Webpack 有非常多的概念,很多名词长得都差不多。我把这些分散在文档和教程里的内容总结起来,写了一份 webpack 中的易混淆知识点,目前看是全网独一份,大家可以加个收藏,方便以后检索和学习。
全集链接 ➡️ webpack 易混淆知识点
首先来个背景介绍,哈希一般是结合 CDN 缓存来使用的。如果文件内容改变的话,那么对应文件哈希值也会改变,对应的 html 引用的 URL 地址也会改变,触发 CDN 服务器从源服务器上拉取对应数据,进而更新本地缓存。
4.1 hash
hash 计算是跟整个项目的构建相关,我们做一个简单的 demo。
沿用案例 1 的 demo 代码,文件目录如下:
src/
├── index.css
├── index.html
├── index.js
└── utils.js
webpack 的核心配置如下(省略了一些 module 配置信息):
{
entry: {
index: "../src/index.js",
utils: \'../src/utils.js\',
},
output: {
filename: "[name].[hash].js", // 改为 hash
},
......
plugins: [
new MiniCssExtractPlugin({
filename: \'index.[hash].css\' // 改为 hash
}),
]
}
生成的文件名如下:
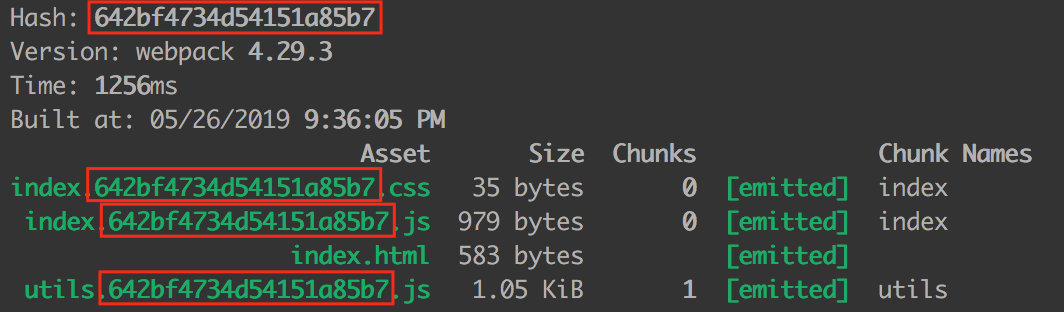
我们可以发现,生成文件的 hash 和项目的构建 hash 都是一模一样的。
4.2 chunkhash
因为 hash 是项目构建的哈希值,项目中如果有些变动,hash 一定会变,比如说我改动了 utils.js 的代码,index.js 里的代码虽然没有改变,但是大家都是用的同一份 hash。hash 一变,缓存一定失效了,这样子是没办法实现 CDN 和浏览器缓存的。
chunkhash 就是解决这个问题的,它根据不同的入口文件(Entry)进行依赖文件解析、构建对应的 chunk,生成对应的哈希值。
我们再举个例子,我们对 utils.js 里文件进行改动:
export function square(x) {
return x * x;
}
// 增加 cube() 求立方函数
export function cube(x) {
return x * x * x;
}
然后把 webpack 里的所有 hash 改为 chunkhash:
{
entry: {
index: "../src/index.js",
utils: \'../src/utils.js\',
},
output: {
filename: "[name].[chunkhash].js", // 改为 chunkhash
},
......
plugins: [
new MiniCssExtractPlugin({
filename: \'index.[chunkhash].css\' // // 改为 chunkhash
}),
]
}
构建结果如下:

我们可以看出,chunk 0 的 hash 都是一样的,chunk 1 的 hash 和上面的不一样。
假设我又把 utils.js 里的 cube() 函数去掉,再打包:

对比可以发现,只有 chunk 1 的 hash 发生变化,chunk 0 的 hash 还是原来的。
4.3 contenthash
我们更近一步,index.js 和 index.css 同为一个 chunk,如果 index.js 内容发生变化,但是 index.css 没有变化,打包后他们的 hash 都发生变化,这对 css 文件来说是一种浪费。如何解决这个问题呢?
contenthash 将根据资源内容创建出唯一 hash,也就是说文件内容不变,hash 就不变。
我们修改一下 webpack 的配置:
{
entry: {
index: "../src/index.js",
utils: \'../src/utils.js\',
},
output: {
filename: "[name].[chunkhash].js",
},
......
plugins: [
new MiniCssExtractPlugin({
filename: \'index.[contenthash].css\' // 这里改为 contenthash
}),
]
}
我们对 index.js 文件做了 3 次修改(就是改了改 log 函数的输出内容,过于简单就先不写了),然后分别构建,结果截图如下:



我们可以发现,css 文件的 hash 都没有发生改变。
4.4 一句话总结:
hash 计算与整个项目的构建相关;
chunkhash 计算与同一 chunk 内容相关;
contenthash 计算与文件内容本身相关。
最后推荐一下我的个人公众号:「卤蛋实验室」,平时会分享一些前端技术和数据分析的内容,大家感兴趣的话可以关注一波:
