什么是Oracle索引扫描的批量回表操作?
Posted bisal
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了什么是Oracle索引扫描的批量回表操作?相关的知识,希望对你有一定的参考价值。
我们知道,优化器是关系型数据库SQL执行的关键,决定了执行路径和效率。Oracle的优化器,随着不同版本,同样做着演进。
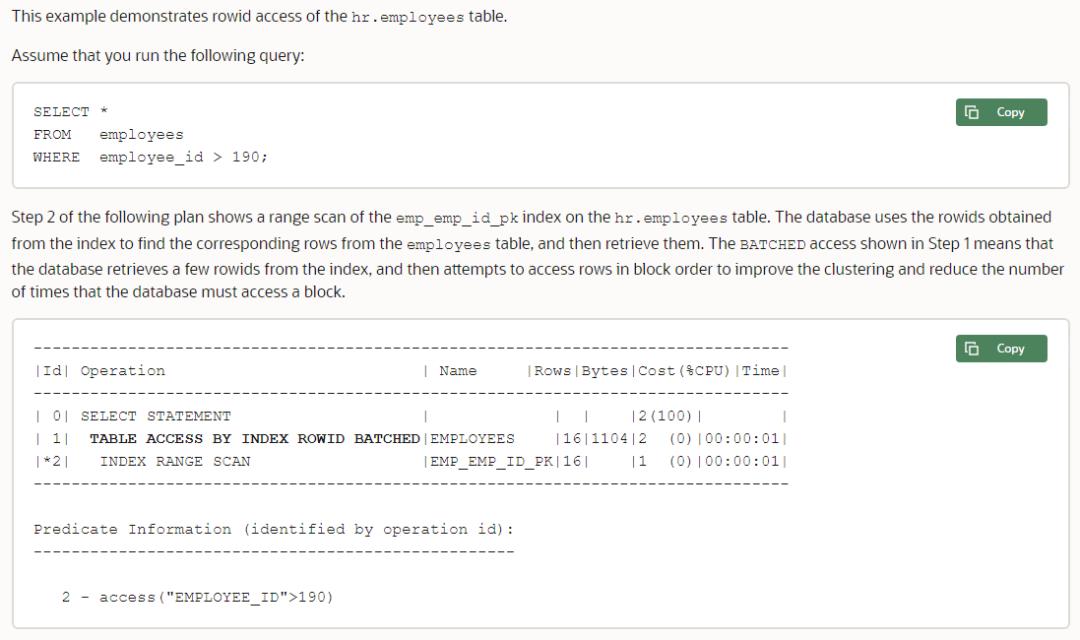
举个例子,细心的朋友可能注意过,12c以前通过索引扫描回表的时候,执行计划显示的通常是"TABLE ACCESS BY INDEX ROWID",但是从12c开始,索引扫描回表,显示的是"TABLE ACCESS BY INDEX ROWID BATCHED"。
索引扫描回表,意思就是根据索引字段进行检索,但是需要的数据不全在索引中,就需要根据索引叶子节点中存储的rowid(他可以定位一条记录的物理位置),回到表中,找到这些数据,返回给客户端。
P. S. rowid可以参考《什么是rowid?》。
官方文档《SQL Tuning Guide》中介绍了下,大致意思是数据库会提取一些rowid,然后按照块中存储的顺序访问数据,以此提高聚类,降低数据库必须访问一个数据块的次数,
P. S.
https://docs.oracle.com/en/database/oracle/oracle-database/19/tgsql/optimizer-access-paths.html#GUID-7A2735CC-278A-44AE-A643-670EC859466F
翻译略显生硬,再尝试解释下,12c之前,通过索引扫描,找到rowid,然后进行回表,但是此时回表,不一定是有序的,举个例子,
(1) 索引扫描返回需要回表的第一个记录rowid,假设对应到第一个数据文件、第一个数据块、第一行的数据。
(2) 索引扫描返回需要回表的第二个记录rowid,可能对应到第二个数据文件、第二个数据块、第二行的数据。
(3) 索引扫描返回需要回表的第三个记录rowid,可能对应到第三个数据文件、第三个数据块、第三行的数据。
(4) 索引扫描返回需要回表的第四个记录rowid,假设对应到第一个数据文件、第一个数据块、第二行的数据。
(5) 索引扫描返回需要回表的第五个记录rowid,可能对应到第二个数据文件、第三个数据块、第一行的数据。
(6) 索引扫描返回需要回表的第六个记录rowid,可能对应到第一个数据文件、第一个数据块、第三行的数据。
...
