深度学习部署(十三): CUDA RunTime API thread_layout线程布局
Posted 智障学AI
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深度学习部署(十三): CUDA RunTime API thread_layout线程布局相关的知识,希望对你有一定的参考价值。
1. 知识点
-
在.vscode/settings.json中配置"*.cu": "cuda-cpp"可以实现对cuda的语法解析
-
layout是设置核函数执行的线程数,要明白最大值、block最大线程数、warpsize取值
- maxGridSize对应gridDim的取值最大值
- maxThreadsDim对应blockDim的取值最大值
- warpSize对应线程束中的线程数量
- maxThreadsPerBlock对应blockDim元素乘积最大值
-
layout的4个主要变量的关系
- gridDim是layout维度,其对应的索引是blockIdx
- blockIdx的最大值是0到gridDim-1
- blockDim是layout维度,其对应的索引是threadIdx
- threadIdx的最大值是0到blockDim-1
- blockDim维度乘积必须小于等于maxThreadsPerBlock
- 所以称gridDim、blockDim为维度,启动核函数后是固定的
- 所以称blockIdx、threadIdx为索引,启动核函数后,枚举每一个维度值,不同线程取值不同
- 关于线程束带概念这里不讲,可以自行查询
- gridDim是layout维度,其对应的索引是blockIdx
-
核函数启动时,<<<>>>的参数分别为:<<<gridDim, blockDim, shraed_memory_size, cudaStream_t>>>
- shared_memory_size请看后面关于shared memory的讲解,配置动态的shared memory大小
2. 图解知识点
.1 如何理解layout是设置核函数执行的线程数,要明白最大值、block最大线程数、warpsize取值?
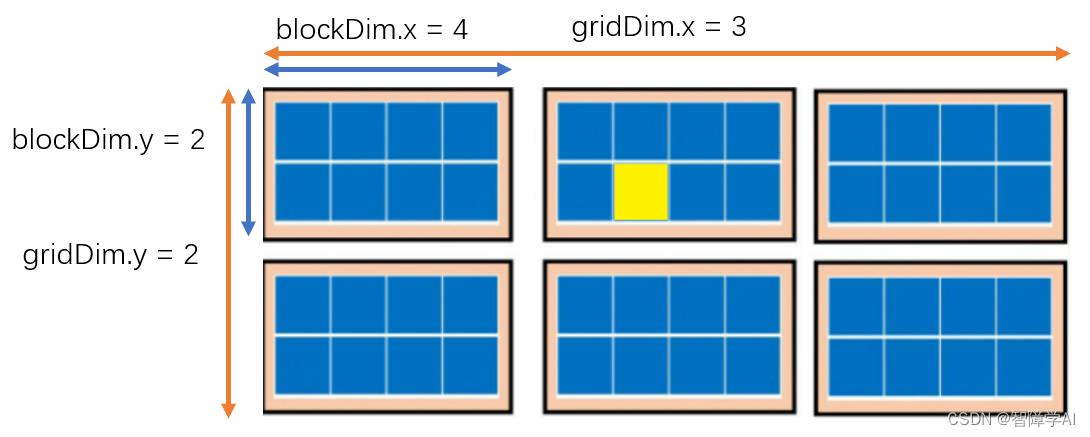
layout就是一个一个grid,每个block里面有一堆的block, block里面放的是thread
Warp size指的是GPU中一个线程束内包含的线程数量,同时也是最小的调度单元,即GPU会将同一个warp中的线程一起调度,以便实现并行计算。
- 如果我这个GPU的warp size = 32, 最小的调度单元是32个线程是吗?
是的,每个SM内部的所有线程都被划分为以warp size为大小的warp,每个warp内的线程并行执行,并且最小的调度单元是一个warp,即32个线程。如果某个warp中的线程出现了分支或者条件语句,这些线程将会被分成不同的warp分别执行,这可能会导致性能下降。因此,尽量避免分支和条件语句可以提高GPU的执行效率。
- 案例计算:
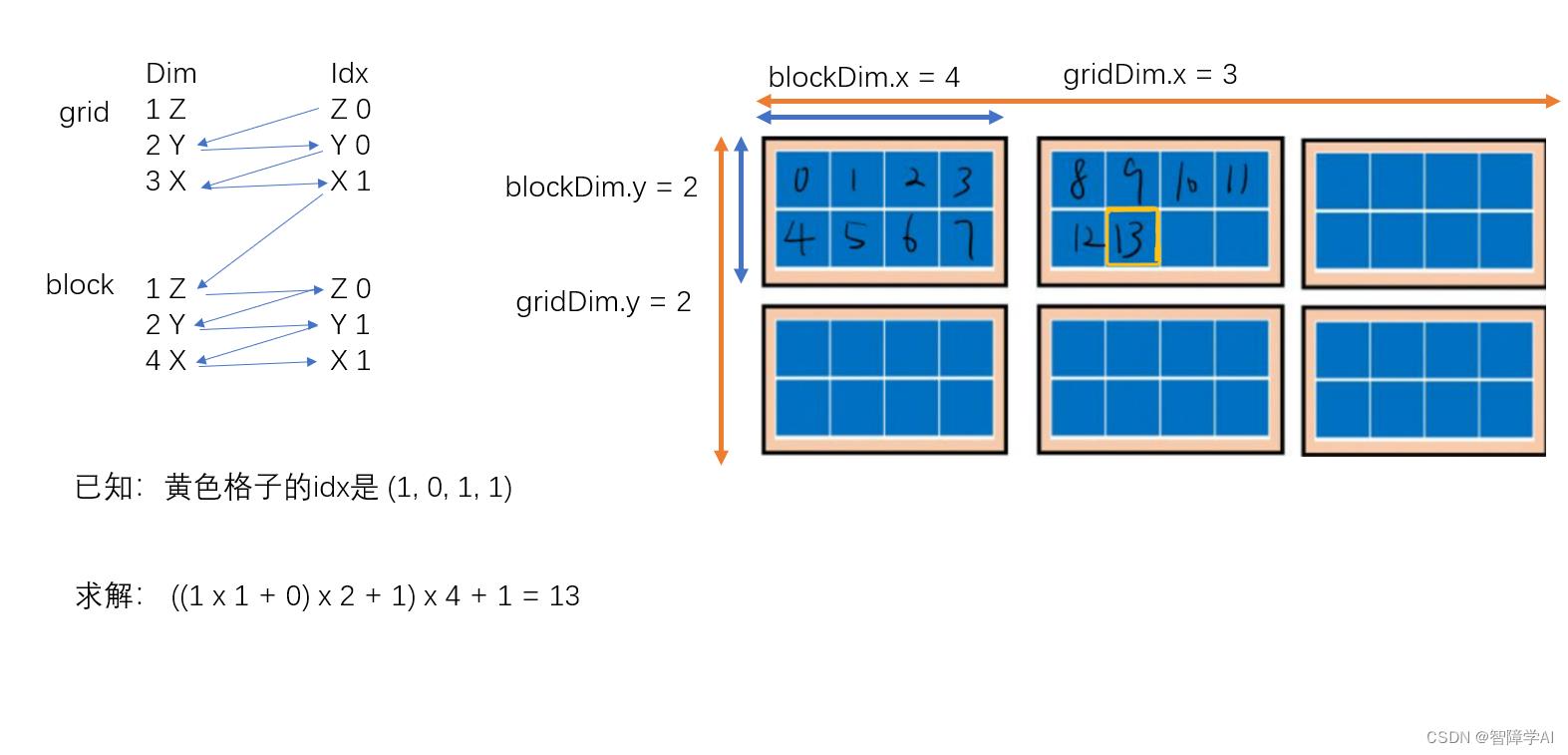
这个案例里面的layout
- girdDim.x = 3
- gridDim.y = 2
- gridDim.z = 1 (这里用的是默认值)
- blockDim.x = 4
- blockDim.y = 2
- blockDim.z = 1 (这里用的是默认值)
从上面把数字带进去计算就可以得到黄色格子是13了。
3. main.cpp文件
#include <cuda_runtime.h>
#include <stdio.h>
#define checkRuntime(op) __check_cuda_runtime((op), #op, __FILE__, __LINE__)
bool __check_cuda_runtime(cudaError_t code, const char* op, const char* file, int line)
if(code != cudaSuccess)
const char* err_name = cudaGetErrorName(code);
const char* err_message = cudaGetErrorString(code);
printf("runtime error %s:%d %s failed. \\n code = %s, message = %s\\n", file, line, op, err_name, err_message);
return false;
return true;
void launch(int* grids, int* blocks);
