YOLO中anchor box的作用(面试必考)
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了YOLO中anchor box的作用(面试必考)相关的知识,希望对你有一定的参考价值。
参考技术A 在网络最后的输出中,对于每个grid cell产生3个bounding box,每个bounding box的输出有三类参数:一个是对象的box参数,一共是四个值,即 box的中心点坐标(x,y)和box的宽和高(w,h) ;一个是 置信度 ,这是个区间在[0,1]之间的值;最后一个是 一组条件类别概率 ,都是区间在[0,1]之间的值,代表概率。假如一个图片被分割成S∗SS*SS∗S个grid cell,我们有B个anchor box,也就是说每个grid cell有B个bounding box, 每个bounding box内有4个位置参数,1个置信度,classes个类别概率,那么最终的输出维数是:S∗S∗[B∗(4+1+classes)]S*S*[B*(4 + 1 + classes)]S∗S∗[B∗(4+1+classes)]。
下面分别具体介绍这三个参数的意义。
1. anchor box
1.1 对anchor box的理解
anchor box其实就是从训练集的所有ground truth box中统计(使用k-means)出来的在训练集中最经常出现的几个box形状和尺寸。比如,在某个训练集中最常出现的box形状有扁长的、瘦高的和宽高比例差不多的正方形这三种形状。我们可以预先将这些统计上的先验(或来自人类的)经验加入到模型中,这样模型在学习的时候,瞎找的可能性就更小了些,当然就 有助于模型快速收敛 了。以前面提到的训练数据集中的ground truth box最常出现的三个形状为例,当模型在训练的时候我们可以告诉它,你要在grid cell 1附件找出的对象的形状要么是扁长的、要么是瘦高的、要么是长高比例差不多的正方形,你就不要再瞎试其他的形状了。anchor box其实就是对预测的对象范围进行约束,并加入了尺寸先验经验,从而实现多尺度学习的目的。
量化anchor box
要在模型中使用这些形状,总不能告诉模型有个形状是瘦高的,还有一个是矮胖的,我们需要量化这些形状。YOLO的做法是想办法找出分别代表这些形状的 宽和高 ,有了宽和高,尺寸比例即形状不就有了。YOLO作者的办法是使用k-means算法在训练集中所有样本的ground truth box中聚类出具有代表性形状的宽和高,作者将这种方法称作维度聚类(dimension cluster)。细心的读者可能会提出这个问题: 到底找出几个anchor box算是最佳的具有代表性的形状 。YOLO作者方法是做实验,聚类出多个数量不同anchor box组,分别应用到模型中,最终找出最优的在模型的复杂度和高召回率(high recall)之间折中的那组anchor box。作者在COCO数据集中使用了9个anchor box,我们前面提到的例子则有3个anchor box。
怎么在实际的模型中加入anchor box的先验经验呢?
最终负责预测grid cell中对象的box的最小单元是bounding box,那我们可以让一个grid cell输出(预测)多个bounding box,然后每个bounding box负责预测不同的形状不就行了?比如前面例子中的3个不同形状的anchor box,我们的一个grid cell会输出3个参数相同的bounding box,第一个bounding box负责预测的形状与anchor box 1类似的box,其他两个bounding box依次类推。 作者在YOLOv3中取消了v2之前每个grid cell只负责预测一个对象的限制,也就是说grid cell中的三个bounding box都可以预测对象,当然他们应该对应不同的ground truth 。那么如何在 训练中 确定哪个bounding box负责某个ground truth呢?方法是求出每个grid cell中每个anchor box与ground truth box的IOU(交并比),IOU最大的anchor box对应的bounding box就负责预测该ground truth,也就是对应的对象,后面还会提到负责预测的问题。
怎么告诉模型第一个bounding box负责预测的形状与anchor box 1类似,第二个bounding box负责预测的形状与anchor box 2类似?
