 Cache 和 Long-term 存储去读,不去读 Tier1 中的 Bookkeeper。
在客户端向 Pravega 发起读数据的请求的时候,Pravega 会决定这个数据究竟是从Tier1 的 Cache 进行低延时的 tail-read,还是去 Long-term 的长期存储数据(对象存储/NFS)去进行一个高吞吐量的 catch-up read(如果数据不在 Cache,需要按需load 到 Cache 中)。读操作是对客户端透明的。
Tier1 的 Bookkeeper 在集群不出现故障的情况下永远不进行读取操作,只进行写入操作。
弹性伸缩
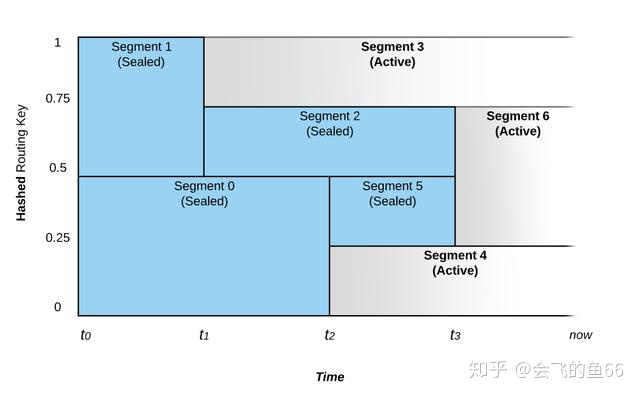
Stream 中的 Segment 数量会随着 IO 负载而进行弹性的自动伸缩。以上图为例子简单阐述:
- 数据流在 t0 时刻写入 Pravega,根据路由键数据会路由到 Segment0 和Segment1 中,如果数据写入速度保持恒定不变,那么 Segemnt 数量不会发生变化。
- 在 t1 时刻系统感知到 segment1 数据写入速率加快,于是将其划分为两个部分:Segment2 和 Segment3。这时候 Segment1 会进入 Sealed 状态,不再接受写入数据,数据会根据路由键分别重定向到 Segment2 和 Segment3.
- 与 Scale-Up 操作相对应,系统也可以根据数据写入速度变慢后提供二手游戏账号地图操作。如在 t3 时刻系统 Segment2 和 Segment5 写入流量减少,因此合并成新的 Segment6。
端到端的弹性伸缩
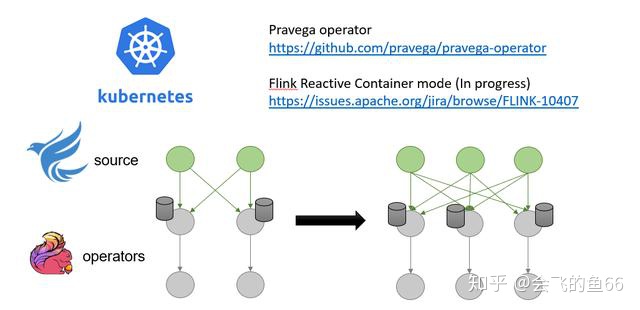
Pravega 是以 Kubernetes Operator 来对集群各组件进行有状态的应用部署,这可以使得应用的弹性伸缩更为灵活方便。
Pravega 最近也在和 Ververica 进行深度合作,致力于在 Pravega 端实现 Kubernetes Pod 级别的弹性伸缩同时在 Flink 端通过 rescaling Flink 的 Task 数量来实现弹性伸缩。
事务性写入
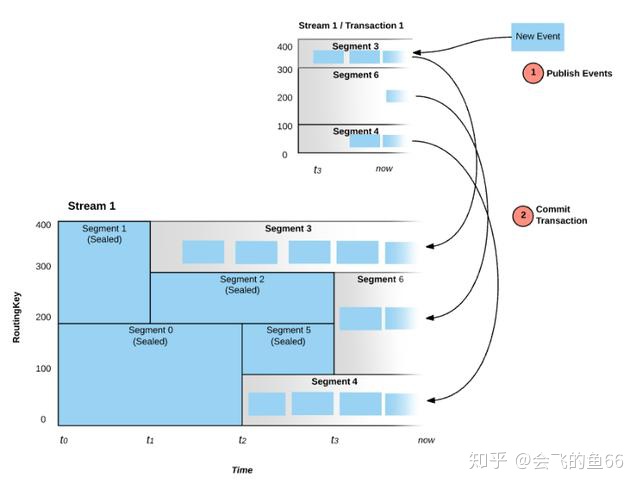
Pravega 同样提供事务性的写入操作。在提交事务之前,数据会根据路由键写入到不同的 Transaction Segment 中,这时候 Segment 对于 Reader 来说是不可见的。只有在事务提交之后,Transaction Segment 才会各自追加到 Stream Segment 的末尾,这时候 Segment 对于 Reader 才是可见的。写入事务的支持也是实现与 Flink 的端到端 Exactly-Once 语义的关键。
Pravega vs. Kafka
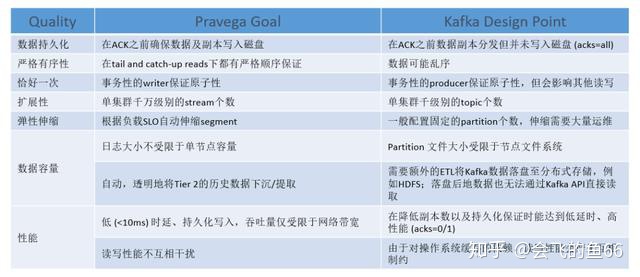
首先最关键的不同在于两者的定位:Kafka 的定位是消息队列,而 Pravega 的定位是存储,会更关注于数据的动态伸缩,安全性,完整性等存储特性。
对于流式数据处理来说,数据应该被视为连续和无限的。Kafka 作为基于本地文件系统的一个消息队列,通过采用添加到日志文件的末尾并跟踪其内容( offset 机制)的方式来模拟无限的数据流。然而这种方式必然受限于本地文件系统的文件描述符上限以及磁盘容量,因此并非无限。