int main()
cudaDeviceProp prop;
checkRuntime(cudaGetDeviceProperties(&prop, 0));
// 通过查询maxGridSize和maxThreadsDim参数,得知能够设计的gridDims、blockDims的最大值
// warpSize则是线程束的线程数量
// maxThreadsPerBlock则是一个block中能够容纳的最大线程数,也就是说blockDims[0] * blockDims[1] * blockDims[2] <= maxThreadsPerBlock
printf("prop.maxGridSize = %d, %d, %d\\n", prop.maxGridSize[0], prop.maxGridSize[1], prop.maxGridSize[2]);
printf("prop.maxThreadsDim = %d, %d, %d\\n", prop.maxThreadsDim[0], prop.maxThreadsDim[1], prop.maxThreadsDim[2]);
printf("prop.warpSize = %d\\n", prop.warpSize);
printf("prop.maxThreadsPerBlock = %d\\n", prop.maxThreadsPerBlock);
int grids[] = 1, 2, 3; // gridDim.x gridDim.y gridDim.z
int blocks[] = 1024, 1, 1; // blockDim.x blockDim.y blockDim.z
// launch(grids, blocks); // grids表示的是有几个大格子,blocks表示的是每个大格子里面有多少个小格子
checkRuntime(cudaPeekAtLastError()); // 获取错误 code 但不清楚error
checkRuntime(cudaDeviceSynchronize()); // 进行同步,这句话以上的代码全部可以异步操作
printf("done\\n");
return 0;
4. cu文件
#include <cuda_runtime.h>
#include <stdio.h>
__global__ void demo_kernel()
if(blockIdx.x == 0 && threadIdx.x == 0)
printf("Run kernel. blockIdx = %d,%d,%d threadIdx = %d,%d,%d\\n",
blockIdx.x, blockIdx.y, blockIdx.z,
threadIdx.x, threadIdx.y, threadIdx.z
);
void launch(int* grids, int* blocks)
dim3 grid_dims(grids[0], grids[1], grids[2]);
dim3 block_dims(blocks[0], blocks[1], blocks[2]);
demo_kernel<<<grid_dims, block_dims, 0, nullptr>>>();
5. 代码拆解
void search_demo()
// 定义一个结构体用来储存设备信息
// 返回一个指向0号设备的指针, 如果写1号设备但是没有,checkRuntime会报错
cudaDeviceProp prop;
checkRuntime(cudaGetDeviceProperties(&prop, 0));
// 查询maxGrid的数量,也是看每一个维度能放多少个block
printf("prop.maxGridSize = %d, %d, %d\\n", prop.maxGridSize[0],
prop.maxGridSize[1], prop.maxGridSize[2]);
// 查询每一个block不同维度的最大线程数,看能放多少个线程
printf("prop.maxThreadsDim = %d, %d, %d\\n", prop.maxThreadsDim[0], prop.maxThreadsDim[1], prop.maxThreadsDim[2]);
// 查询warp size
printf("prop.warpSize = %d\\n", prop.warpSize);
printf("prop.maxThreadsPerBlock = %d\\n", prop.maxThreadsPerBlock);
prop.maxGridSize = 2147483647, 65535, 65535