如果数据库比较繁忙,或者缓存配置较小,很可能操作(1)通过I/O读取到的数据块,在操作(4)和(6)还需要再I/O读取两次,增加了回表开销。
12c开始,"TABLE ACCESS BY INDEX ROWID BATCHED"中的batched,表示在回表时,Oracle会根据rowid排序,尽量按照顺序进行回表,好处就是如上述的例子,(1)、(4)、(6)的三次回表,可能要三次I/O,现在批量回表,可能只需要一次I/O,降低了物理读。
当然,一个新特性的出现很可能是两面的,bug在所难免,例如这个和batch相关的bug在20c以下都存在,
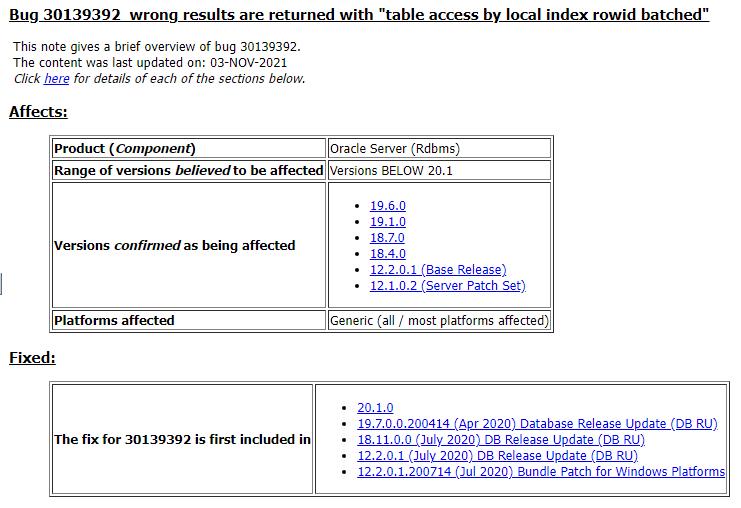
bug的触发条件,

对于任何新特性,Oracle都提供了开关,为的就是极端情况下能关闭或开启,这是我们在系统设计时,可以借鉴的一种操作。
是否启动索引批量回表,受隐藏参数控制,
_optimizer_batch_table_access_by_rowid
我们通过实验,看下batch效果,首先在19c的环境,默认开启batch,执行如下SQL,object_id是单键值的索引,根据索引范围扫描回表,可以看到,他采用了batch,进行的回表,物理读是161,
SQL> select /*+ gather_plan_statistcs */ owner, object_name, object_id from test where object_id >= 1000 and object_id < 10000;
SQL> select * from table(dbms_xplan.display_cursor(null, null, 'advanced -PROJECTION -bytes iostats'));
----------------------------------------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows | Cost (%CPU)| E-Time | A-Rows | A-Time | Buffers | Reads |
----------------------------------------------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | | 146 (100)| | 8979 |00:00:00.02 | 1404 | 161 |
| 1 | TABLE ACCESS BY INDEX ROWID BATCHED| TEST | 1 | 7880 | 146 (0)| 00:00:01 | 8979 |00:00:00.02 | 1404 | 161 |
|* 2 | INDEX RANGE SCAN | IDX_TEST_01 | 1 | 7880 | 16 (0)| 00:00:01 | 8979 |00:00:00.01 | 618 | 13 |
----------------------------------------------------------------------------------------------------------------------------------------------为了做对比,我们通过参数,关闭batch,
SQL> alter session set "_optimizer_batch_table_access_by_rowid" = false;
Session altered.清空一下buffer cache,避免缓存的影响,再执行SQL,
SQL> select /*+ gather_plan_statistcs */ owner, object_name, object_id from test where object_id >= 1000 and object_id < 10000;
SQL> select * from table(dbms_xplan.display_cursor(null, null, 'advanced -PROJECTION -bytes iostats'));
--------------------------------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Starts | E-Rows | Cost (%CPU)| E-Time | A-Rows | A-Time | Buffers | Reads |
--------------------------------------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | | 146 (100)| | 8979 |00:00:00.01 | 1417 | 180 |
| 1 | TABLE ACCESS BY INDEX ROWID| TEST | 1 | 7880 | 146 (0)| 00:00:01 | 8979 |00:00:00.01 | 1417 | 180 |
|* 2 | INDEX RANGE SCAN | IDX_TEST_01 | 1 | 7880 | 16 (0)| 00:00:01 | 8979 |00:00:00.01 | 618 | 20 |
--------------------------------------------------------------------------------------------------------------------------------------可以看到,回表操作,此时未显示batch了,物理读是180,和之前的batch相比,有所增加,但是不是很明显,这和数据分布可能是相关的,如果表中数据存储的比较分散,需要检索的数据越多,差异可能就会更加明显。
而且,为了做到batch批量,Oracle很可能需要做更多的事,例如排序,Cost没准会更高,还得具体情况,具体分析。
从这个知识点,确实能够看到,为了降低某些环节的消耗,Oracle的逻辑设计,不断调整、优化,很多点,值得我们在做系统设计时,借鉴一下。
近期更新的文章:
《降噪耳机的原理》
文章分类和索引:
以上是关于什么是Oracle索引扫描的批量回表操作?的主要内容,如果未能解决你的问题,请参考以下文章