如何用Python做爬虫
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何用Python做爬虫相关的知识,希望对你有一定的参考价值。
1)首先你要明白爬虫怎样工作。想象你是一只蜘蛛,现在你被放到了互联“网”上。那么,你需要把所有的网页都看一遍。怎么办呢?没问题呀,你就随便从某个地方开始,比如说人民日报的首页,这个叫initial pages,用$表示吧。
在人民日报的首页,你看到那个页面引向的各种链接。于是你很开心地从爬到了“国内新闻”那个页面。太好了,这样你就已经爬完了俩页面(首页和国内新闻)!暂且不用管爬下来的页面怎么处理的,你就想象你把这个页面完完整整抄成了个html放到了你身上。
突然你发现, 在国内新闻这个页面上,有一个链接链回“首页”。作为一只聪明的蜘蛛,你肯定知道你不用爬回去的吧,因为你已经看过了啊。所以,你需要用你的脑子,存下你已经看过的页面地址。这样,每次看到一个可能需要爬的新链接,你就先查查你脑子里是不是已经去过这个页面地址。如果去过,那就别去了。
好的,理论上如果所有的页面可以从initial page达到的话,那么可以证明你一定可以爬完所有的网页。
那么在python里怎么实现呢?
很简单
import Queue
initial_page = "初始化页"
url_queue = Queue.Queue()
seen = set()
seen.insert(initial_page)
url_queue.put(initial_page)
while(True): #一直进行直到海枯石烂
if url_queue.size()>0:
current_url = url_queue.get() #拿出队例中第一个的url
store(current_url) #把这个url代表的网页存储好
for next_url in extract_urls(current_url): #提取把这个url里链向的url
if next_url not in seen:
seen.put(next_url)
url_queue.put(next_url)
else:
break
写得已经很伪代码了。
所有的爬虫的backbone都在这里,下面分析一下为什么爬虫事实上是个非常复杂的东西——搜索引擎公司通常有一整个团队来维护和开发。
2)效率
如果你直接加工一下上面的代码直接运行的话,你需要一整年才能爬下整个豆瓣的内容。更别说Google这样的搜索引擎需要爬下全网的内容了。
问题出在哪呢?需要爬的网页实在太多太多了,而上面的代码太慢太慢了。设想全网有N个网站,那么分析一下判重的复杂度就是N*log(N),因为所有网页要遍历一次,而每次判重用set的话需要log(N)的复杂度。OK,OK,我知道python的set实现是hash——不过这样还是太慢了,至少内存使用效率不高。
通常的判重做法是怎样呢?Bloom Filter. 简单讲它仍然是一种hash的方法,但是它的特点是,它可以使用固定的内存(不随url的数量而增长)以O(1)的效率判定url是否已经在set中。可惜天下没有白吃的午餐,它的唯一问题在于,如果这个url不在set中,BF可以100%确定这个url没有看过。但是如果这个url在set中,它会告诉你:这个url应该已经出现过,不过我有2%的不确定性。注意这里的不确定性在你分配的内存足够大的时候,可以变得很小很少。一个简单的教程:Bloom Filters by Example
注意到这个特点,url如果被看过,那么可能以小概率重复看一看(没关系,多看看不会累死)。但是如果没被看过,一定会被看一下(这个很重要,不然我们就要漏掉一些网页了!)。 [IMPORTANT: 此段有问题,请暂时略过]
好,现在已经接近处理判重最快的方法了。另外一个瓶颈——你只有一台机器。不管你的带宽有多大,只要你的机器下载网页的速度是瓶颈的话,那么你只有加快这个速度。用一台机子不够的话——用很多台吧!当然,我们假设每台机子都已经进了最大的效率——使用多线程(python的话,多进程吧)。
3)集群化抓取
爬取豆瓣的时候,我总共用了100多台机器昼夜不停地运行了一个月。想象如果只用一台机子你就得运行100个月了...
那么,假设你现在有100台机器可以用,怎么用python实现一个分布式的爬取算法呢?