YOLO的做法是 不让bounding box直接预测实际box的宽和高 (w,h),而是将预测的宽和高分别与anchor box的宽和高绑定,这样不管一开始bounding box输出的(w,h)是怎样的,经过转化后都是与anchor box的宽和高相关,这样经过很多次惩罚训练后,每个bounding box就知道自己该负责怎样形状的box预测了。这个 绑定的关系 是什么?就涉及到了anchor box的计算。
1.2 anchor box的计算
前提需要知道,
cxc_xcx和cyc_ycy的坐标是(0,0) (0,1),(0,2),(0,3)…(0,13)
(1,0),(1,1),(1,2),(1,3)…(1,13)等等
bouding box的输出应当为:txt_xtx和tyt_yty以及twt_wtw和tht_hth
而真实的预测box应当是:bxb_xbx和byb_yby(中心坐标)以及bwb_wbw和bhb_hbh(宽高)
还有就是cxc_xcx和cyc_ycy的每一个都是1,也就是说,每个格子grid cell是以1为一个范围,每个grid cell的大小实际是1∗11*11∗1
刚才说的绑定的关系是什么?就是下面这个公式:
bw=awetwb_w=a_we^t_wbw=awetwbh=ahethb_h=a_he^t_hbh=aheth
其中,awa_waw和aha_hah为anchor box的宽和高,
twt_wtw和tht_hth为bounding box直接预测出的宽和高,
bwb_wbw和bhb_hbh为转换后预测的实际宽和高,
这也就是最终预测中输出的宽和高。你可能会想,这个公式这么麻烦,为什么不能用bw=aw∗twb_w=a_w*t_wbw=aw∗tw, bh=ah∗thb_h=a_h*t_hbh=ah∗th这样的公式,我的理解是上面的公式虽然计算起来比较麻烦,但是在误差函数求导后还带有twt_wtw和tht_hth参数,而且也好求导(此观点只是个人推测,需要进一步查证)。
既然提到了最终预测的宽和高公式,那我们也就 直接带出最终预测输出的box中心坐标(bx,by)(b_x,b_y)(bx,by)的计算公式 :
前面提到过box中心坐标总是落在相应的grid cell中的,所以bounding box直接预测出的txt_xtx和tyt_yty也是相对grid cell来说的, 要想转换成最终输出的绝对坐标 ,需要下面的转换公式:
bx=σ(tx)+cxb_x = \sigma(t_x) + c_xbx=σ(tx)+cxby=σ(ty)+cyb_y = \sigma(t_y) + c_yby=σ(ty)+cy
其中,σ(tx)\sigma(t_x)σ(tx)为sigmoid函数,
cxc_xcx和cyc_ycy分别为grid cell方格左上角点相对整张图片的坐标。
这个公式tx,ty为何要sigmoid一下啊?
作者使用这样的转换公式主要是因为在训练时如果没有将txt_xtx和tyt_yty压缩到(0,1)区间内的话,模型在训练前期很难收敛。
另外: 用sigmoid将txt_xtx和tyt_yty压缩到[0,1]区间内,可以有效的确保目标中心处于执行预测的网格单元中,防止偏移过多 。
举个例子,我们刚刚都知道了网络不会预测边界框中心的确切坐标而是预测与预测目标的grid cell左上角相关的偏移txt_xtx和tyt_yty。如13∗1313*1313∗13的feature map中,某个目标的中心点预测为(0.4,0.7)【 都小于1 】,它的cxc_xcx和cyc_ycy即中心落入的grid cell坐标是(6,6),则该物体的在feature map中的中心实际坐标显然是(6.4,6.7).这种情况没毛病, 但若txt_xtx和tyt_yty大于1 ,比如(1.2,0.7)则该物体在feature map的的中心实际坐标是(7.2,6.7),注意这时候该物体中心在这个物体所属grid cell外面了,但(6,6)这个grid cell却检测出我们这个单元格内含有目标的中心(yolo是采取物体中心归哪个grid cell整个物体就归哪个grid celll了),这样就矛盾了,因为左上角为(6,6)的grid cell负责预测这个物体,这个物体中心必须出现在这个grid cell中而不能出现在它旁边网格中, 一旦txt_xtx和tyt_yty算出来大于1就会引起矛盾,因而必须归一化。
