模型扫描识别图片
Posted 卓晴
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了模型扫描识别图片相关的知识,希望对你有一定的参考价值。
简 介: 使用模型对于识别图片进行扫描,会在对应的图片位置出现峰值。但对于其他数字也呈现了不同的波动。基于这种现象对于动态确定数字的位置还需要进一步测试标注。
关键词: 七段数字,识别
§01 扫描图片
在 对于七段数码数字模型进行改进:一个关键的数字1的问题 中训练了一款具有更好泛化特性的网络模型,下面测试一下它对于图片的一维,二维扫描的情况。为:
- 找到更好的图片分割的方法;
- 实现图片中特定对象定位;
给出实验基础。

▲ 图 扫描识别对象
from headm import * # =
rangeid = 4
imgid = 2
boxid = 3
printt(rangeid:, boxid)
rangerect = tspgetrange(imgid)
boxrect = tspgetrange(boxid)
printt(rangerect:, boxrect:)
centery = (boxrect[1] + boxrect[3])//2
boxwidth = boxrect[2] - boxrect[0]
pltgif = PlotGIF()
for x in linspace(rangerect[0]+boxwidth/2, rangerect[2]-boxwidth/2, 50):
_ = tspsetdopside(boxid, 4, int(x))
_ = tsprv()
time.sleep(.1)
pltgif.appendbox(rangeid)