我们把这100台中的99台运算能力较小的机器叫作slave,另外一台较大的机器叫作master,那么回顾上面代码中的url_queue,如果我们能把这个queue放到这台master机器上,所有的slave都可以通过网络跟master联通,每当一个slave完成下载一个网页,就向master请求一个新的网页来抓取。而每次slave新抓到一个网页,就把这个网页上所有的链接送到master的queue里去。同样,bloom filter也放到master上,但是现在master只发送确定没有被访问过的url给slave。Bloom Filter放到master的内存里,而被访问过的url放到运行在master上的Redis里,这样保证所有操作都是O(1)。(至少平摊是O(1),Redis的访问效率见:LINSERT – Redis)
考虑如何用python实现:
在各台slave上装好scrapy,那么各台机子就变成了一台有抓取能力的slave,在master上装好Redis和rq用作分布式队列。
代码于是写成
#slave.py
current_url = request_from_master()
to_send = []
for next_url in extract_urls(current_url):
to_send.append(next_url)
store(current_url);
send_to_master(to_send)
#master.py
distributed_queue = DistributedQueue()
bf = BloomFilter()
initial_pages = "www.renmingribao.com"
while(True):
if request == \'GET\':
if distributed_queue.size()>0:
send(distributed_queue.get())
else:
break
elif request == \'POST\':
bf.put(request.url)
好的,其实你能想到,有人已经给你写好了你需要的:darkrho/scrapy-redis · GitHub
4)展望及后处理
虽然上面用很多“简单”,但是真正要实现一个商业规模可用的爬虫并不是一件容易的事。上面的代码用来爬一个整体的网站几乎没有太大的问题。
但是如果附加上你需要这些后续处理,比如
有效地存储(数据库应该怎样安排)
有效地判重(这里指网页判重,咱可不想把人民日报和抄袭它的大民日报都爬一遍)
有效地信息抽取(比如怎么样抽取出网页上所有的地址抽取出来,“朝阳区奋进路中华道”),搜索引擎通常不需要存储所有的信息,比如图片我存来干嘛...
及时更新(预测这个网页多久会更新一次)
如你所想,这里每一个点都可以供很多研究者十数年的研究。虽然如此,
“路漫漫其修远兮,吾将上下而求索”。
所以,不要问怎么入门,直接上路就好了:) 参考技术A
在我们日常上网浏览网页的时候,经常会看到一些好看的图片,我们就希望把这些图片保存下载,或者用户用来做桌面壁纸,或者用来做设计的素材。
我们最常规的做法就是通过鼠标右键,选择另存为。但有些图片鼠标右键的时候并没有另存为选项,还有办法就通过就是通过截图工具截取下来,但这样就降低图片的清晰度。好吧其实你很厉害的,右键查看页面源代码。
我们可以通过python 来实现这样一个简单的爬虫功能,把我们想要的代码爬取到本地。下面就看看如何使用python来实现这样一个功能。
具体步骤
获取整个页面数据首先我们可以先获取要下载图片的整个页面信息。
getjpg.py
#coding=utf-8import urllibdef getHtml(url):
page = urllib.urlopen(url)
html = page.read() return html
html = getHtml("http://tieba.baidu.com/p/2738151262")print html
Urllib 模块提供了读取web页面数据的接口,我们可以像读取本地文件一样读取www和ftp上的数据。首先,我们定义了一个getHtml()函数:
urllib.urlopen()方法用于打开一个URL地址。
read()方法用于读取URL上的数据,向getHtml()函数传递一个网址,并把整个页面下载下来。执行程序就会把整个网页打印输出。
2.筛选页面中想要的数据
Python 提供了非常强大的正则表达式,我们需要先要了解一点python 正则表达式的知识才行。
http://www.cnblogs.com/fnng/archive/2013/05/20/3089816.html
假如我们百度贴吧找到了几张漂亮的壁纸,通过到前段查看工具。找到了图片的地址,如:src=”http://imgsrc.baidu.com/forum......jpg”pic_ext=”jpeg”
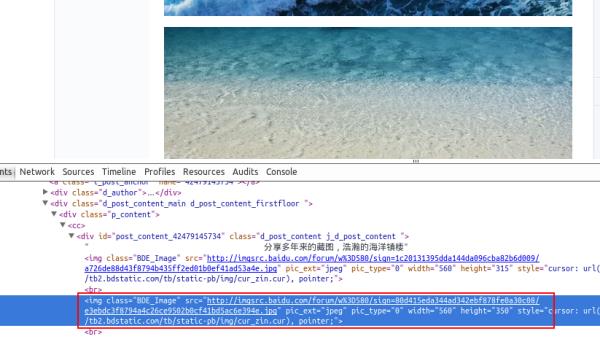
修改代码如下:
import reimport urllibdef getHtml(url):
page = urllib.urlopen(url)
html = page.read() return htmldef getImg(html):
reg = r'src="(.+?\\.jpg)" pic_ext'
imgre = re.compile(reg)
imglist = re.findall(imgre,html) return imglist
html = getHtml("http://tieba.baidu.com/p/2460150866")print getImg(html)
我们又创建了getImg()函数,用于在获取的整个页面中筛选需要的图片连接。re模块主要包含了正则表达式:
re.compile() 可以把正则表达式编译成一个正则表达式对象.
