SQL - MySQL回表
Posted MinggeQingchun
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了SQL - MySQL回表相关的知识,希望对你有一定的参考价值。
一、回表概念;现象
回表,顾名思义就是回到表中,也就是先通过普通索引(我们自己建的索引不管是单列索引还是联合索引,都称为普通索引)扫描出数据所在的行,再通过行主键ID 取出索引中未包含的数据。所以回表的产生也是需要一定条件的,如果一次索引查询就能获得所有的select 记录就不需要回表,如果select 所需获得列中有其他的非索引列,就会发生回表动作。即基于非主键索引的查询需要多扫描一棵索引树。
mysql回表指的是在InnoDB存储引擎下,二级索引查询到的索引列,如果需要查找所有列的数据,则需要到主键索引里面去取出数据。这个过程就称为回表。因为行的数据都是存在主键B+tree的叶子节点里面,二级索引的B+树叶子节点都是存放的(索引列,主键)
简单来说,回表就是 MySQL 要先查询到主键索引,然后再用主键索引定位到数据
回表现象
举个例子:
表tbl有a,b,c三个字段,其中 a是主键,b上建了索引,然后编写sql语句SELECT * FROM tbl WHERE a=1这样不会产生回表,因为所有的数据在a的索引树中均能找到
如果是SELECT * FROM tbl WHERE b=1这样就会产生回表,因为where条件是b字段,那么会去b的索引树里查找数据,但b的索引里面只有a,b两个字段的值,没有c,那么这个查询为了取到c字段,就要取出主键a的值,然后去a的索引树去找c字段的数据。查了两个索引树,就出现了回表操作
二、存储引擎;索引结构
要弄明白回表,首先得了解MySQL的存储引擎,以及默认存储引擎 InnoDB 的两大索引,即聚集索引 (clustered index)和 非聚簇索引/普通索引/二级索引/辅助索引(secondary index)
(一)存储引擎
MySQL中主要有2种存储引擎
1、MyISAM(不支持事物回滚)
MyIsam引擎是MySQL主流引擎之一,但它相比起InnoDB,没有提供对数据库事务的支持,不支持细粒度的锁(行锁)及外键,当表Insert与update时需要锁定整个表,因此效率会低一些,在高并发时可能会遇到瓶颈,但MyIsam引擎独立与操作系统,可以在windows及linux上使用。
可能的缺点:
不能在表损坏后恢复数据
适用场景:
1. MyIsam极度强调快速读取
2. MyIsam表中自动存储了表的行数,需要时直接获取即可
3. 适用于不需要事物支持、外键功能、及需要对整个表加锁的情形
2、InnoDB(支持事物回滚)
InnoDB是一个事务型存储引擎,提供了对数据库ACID事务的支持,并实现了SQL标准的四种隔离级别,具有行级锁定(这一点说明锁的粒度小,在写数据时,不需要锁住整个表,因此适用于高并发情形)及外键支持(所有数据库引擎中独一份,仅有它支持外键)