pltgif.save()
1.1 七段数码识别模型
在对于七段数码数字模型进行改进:一个关键的数字1的问题中建立的七段数码识别模型为:seg7model4_1_all.pdparams。它的结构代码:
import paddle
import paddle.fluid as fluid
import cv2
imgwidth = 48
imgheight = 48
inputchannel = 1
kernelsize = 5
targetsize = 10
ftwidth = ((imgwidth-kernelsize+1)//2-kernelsize+1)//2
ftheight = ((imgheight-kernelsize+1)//2-kernelsize+1)//2
class lenet(paddle.nn.Layer):
def __init__(self, ):
super(lenet, self).__init__()
self.conv1 = paddle.nn.Conv2D(in_channels=inputchannel, out_channels=6, kernel_size=kernelsize, stride=1, padding=0)
self.conv2 = paddle.nn.Conv2D(in_channels=6, out_channels=16, kernel_size=kernelsize, stride=1, padding=0)
self.mp1 = paddle.nn.MaxPool2D(kernel_size=2, stride=2)
self.mp2 = paddle.nn.MaxPool2D(kernel_size=2, stride=2)
self.L1 = paddle.nn.Linear(in_features=ftwidth*ftheight*16, out_features=120)
self.L2 = paddle.nn.Linear(in_features=120, out_features=86)
self.L3 = paddle.nn.Linear(in_features=86, out_features=targetsize)
def forward(self, x):
x = self.conv1(x)
x = paddle.nn.functional.relu(x)
x = self.mp1(x)
x = self.conv2(x)
x = paddle.nn.functional.relu(x)
x = self.mp2(x)
x = paddle.flatten(x, start_axis=1, stop_axis=-1)
x = self.L1(x)
x = paddle.nn.functional.relu(x)
x = self.L2(x)
x = paddle.nn.functional.relu(x)
x = self.L3(x)
return x
model = lenet()
model.set_state_dict(paddle.load('/home/aistudio/work/seg7model4_1_all.pdparams'))
1.2 测试图片
用于测试扫描的数码图片如下图所示。存储在③ rk/7seg/SegScan 中。

▲ 图1.2.1 用于测试的三个数码条
1.3 扫描数字图片
1.3.1 扫描代码