re.findall() 方法读取html 中包含 imgre(正则表达式)的数据。
运行脚本将得到整个页面中包含图片的URL地址。
3.将页面筛选的数据保存到本地
把筛选的图片地址通过for循环遍历并保存到本地,代码如下:
#coding=utf-8import urllibimport redef getHtml(url):
page = urllib.urlopen(url)
html = page.read() return htmldef getImg(html):
reg = r'src="(.+?\\.jpg)" pic_ext'
imgre = re.compile(reg)
imglist = re.findall(imgre,html)
x = 0 for imgurl in imglist:
urllib.urlretrieve(imgurl,'%s.jpg' % x)
x+=1html = getHtml("http://tieba.baidu.com/p/2460150866")print getImg(html)
这里的核心是用到了urllib.urlretrieve()方法,直接将远程数据下载到本地。
通过一个for循环对获取的图片连接进行遍历,为了使图片的文件名看上去更规范,对其进行重命名,命名规则通过x变量加1。保存的位置默认为程序的存放目录。
程序运行完成,将在目录下看到下载到本地的文件。
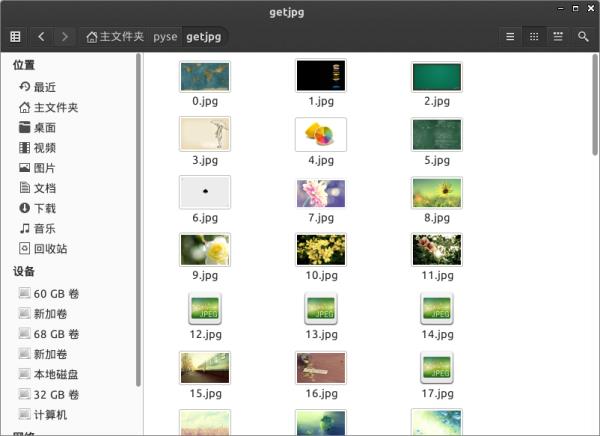
链接:https://pan.baidu.com/s/1wMgTx-M-Ea9y1IYn-UTZaA

课程简介
毕业不知如何就业?工作效率低经常挨骂?很多次想学编程都没有学会?
Python 实战:四周实现爬虫系统,无需编程基础,二十八天掌握一项谋生技能。
带你学到如何从网上批量获得几十万数据,如何处理海量大数据,数据可视化及网站制作。
课程目录
开始之前,魔力手册 for 实战学员预习
第一周:学会爬取网页信息
第二周:学会爬取大规模数据
第三周:数据统计与分析
第四周:搭建 Django 数据可视化网站
......
参考技术C :从爬虫必要的几个基本需求来讲: 1.抓取 py的urllib不一定去用,但是要学,如果还没用过的话。 比较好的替代品有requests等第三方更人性化、成熟的库,如果pyer不了解各种库,那就白学了。 抓取最基本就是拉网页回来。 如果深入做下去,会发现要... 参考技术D 完整示例http://blog.csdn.net/tangdou5682/article/details/52596863
以上是关于如何用Python做爬虫的主要内容,如果未能解决你的问题,请参考以下文章
python爬虫技术如何挣钱?手把手教你如何用Python做副业月入30000+!