最终可以得出实际输出的box参数公式如下,这个也是在推理时将输出转换为最终推理结果的公式:
bx=σ(tx)+cxb_x=\sigma(t_x) + c_xbx=σ(tx)+cxby=σ(ty)+cyb_y=\sigma(t_y) + c_yby=σ(ty)+cybw=awetwb_w= a_we^t_wbw=awetwbh=ahethb_h= a_he^t_hbh=aheth
其中,
cxc_xcx和cyc_ycy是网格grid cell的左上角坐标是:(0,0) (0,1),(0,2),(0,3)…(0,13)
(1,0),(1,1),(1,2),(1,3)…(1,13)等等
bouding box的输出应当为:txt_xtx和tyt_yty以及twt_wtw和tht_hth
而真实的预测box应当是:bxb_xbx和byb_yby以及bwb_wbw和bhb_hbh
bxb_xbx和byb_yby以及bwb_wbw和bhb_hbh:预测出来的box的中心坐标和宽高
下图中的pwp_wpw实际上就是上面的awa_waw,php_hph实际上就是上面的aha_hah
训练
关于box参数的转换还有一点值得一提,作者在训练中并不是将tx、ty、tw和tht_x、t_y、t_w和t_htx、ty、tw和th转换为bx、by、bwb_x、b_y、b_wbx、by、bw和bhb_hbh后与ground truth box的对应参数 求误差 , 而是使用上述公式的逆运算将ground truth box的参数转换为 与tx、ty、twt_x、t_y、t_wtx、ty、tw和th对应的gx、gy、gwt_h对应的g_x、g_y、g_wth对应的gx、gy、gw和ghg_hgh,然后再计算误差。
也就是说,我们 训练 的输出是:tx、ty、twt_x、t_y、t_wtx、ty、tw和tht_hth,那么在计算误差时,也是利用真实框的tˆx、tˆy、tˆw\hat t_x、\hat t_y、\hat t_wt^x、t^y、t^w和tˆh\hat t_ht^h这几个值计算误差。
所以需要求解tˆx、tˆy、tˆw\hat t_x、\hat t_y、\hat t_wt^x、t^y、t^w和tˆh\hat t_ht^h:
对于上面的公式:
bx=σ(tx)+cxb_x=\sigma(t_x) + c_xbx=σ(tx)+cxby=σ(ty)+cyb_y=\sigma(t_y) + c_yby=σ(ty)+cybw=awetwb_w= a_we^t_wbw=awetwbh=ahethb_h= a_he^t_hbh=aheth
我们可以知道其中,bx、by、bwb_x、b_y、b_wbx、by、bw和bhb_hbh实际上就是预测出来的框box的中心坐标和宽高,那么如果预测的非常准确,需要真实框的gx、gy、gwg_x、g_y、g_wgx、gy、gw和ghg_hgh坐标应当为:(gx、gy、gwg_x、g_y、g_wgx、gy、gw和ghg_hgh实际上是实际框的中心坐标和宽高)
gx=σ(tx)+cxg_x=\sigma(t_x) + c_xgx=σ(tx)+cxgy=σ(ty)+cyg_y=\sigma(t_y) + c_ygy=σ(ty)+cygw=awetwg_w= a_we^t_wgw=awetwgh=ahethg_h= a_he^t_hgh=aheth
由此可以得到,真实框的tˆx、tˆy、tˆw\hat t_x、\hat t_y、\hat t_wt^x、t^y、t^w和tˆh\hat t_ht^h
计算中由于sigmoid函数的反函数那计算,所以并没有计算sigmoid的反函数,而是计算输出对应的sigmoid函数值。