prop.maxThreadsDim = 1024, 1024, 64
prop.warpSize = 32
prop.maxThreadsPerBlock = 1024
定义一个结构体用来储存设备信息
返回一个指向0号设备的指针, 如果写1号设备但是没有,checkRuntime会报错
查询maxGrid的数量,也是看每一个维度能放多少个block
查询每一个block不同维度的最大线程数,看能放多少个线程
查询warp size
6. cu文件解读
调用在main.cpp文件里面
main.cpp
int main()
search_demo(); // 查询设备信息,可以通过查询设备信息了解到
// 布局的demo, 定义布局
int grids[] = 1, 2, 3; // girdDim.x, gridDim.y, gridDim.z
int blocks[] = 1024, 1, 1; // blockDim.x, blockDim.y, blockDim.z
launch(grids, blocks); // grids表示的是有几个大格子,blocks表示的是每个大格子里面有多少个小格子
checkRuntime(cudaPeekAtLastError()); // 获取错误 code 但不清楚error
checkRuntime(cudaDeviceSynchronize()); // 进行同步,这句话以上的代码全部可以异步操作
return 0;
.cu
#include <cuda_runtime.h>
#include <stdio.h>
__global__ void demo_kernel()
// 这个案例是去每一个grid里面的第一个block, 第一个block的第一个线程输出信息
// 因为block是grid的索引,thread是block的索引
if (blockIdx.x == 0 && threadIdx.x == 0)
printf("Run kernel. blockIdx = %d,%d,%d threadIdx = %d,%d,%d\\n",
blockIdx.x, blockIdx.y, blockIdx.z,
threadIdx.x, threadIdx.y, threadIdx.z);
void launch(int* grids, int* blocks)
dim3 gird_dims(grids[0], grids[1], grids[2]);
dim3 blocks_dims(blocks[0], blocks[1], blocks[2]);
demo_kernel<<<gird_dims, blocks_dims, 0, nullptr>>>();
prop.maxGridSize = 2147483647, 65535, 65535
prop.maxThreadsDim = 1024, 1024, 64
prop.warpSize = 32
prop.maxThreadsPerBlock = 1024
Run kernel. blockIdx = 0,0,1 threadIdx = 0,0,0
Run kernel. blockIdx = 0,1,2 threadIdx = 0,0,0
Run kernel. blockIdx = 0,1,1 threadIdx = 0,0,0
Run kernel. blockIdx = 0,0,2 threadIdx = 0,0,0
Run kernel. blockIdx = 0,0,0 threadIdx = 0,0,0
Run kernel. blockIdx = 0,1,0 threadIdx = 0,0,0
这里的 launch 函数中 blocks[0] 为 1024,其它两个维度为 1,表示一个 block 中有 1024 个线程。grids 数组表示了整个网格的大小,其中 grids[0] 表示 x 方向上有 1 个 block,grids[1] 表示 y 方向上有 2 个 block,grids[2] 表示 z 方向上有 3 个 block。因此,总共有 6 个 block,每个 block 有 1024 个线程,所以总共有 6144 个线程。
demo_kernel()
这个案例是去每一个grid里面的第一个block, 第一个block的第一个线程输出信息
因为block是grid的索引,thread是block的索引
以上是关于深度学习部署(十三): CUDA RunTime API thread_layout线程布局的主要内容,如果未能解决你的问题,请参考以下文章
Ubuntu 18.04.2深度学习cuda 10.2环境部署
Ubuntu 18.04.2深度学习cuda 10.2环境部署