wps的pdf扫描识别异常是啥原因
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了wps的pdf扫描识别异常是啥原因相关的知识,希望对你有一定的参考价值。
参考技术A 打开WPS文字,找到菜单栏最后一项“特色功能”一栏,就可以看到“图片转文字”这一功能选项。点击选项,就会打开金山OCR文字识别页面,并弹出选择窗口,可选取扫描文件、图片和PDF三种文件进行文字读取。
导入PDF文件,点击“纸面解析”选择要进行文字转换的区域。“纸面解析”有两种选项,“全部页面”是解析整个文件的文字区域;“当前页面”是解析当前页面的文字区域,还可以鼠标右键调整选区。
进行纸面解析,即分析文字转换区域后。点击“识别”,有两种选项,“全部页面”是识别整个文件的文字区域;“当前页面”是识别当前页面选定的文字区域。
转换后的文字可能会出现识别错误的情况,不确定的文字会显示红色,可进行手动更正。
Adobe Acrobat 9 Pro没有OCR文本识别功能是啥原因
参考技术A里面可以就不带ocr文字识别功能;
楼主,要想使用ocr文字识别功能,试一试下面的方法,希望可以帮助到您!
第一:打开cor文字识别软件,关闭提示窗口;
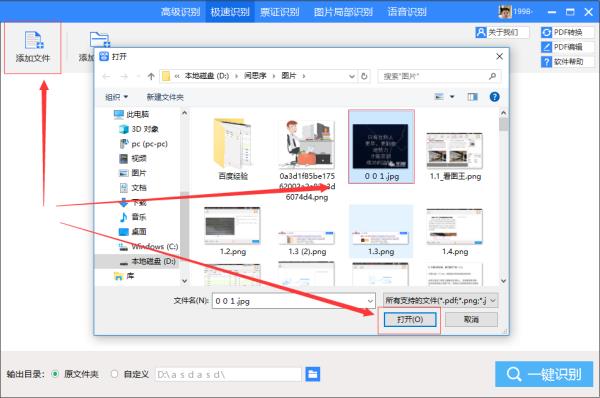
第二:同过左上角的添加文件按钮,将需要识别的文字文件添加进去;
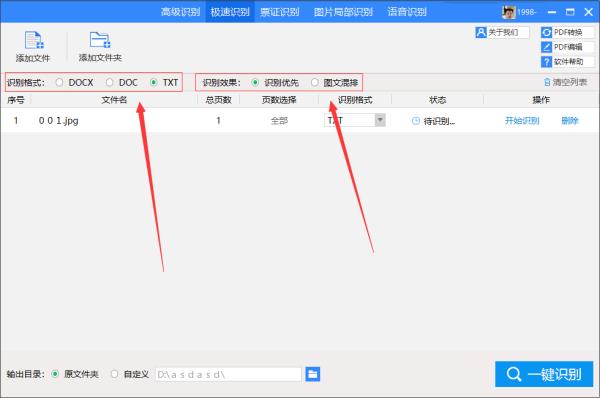
第三:在上面选择文件的识别格式和识别效果;
第四:点击操作下面的开始识别按钮,开始进行ocr文本识别。
以上是关于wps的pdf扫描识别异常是啥原因的主要内容,如果未能解决你的问题,请参考以下文章