σ(tˆx)=gx−cx\sigma(\hat t_x) = g_x - c_xσ(t^x)=gx−cxσ(tˆy)=gy−cy\sigma(\hat t_y) = g_y - c_yσ(t^y)=gy−cytˆw=log(gw/aw)\hat t_w = \log(g_w / a_w)t^w=log(gw/aw)tˆh=log(gh/ah)\hat t_h = \log(g_h / a_h)t^h=log(gh/ah)
这样,我们就可以根据训练的输出σ(tx)、σ(ty)、tw\sigma(t_x)、\sigma(t_y)、t_wσ(tx)、σ(ty)、tw和tht_hth以及真实框的值σ(tˆx)、σ(tˆy)、tˆw\sigma(\hat t_x)、\sigma(\hat t_y)、\hat t_wσ(t^x)、σ(t^y)、t^w和tˆh\hat t_ht^h求出误差了。
2. 置信度(confidence)
还存在一个很关键的问题:在训练中我们挑选哪个bounding box的准则是选择预测的box与ground truth box的IOU最大的bounding box做为最优的box,但是在预测中并没有ground truth box,怎么才能挑选最优的bounding box呢?这就需要另外的参数了,那就是下面要说到的置信度。
置信度是每个bounding box输出的其中一个重要参数,作者对他的 作用定义有两重 :
一重是 :代表当前box是否有对象的概率Pr(Object)P_r(Object)Pr(Object),注意,是对象,不是某个类别的对象,也就是说它用来说明当前box内只是个背景(backgroud)还是有某个物体(对象);
另一重 :表示当前的box有对象时,它自己预测的box与物体真实的box可能的IOUtruthpredIOU_pred^truthIOUpredtruth的值,注意,这里所说的物体真实的box实际是不存在的,这只是模型表达自己框出了物体的自信程度。
以上所述,也就不难理解作者为什么将其称之为置信度了,因为不管哪重含义,都表示一种自信程度:框出的box内确实有物体的自信程度和框出的box将整个物体的所有特征都包括进来的自信程度。经过以上的解释,其实我们也就可以用数学形式表示置信度的定义了:
Cji=Pr(Object)∗IOUtruthpredC_i^j = P_r(Object) * IOU_pred^truthCij=Pr(Object)∗IOUpredtruth
其中,CjiC_i^jCij表示第i个grid cell的第j个bounding box的置信度。
那么如何训练CjiC_i^jCij?
训练中,Cˆji\hat C_i^jC^ij表示真实值,Cˆji\hat C_i^jC^ij的取值是由grid cell的bounding box有没有负责预测某个对象决定的。如果负责,那么Cˆji=1\hat C_i^j=1C^ij=1,否则,Cˆji=0\hat C_i^j=0C^ij=0。
下面我们来说明如何确定某个grid cell的bounding box是否负责预测该grid cell中的对象:前面在说明anchor box的时候提到每个bounding box负责预测的形状是依据与其对应的anchor box(bounding box prior)相关的,那这个anchor box与该对象的ground truth box的IOU在所有的anchor box(与一个grid cell中所有bounding box对应,COCO数据集中是9个)与ground truth box的IOU中最大,那它就负责预测这个对象,因为这个形状、尺寸最符合当前这个对象,这时Cˆji=1\hat C_i^j=1C^ij=1,其他情况下Cˆji=0\hat C_i^j=0C^ij=0。注意,你没有看错,就是所有anchor box与某个ground truth box的IOU最大的那个anchor box对应的bounding box负责预测该对象,与该bounding box预测的box没有关系。
3. 对象条件类别概率(conditional class probabilities)
对象条件类别概率是一组概率的数组,数组的长度为当前模型检测的类别种类数量, 它的意义是当bounding box认为当前box中有对象时,要检测的所有类别中每种类别的概率 .