而两者的比较在图中给出了比较详细的总结,不再赘述。
Pravega Flink Connector
为了更方便与 Flink 的结合使用,我们还提供了 Pravega Flink Connector, Pravega 团队还计划将该 Connector 贡献到 Flink 社区。Connector 提供以下特性:
- 对 Reader 和 Writer 都提供了 Exactly-once 语义保证,确保整条流水线端到端的 Exactly-Once
- 与 Flink 的 checkpoints 和 savepoints 机制的无缝耦合
- 支持高吞吐低延迟的并发读写
- Table API 来统一对 Pravega Sream 的流批统一处理
车联网使用场景
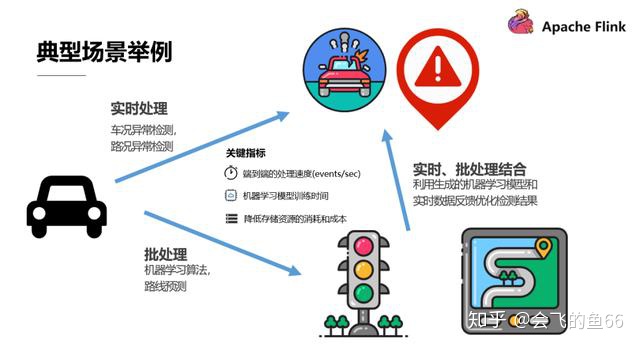
以无人驾驶车联网这种能够产生海量 PB 级数据的应用场景为例:
- 需要对车况路况数据做实时的处理以及时对路线规划做出微观的预测和规划
- 需要对较长期行驶数据运行机器学习算法来做路线的宏观预测和规划,这属于批处理
- 同时需要结合实时处理和批处理,利用历史数据生成的机器学习模型和实时数据反馈来优化检测结果
而客户关注的关键指标主要在:
- 如何保证高效地端到端处理速度
- 如何尽可能减少机器学习模型的训练时间
- 如何尽可能降低存储数据的消耗与成本
下面给出引入 Pravega 前后的解决方案比较。
解决方案比较
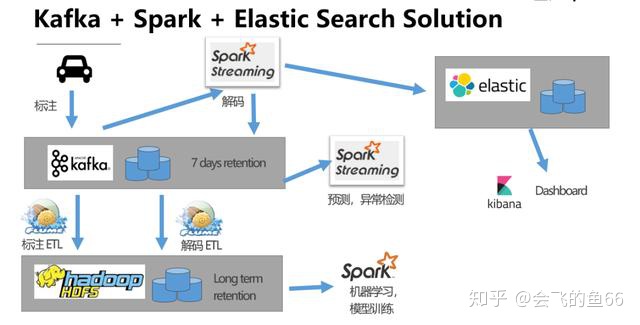
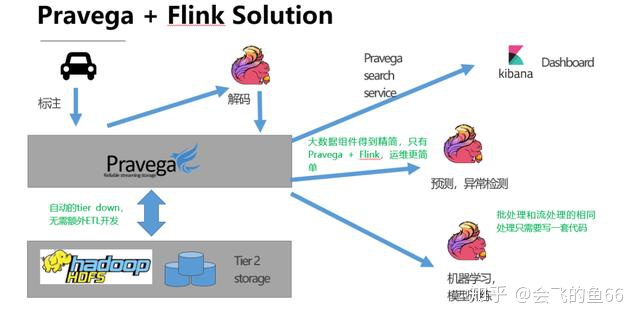
Pravega 的引入无疑大大简洁了大数据处理的架构:
- Pravega 作为抽象的存储接口,数据在 Pravega 层就实现了一个数据湖:批处理,实时处理和全文搜索都只需要从 Pravega 中获取数据。数据只在 Pravega 存储一份,而不需要像第一种方案中数据冗余地存储在 Kafka,ElasticSearch 和 Long Term Storage 中,这可以极大减少了企业用户数据存储的成本。
- Pravega 能够提供自动的 Tier Down,无需引入 Flume 等组件来进行额外的 ETL 开发。
- 组件得到精简,从原来的 Kafka+Flume+HDFS+ElasticSearch+Kibana+Spark+SparkStreaming 精简到 Pravega+Flink+Kibana+HDFS ,减轻运维人员的运维压力。
- Flink 能够提供流批处理统一的功能,无需为相同的数据提供两套独立的处理代码。
总 结
Flink 俨然已经成为流式计算引擎中的一颗闪亮的明星,然而流式存储领域尚是一片空白。而 Pravega 的设计初衷就是为了填上大数据处理架构这一拼图最后的空白。“所有计算机领域的问题,都可以通过增加一个额外的中间层抽象解决”,而 Pravega 本质就是在计算引擎和底层存储之间充当解耦层,旨在解决新一代大数据平台在数据存储层上的挑战。
以上是关于Flink 完美搭档:数据存储层上的 Pravega的主要内容,如果未能解决你的问题,请参考以下文章