该引擎的设计目标便是处理大容量数据的数据库系统,MySQL在运行时InnoDB会在内存中建立缓冲池,用于缓存数据及索引。
可能的缺点:
1. 该引擎不支持FULLTEXT类型的索引
2. 没有保存表的行数,在执行select count(*) from 表名 时,需要遍历扫描全表
适用场景:
1. 经常需要更新的表,适合处理多重并发的更新请求
2. 支持事务
3. 外键约束
4. 可以从灾难中恢复(通过bin-log日志等)
5. 支持自动增加列属性auto_increment
show engines;show engines; 查看mysql所支持的存储引擎,以及从中得到mysql默认的存储引擎
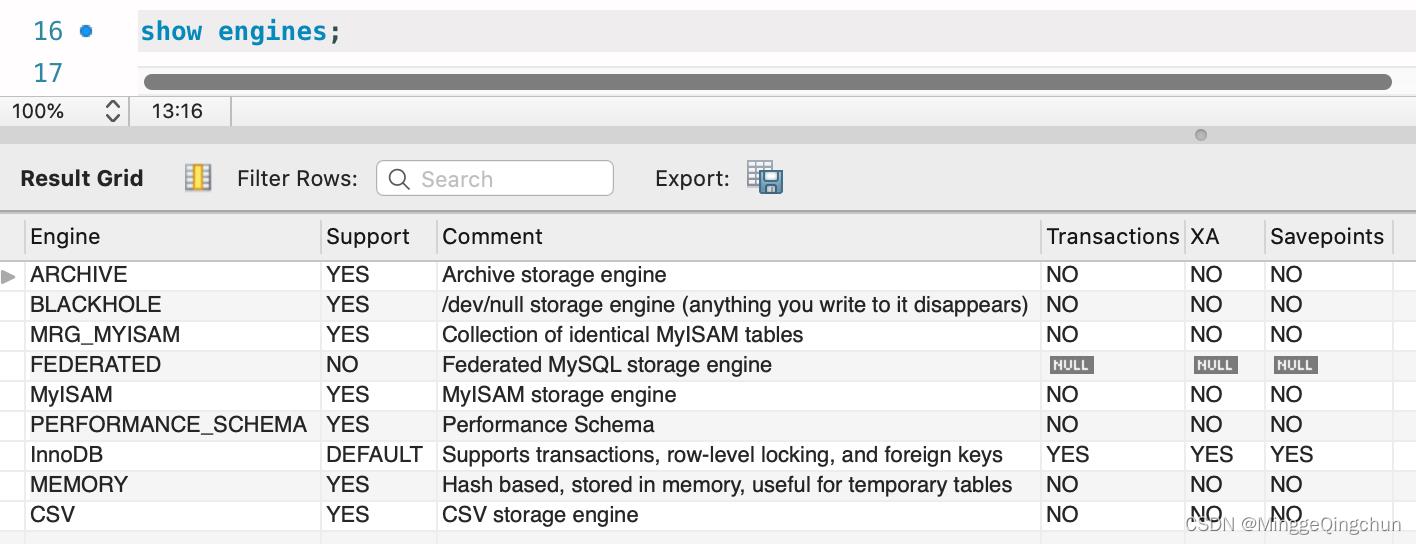
可以看出,MySQL默认的数据库引擎是InnoDB
| 参数名称 | 解释说明 |
|---|---|
| Engine | 存储引擎名称 |
| Support | 是否支持该引擎以及该引擎是否为默认存储引擎,YES表示支持,NO表示不支持 |
| DEFAULT | DEFAULT表示为默认存储引擎 |
| Comment | 存储引擎的简单介绍 |
| Transactions | 表示该引擎是否支持事务 |
| XA | 说明该存储引擎是否支持分布事务 |
| Savepoints | 说明该存储引擎是否支持部分事务回滚 |
(二)索引结构
MySQL官方对索引的定义为:索引(Index)是帮助MySQL高效获取数据的数据结构。可以得到索引的本质:索引是数据结构
MySQL默认的数据库引擎是InnoDB,InnoDB 存储引擎的两大索引,即聚集索引 (clustered index)和 非聚簇索引/普通索引/二级索引/辅助索引(secondary index)
1、聚集索引 (clustered index)
InnoDB聚集索引的叶子节点存储行记录,因此, InnoDB必须要有且只有一个聚集索引。
- 如果表定义了主键,则Primary Key 就是聚集索引;
- 如果表没有定义主键,则第一个非空唯一索引(Not NULL Unique)列是聚集索引
- 否则,InnoDB会创建一个隐藏的row-id作为聚集索引
简单来说,聚簇索引是主键索引
2、非聚簇索引/普通索引/二级索引/辅助索引(secondary index)
主键索引之外的就是非聚簇索引,非聚簇索引又叫辅助索引或者二级索引
主键索引 和 非主键索引区别
相同点:都使用的是 B+Tree
不同点:叶子节点存储的数据不同
主键索引的叶子节点存储的是一行完整的数据
非主键索引的叶子节点存储的是主键值。叶子节点不包含记录的全部数据,非主键的叶子节点除了用来排序的 key 还包含一个书签(bookmark),其中存储了聚簇索引的 key