OUT_SIZE = 48
def scanimg1d(imgfile, scanStep):
img = cv2.imread(imgfile)
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
imgwidth = gray.shape[1]
imgheight = gray.shape[0]
imgarray = []
blockwidth = int(imgheight * 0.5)
startid = linspace(0, imgwidth-blockwidth, scanStep)
for s in startid:
left = int(s)
right = int(s+blockwidth)
data = gray[0:imgheight, left:right]
dataout =cv2.resize(data, (OUT_SIZE, OUT_SIZE))
dataout = dataout - mean(dataout)
stdd = std(dataout)
dataout = dataout/stdd
imgarray.append(dataout[newaxis, :,:])
model_input = paddle.to_tensor(imgarray, dtype='float32')
preout = model(model_input)
return preout
picimage = '/home/aistudio/work/7seg/SegScan/004-01234567.BMP'
out = scanimg1d(picimage, 200).numpy()
plt.figure(figsize=(12,8))
plt.plot(out[:,:3])
plt.xlabel("Scan Step")
plt.ylabel("Prediction")
plt.grid(True)
plt.tight_layout()
plt.show()
1.3.2 扫描结果
扫描数字的宽度为高度的一半。

▲ 图 扫描01234567
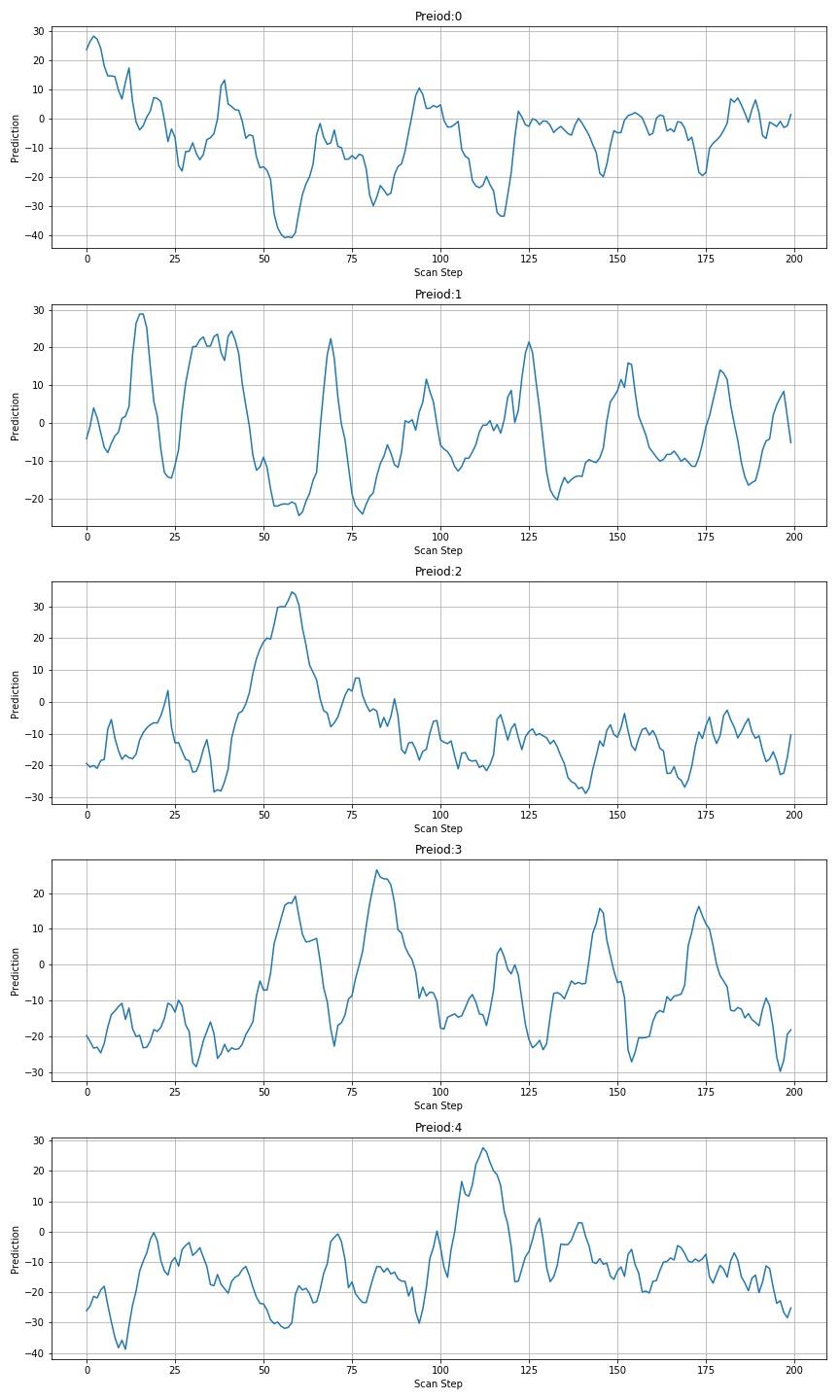
▲ 图1.3.2 前五个数字扫描预测结果
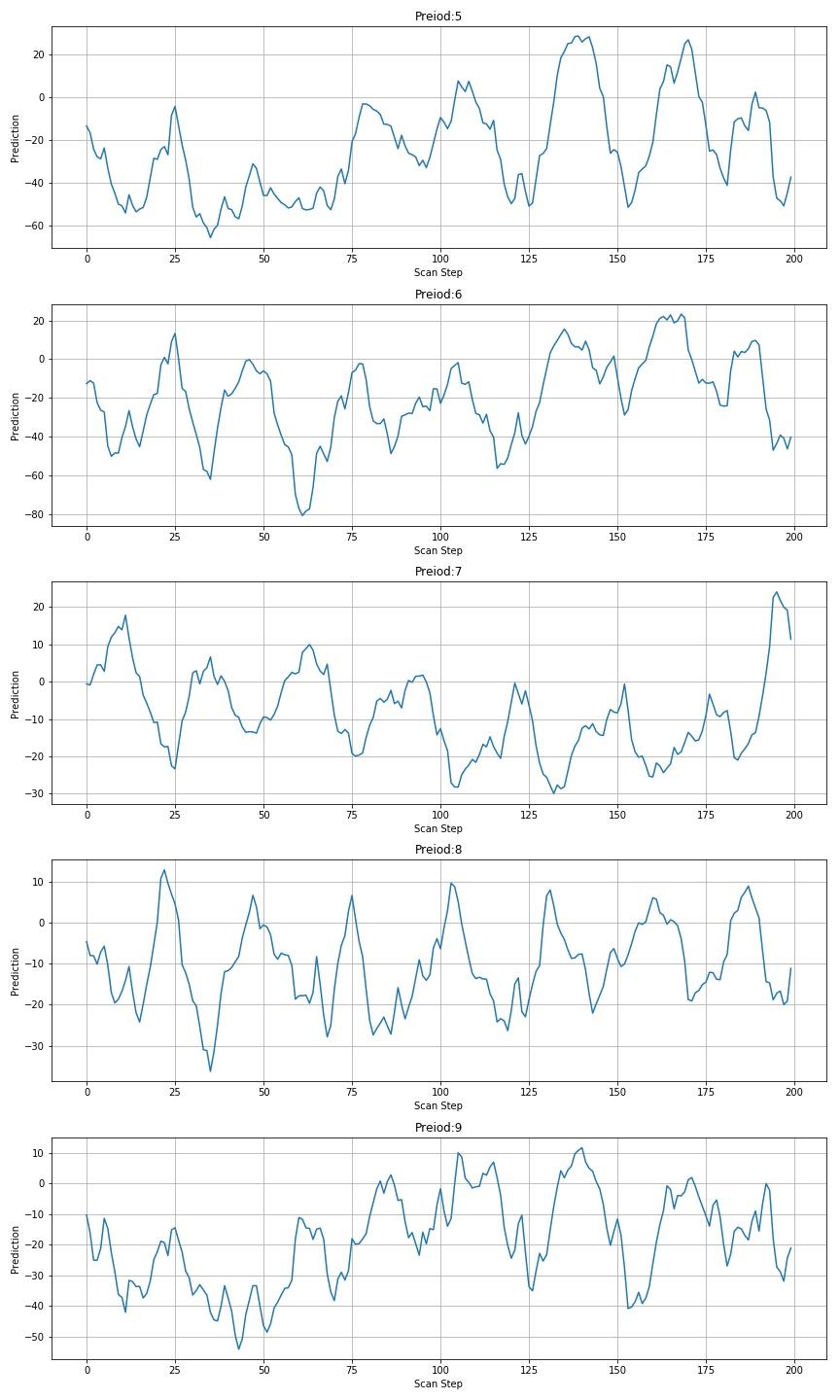
▲ 图1.3.3 后五个数字扫描预测结果
下面是使用0.75倍的高度宽度扫描后数值:
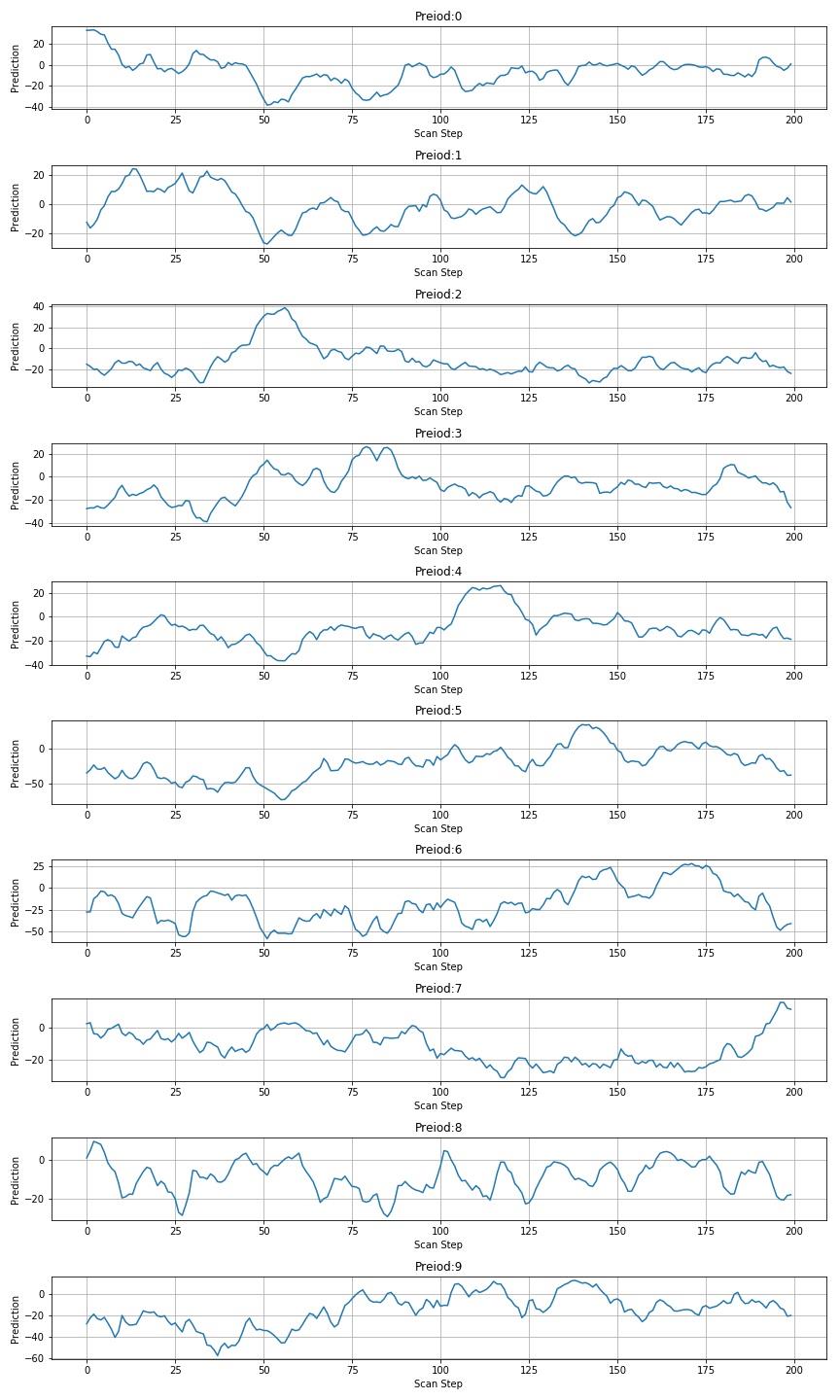
▲ 图1.3.4 使用高度0.75倍进行扫描后的数值
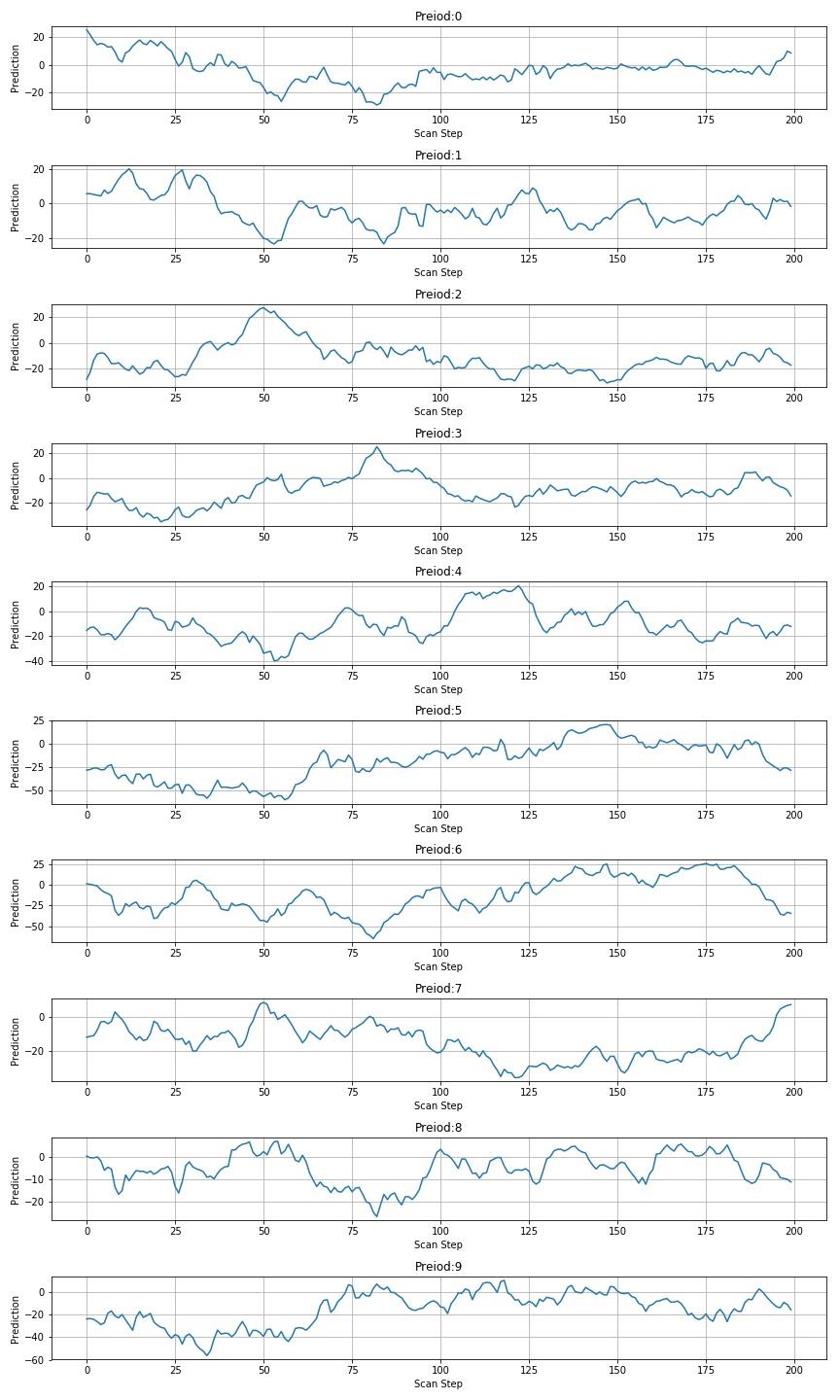
▲ 图1.3.5 使用高度相同宽度进行扫描后的数值
1.3.3 扫描426957

▲ 图 扫描426957
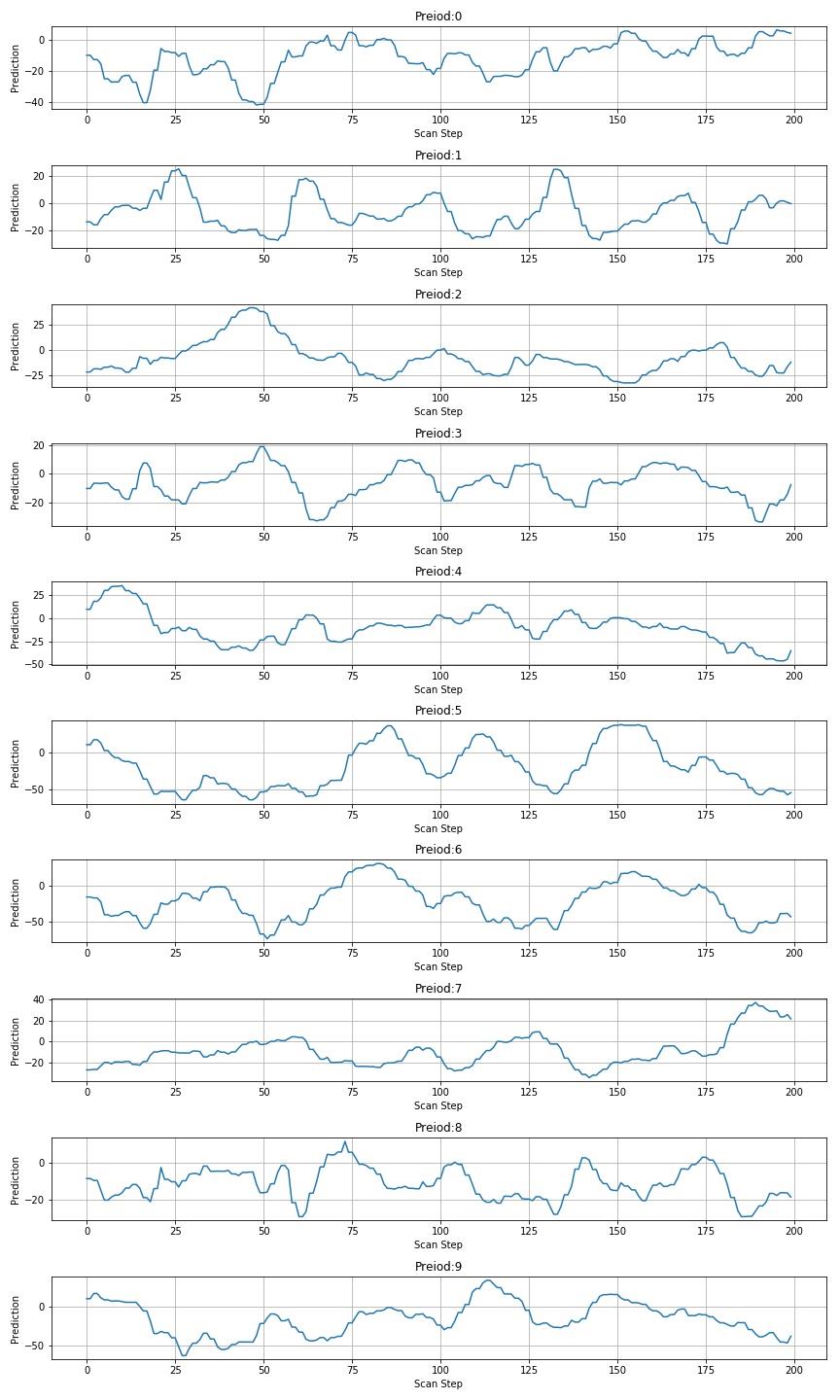
▲ 图1.3.7 扫描426957图片
1.3.4 扫描260612图片

▲ 图 扫描260612
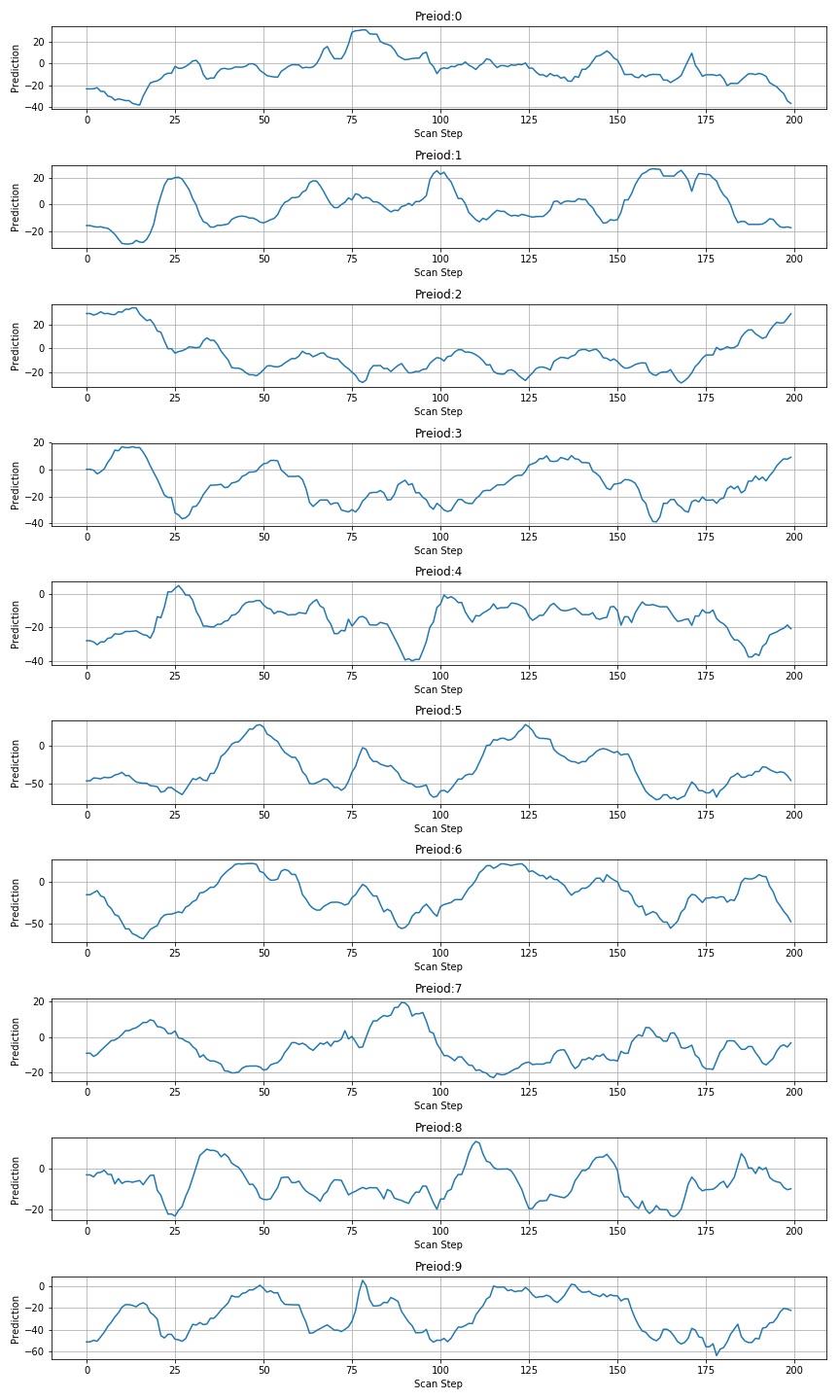
▲ 图1.3.9 扫描260612图片
※ 测试总结 ※
使用模型对于识别图片进行扫描,会在对应的图片位置出现峰值。但对于其他数字也呈现了不同的波动。基于这种现象对于动态确定数字的位置还需要进一步测试标注。
■ 相关文献链接:
● 相关图表链接:
- 图1.2.1 用于测试的三个数码条
- 图1.3.2 前五个数字扫描预测结果
- 图1.3.3 后五个数字扫描预测结果
- 图1.3.4 使用高度0.75倍进行扫描后的数值
- 图1.3.5 使用高度相同宽度进行扫描后的数值
- 图1.3.7 扫描426957图片
- 图1.3.9 扫描260612图片
#!/usr/local/bin/python
# -*- coding: gbk -*-
#============================================================
# TEST1.PY -- by Dr. ZhuoQing 2022-01-03
#
# Note:
#============================================================
from headm import * # =
import paddle
import paddle.fluid as fluid
import cv2
#------------------------------------------------------------
imgwidth = 48
imgheight = 48
inputchannel = 1
kernelsize = 5
targetsize = 10
ftwidth = ((imgwidth-kernelsize+1)//2-kernelsize+1)//2
ftheight = ((imgheight-kernelsize+1)//2-kernelsize+1)//2
class lenet(paddle.nn.Layer):
def __init__(self, ):
super(lenet, self).__init__()
self.conv1 = paddle.nn.Conv2D(in_channels=inputchannel, out_channels=6, kernel_size=kernelsize, stride=1, padding=0)
self.conv2 = paddle.nn.Conv2D(in_channels=6, out_channels=16, kernel_size=kernelsize, stride=1, padding=0)
self.mp1 = paddle.nn.MaxPool2D(kernel_size=2, stride=2)
self.mp2 = paddle.nn.MaxPool2D(kernel_size=2, stride=2)
self.L1 = paddle.nn.Linear(in_features=ftwidth*ftheight*16, out_features=120)
self.L2 = paddle.nn.Linear(in_features=120, out_features=86)
self.L3 = paddle.nn.Linear(in_features=86, out_features=targetsize)
def forward(self, x):
x = self.conv1(x)
x = paddle.nn.functional.relu(x)
x = self.mp1(x)
x = self.conv2(x)
x = paddle.nn.functional.relu(x)
x = self.mp2(x)
x = paddle.flatten(x, start_axis=1, stop_axis=-1)
x = self.L1(x)
x = paddle.nn.functional.relu(x)
# x = paddle.fluid.layers.dropout(x, 0.2)
x = self.L2(x)
x = paddle.nn.functional.relu(x)
x = self.L3(x)
return x
model = lenet()
model.set_state_dict(paddle.load('/home/aistudio/work/seg7model4_1_all.pdparams'))
#------------------------------------------------------------
OUT_SIZE = 48
def scanimg1d(imgfile, scanStep):
img = cv2.imread(imgfile)
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
imgwidth = gray.shape[1]
imgheight = gray.shape[0]
imgarray = []
blockwidth = int(imgheight * .5)
startid = linspace(0, imgwidth-blockwidth, scanStep)
for s in startid:
left = int(s)
right = int(s+blockwidth)
data = gray[0:imgheightC# 扫描识别图片中的文字(.NET Framework)