其实这个和分类模型最后使用softmax函数输出的一组类别概率是类似的,只是二者存在两点不同:
YOLO的对象类别概率中没有background一项,也不需要,因为对background的预测已经交给置信度了,所以它的输出是有条件的,那就是在置信度表示当前box有对象的前提下,所以条件概率的数学形式为Pr(classi∣Object)P_r(class_i|Object)Pr(classi∣Object);
分类模型中最后输出之前使用softmax求出每个类别的概率,也就是说各个类别之间是互斥的,而YOLOv3算法的每个类别概率是单独用逻辑回归函数(sigmoid函数)计算得出了,所以每个类别不必是互斥的,也就是说一个对象可以被预测出多个类别。这个想法其实是有一些YOLO9000的意思的,因为YOLOv3已经有9000类似的功能,不同只是不能像9000一样,同时使用分类数据集和对象检测数据集,且类别之间的词性是有从属关系的。
侵删
JavaScript基础--------三座大山(前端面试必考)
1.原型和原型链
2.作用域和闭包
3.异步和单线程
被称为JavaScript的三座大山
原型和原型链:
在JavaScript中,数组,对象和函数被称为引用类型,他们都有一个__proto__属性,该属性是一个对象(我们称之为隐式原型)
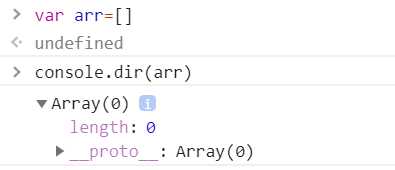
arr数组的构造函数是Array,Array构造函数中有一个prototype属性,(我们暂时称之为显式原型)

arr是构造函数的实例对象,arr中的__proto__对象指向构造函数中的prototype对象
![]()
接下来是一个简单的demo
1 //创建一个构造函数 2 function Animal(name){ 3 this.name = name 4 } 5 Animal.prototype.eat = function(){ 6 console.log(‘Animal--eat‘) 7 } 8 // 用new初始化一个Animal的实例对象 9 var dog = new Animal(‘xiaohuang‘) 10 11 console.log(dog.name) 12 console.log(dog.eat())
输出结果为

看一下dog对象中有什么属性

调用dog的属性和方法时,会先从dog本身去查找,如果dog本身没有那个属性或方法,就会去dog的__proto__原型中去查找,而__proto__又指向Animal的prototype(看第二个constructor对象,指向Animal),这就是原型链
再来一个demo
1 //创建一个构造函数 2 function Animal(name){ 3 this.name = name 4 } 5 //创建一个Hashiqi的构造函数 6 function Hashiqi(){ 7 } 8 Animal.prototype.eat = function(){ 9 console.log(‘Animal--eat‘) 10 } 11 Hashiqi.prototype.color = function(){ 12 console.log(‘Hashiqi---color‘) 13 } 14 //改变prototype的指向 15 Animal.prototype = new Hashiqi() 16 // 用new初始化一个Animal的实例对象 17 var dog = new Animal(‘xiaohuang‘) 18 19 console.log(dog.name) 20 console.log(dog.eat()) 21 console.log(dog.color())
这个demo中改变了Animal的prototype,将其指向一个Hashiqi的实例对象,我们来看结果。此时dog.eat()会报错,dog.color正常输出

第三个demo,比较上档次一点
1 <div id="wrapper">this is wrapper</div> 2 <script> 3 //创建一个Elem的构造函数 4 function Elem(id){ 5 //获取dom元素 6 this.id = document.getElementById(id) 7 } 8 Elem.prototype.html = function(val){ 9 //如果val为空,则打印dom元素的innerhtml值 10 if(val == null){ 11 console.log(this.id.innerHTML) 12 //返回this,可以用来进行链式操作 13 return this 14 }else{ 15 this.id.innerHTML = val 16 return this 17 } 18 } 19 //绑定事件 20 Elem.prototype.on = function(type, fn){ 21 this.id.addEventListener(type,fn) 22 } 23 24 </script>
首先new一个实例对象: var el = new Elem(‘wrapper‘)
el.html(‘ ookook ‘).on(‘click‘, function(){ console.log(‘this is ook‘) } )
接下来点击ookook就会打印this is ook
作用域和闭包:
JavaScript中有函数作用域和全局作用域(es6中用let声明的变量具有块作用域)
函数作用域是在一个函数中有效,全局作用域在全局都有效
*函数内部如果变量和全局变量重名了,则在该函数内部,以函数变量为准
*函数外部无法访问函数内部定义的变量(该变量是函数私有的),不过函数内部可以访问函数外部的全局变量
1.变量提升
javascript中声明并定义一个变量时,会把声明提前,以下会先打印出undefined,再打印出10