使用主键索引查询
# 主键索引的的叶子节点存储的是**一行完整的数据**,
# 所以只需搜索主键索引的 B+Tree 就可以轻松找到全部数据
select * from user where id = 1;使用非主键索引查询
# 非主键索引的叶子节点存储的是**主键值**,
# 所以MySQL会先查询到 name 列的索引的 B+Tree,搜索得到对应的主键值
# 然后再去搜索该主键值查询主键索引的 B+Tree 才可以找到对应的数据
select * from user where name = 'Jack';使用非主键索引要比主键索引多使用一次 B+Tree
二级索引查找的过程为先在二级索引找到主键索引的key,再在主键索引中查找(回表操作)
InnoDB表一定要建主键,并且最好使用int自增作为主键
这样做就是为了不用MySQL维护唯一列数据,节省资源。建立和维护索引过程中需要进行key的比较,int类型更好比较。自增使得树结构不容易产生树结构分裂,更节省算力
1、单值索引
即一个索引只包含单个列,一个表可以有多个单列索引
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
|
2、唯一索引
索引列的值必须唯一,但允许有空值
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
|
3、主键索引
设定为主键后数据库会自动建立索引,innodb为聚簇索引
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
|
4、复合索引
即一个索引包含多个列
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
|
(三)B-Tree 和 B+Tree
理解聚簇索引和非聚簇索引的关键在于 B+Tree 的理解
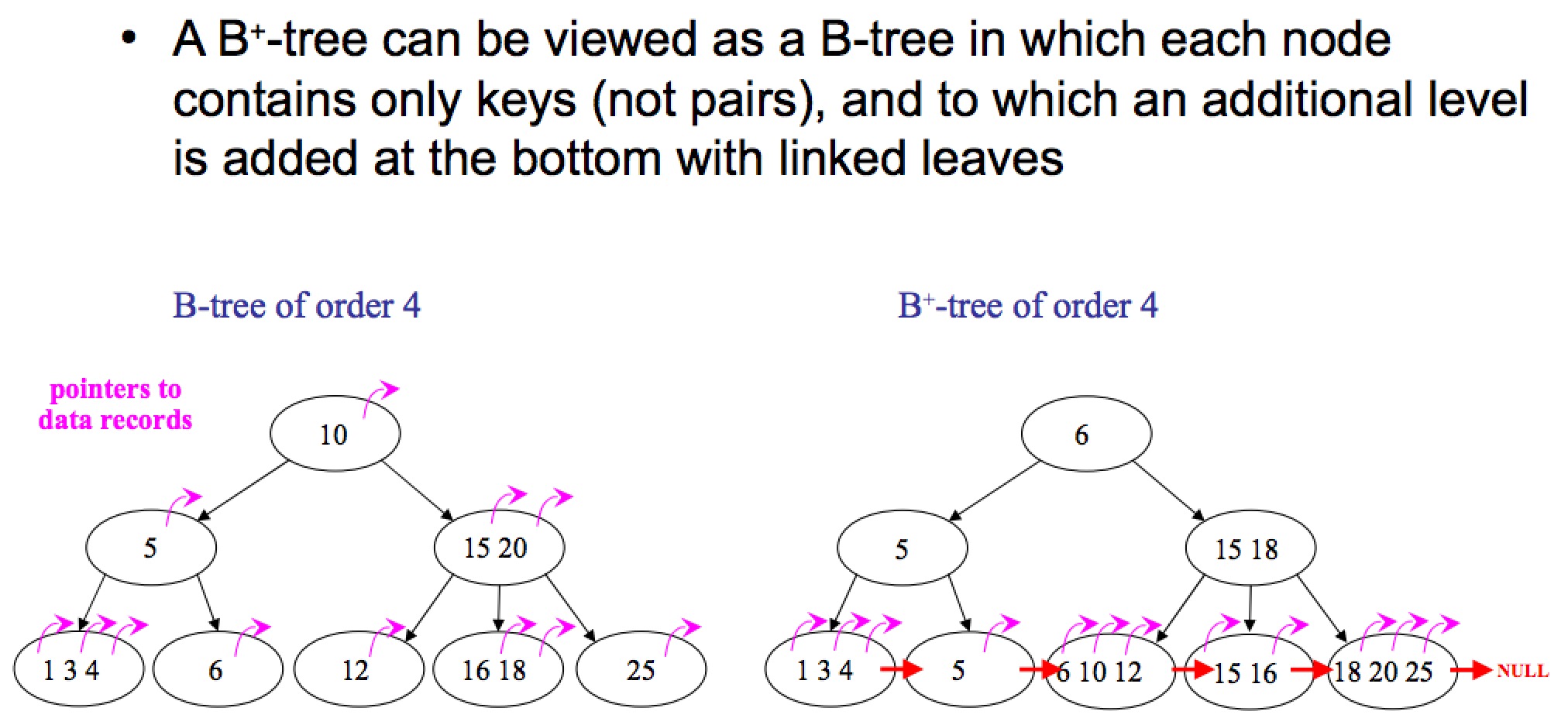
前者是 B-Tree,后者是 B+Tree,两者的区别在于:
-
B-Tree 中,所有节点都会带有指向具体记录的指针;B+Tree 中只有叶子结点会带有指向具体记录的指针。
-
B-Tree 中不同的叶子之间没有连在一起;B+Tree 中所有的叶子结点通过指针连接在一起。
-
B-Tree 中可能在非叶子结点就拿到了指向具体记录的指针,搜索效率不稳定;B+Tree 中,一定要到叶子结点中才可以获取到具体记录的指针,搜索效率稳定
基于上面两点分析,我们可以得出如下结论:
-
B+Tree 中,由于非叶子结点不带有指向具体记录的指针,所以非叶子结点中可以存储更多的索引项,这样就可以有效降低树的高度,进而提高搜索的效率。
-
B+Tree 中,叶子结点通过指针连接在一起,这样如果有范围扫描的需求,那么实现起来将非常容易,而对于 B-Tree,范围扫描则需要不停的在叶子结点和非叶子结点之间移动
三、索引创建场景
(一)需要创建索引
1、主键自动建立唯一索引
2、频繁作为查询条件的字段应该创建索引
3、查询中与其它表关联的字段,外键关系建立索引
4、单键/组合索引的选择问题, 组合索引性价比更高
5、查询中排序的字段,排序字段若通过索引去访问将大大提高排序速度
6、查询中统计或者分组字段
(二)不要创建索引
1、表记录太少
2、经常增删改的表或者字段 原因:提高了查询速度,同时却会降低更新表的速度,如对表进行INSERT、UPDATE和DELETE。因为更新表时,MySQL不仅要保存数据,还要保存一下索引文件
3、Where条件里用不到的字段不创建索引
4、过滤性不好的不适合建索引
四、覆盖索引避免回表
覆盖索引就是指索引中包含了查询中的所有字段,这种情况下就不需要再进行回表查询
一级索引:聚簇索引即主键索引
二级索引:非聚簇索引一级B+Tree:叶子节点保存着键(id的值)和数据(全部字段的值)
二级B+Tree:叶子节点保存着键(索引字段的值)和数据(主键索引值)查询 一级索引,根据一级B+Tree查询到数据,直接返回数据
查询 二级索引,根据二级B+Tree查询到对应的聚簇索引,再根据聚簇索引在一级B+Tree里查询到相应数据查询 一级索引只需要扫描一次B+Tree。
查询 二级索引需要扫描两次B+Tree。根据二级B+Tree扫描的结果,再去一级B+Tree里进行扫描就叫回表操作
如果使用组合索引,就可以利用覆盖索引避免回表操作
例:表一共有五个字段:a(主键索引),b_c_d(组合索引),e(没有索引)
如果用户查询时只查 b,c,d;SELECT `b`, `c`, `d` FROM `table` WHERE `b` = 3 AND `c` = 7 AND `d` = 5;
因为查询的字段 b,c,d的值(B+Tree里的键) 已经在B+Tree里了,所以就可以直接返回,不用再拿聚簇索引去一级B+Tree里进行查询
如果查询字段为 a,b,c,d,因为a为主键索引,也保存在二级B+Tree的叶子节点里,所以也不用回表查询
【a是主键,给bcd建立联合索引】,如上几个sql,select出来的内容,和where条件字段,刚好和建立的索引一致
如果查询字段为 a,b,c,d,e,因为e没有在这个二级B+Tree里,所以需要进行回表操作,拿着主键索引再去一级B+Tree里进行查询
使用覆盖索引,我们需要select出来的列,都已经存在了索引树的叶子节点上。所以不需要回表操作,如果我们select出来的某列,不在该联合索引的叶子节点上(比如上表的e列),那就需要根据对应索引值,去聚簇索引树上回表查询对应的e列值了
参考链接
什么是MySQL的回表?_一年春又来的博客-CSDN博客_回表
https://www.jb51.net/article/239235.htm
以上是关于SQL - MySQL回表的主要内容,如果未能解决你的问题,请参考以下文章