1 console.log(a) 2 var a = 10 3 console.log(a)
相当于
1 var a 2 console.log(a) 3 a = 10 4 console.log(a)
函数声明也是,以下函数相当于把整个fn提到作用域的最上面,所以调用fn时会正常打印jack
1 fn(‘jack‘) 2 function fn (name){ 3 console.log(name) 4 }
不过函数表达式不行,以下是一个函数表达式,JavaScript会把var fn提到作用域最上面,没有吧函数提上去,所以会报错
1 fn("jack"); 2 3 var fn = function(name) { 4 console.log(name); 5 };
2.闭包
使用场景:1.函数作为参数传递 2.函数作为返回值传递
三言两语说不清楚,我们来看一个demo
1 function F1(){ 2 var a = 100 3 //返回一个函数 4 return function(){ 5 console.log(a) 6 } 7 } 8 9 var a = 200; 10 var f1 = F1(); //将f1指向F1 11 f1()
第11行输出结果是100
第11行调用f1的时候要打印a变量,return的函数中没有a变量,所以a是个自由变量,要去声明该函数(不是调用)的父级作用域去查找,即functin F1中,a=100
闭包在开发中的应用
以下函数的目的是:当_list中没有val值时,返回true并把val添加到_list中
这个demo使用了闭包,在外部无法直接访问_list这个Fn函数的私有变量,这样可以保证数据不被污染,提高了安全性
1 function Fn(){ 2 var _list = [] 3 4 return function(val){ 5 if(_list.indexOf(val) < 0){ 6 _list.push(val) 7 return true 8 }else{ 9 return false 10 } 11 } 12 } 13 14 var f1 = Fn() 15 console.log(f1(10)) //true 16 console.log(f1(10)) //false 17 console.log(f1(20)) //true 18 console.log(f1(20)) //false
异步和单线程
异步和单线程是相辅相成的,js是一门单线程脚本语言,所以需要异步来辅助
异步和同步的区别: 异步会阻塞程序的执行,同步不会阻塞程序的执行,
比如只有在执行完alert后才会打印100,如果你不去点击弹框的确定键,console.log就永远不会执行,这就是同步的阻塞
第二个demo中,会马上就打印100,两秒后再打印setTimeout,这就是异步不会阻塞程序执行
1 alert(‘ook‘) 2 console.log(100)
1 setTimeout(function(){ 2 console.log(‘setTimeout‘) 3 },2000) 4 console.log(100)
在哪些场景中会异步执行
JavaScript中以下三种情况会异步执行 1.定时任务:setTimeout, setInterval 2.网络请求:ajax请求,动态加载<img>图标 3.事件绑定:比如‘click’等
看一个demo
以下函数的目的是在页面中创建5个a标签,点击第一个a标签打印1,点击第二个a标签打印2,以此类推。可执行结果都是5,为什么呢?
因为click是一个异步事件,计算机不知道用户什么时候会点击,所以不能够是同步,不然用户不点击,程序就永远无法往下执行。
异步事件会先拿出来放到一个队列里,等同步事件执行完了,再来执行异步事件
所以当你点击a标签的时候,i已经循环到5了(i是全局变量。这也涉及到了js作用域:该函数没有定义i变量,就要去声明该函数的父级作用域中去找,而不是调 用)
1 for(var i = 0; i < 5; i++){ 2 //创建一个a标签 3 var a = document.createElement(‘a‘) 4 a.innerHTML = i + 1 + ‘<br>‘ 5 //给a标签绑定click事件 6 a.addEventListener(‘click‘, function(e){ 7 e.preventDefault() 8 console.log(i) 9 }) 10 //将a标签添加到wrpper中 11 document.querySelector(‘#wrapper‘).appendChild(a) 12 }
解决这个问题就可以用闭包,用一个function把给a添加时间的地方包起来,(function(i){})(i) 这是函数的自调用。注意:自调用前要加分号,也就是第4行结束要加分号,不然js会分不清何时开始自调用,会报错
1 for(var i = 0; i < 5; i++){ 2 //创建一个a标签 3 var a = document.createElement(‘a‘) 4 a.innerHTML = i+1 + ‘<br>‘; 5 //给a标签绑定click事件 6 (function(i){ 7 a.addEventListener(‘click‘, function(e){ 8 e.preventDefault() 9 console.log(i+1) 10 }) 11 })(i) 12 //将a标签添加到wrpper中 13 document.querySelector(‘#wrapper‘).appendChild(a) 14 }
以上是关于YOLO中anchor box的作用(面试必考)的主要内容,如果未能解决你的问题,请参考以下文章
面试题常考&必考之--盒子模型和box-sizing(项目中经常使用)
yolo 算法 网格的两个bounding box大小是怎么确定的