YOLO系列中Anchor Based和Anchor Free的相爱相杀
Posted 彭祥.
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了YOLO系列中Anchor Based和Anchor Free的相爱相杀相关的知识,希望对你有一定的参考价值。
前言
我们都知道按照是否出现RPN可将目标检测算法分为two-stage和one-stage,其中one-stage的一个主要代表便是YOLO系列,而根据是否存在先验锚框的定义我们也可以将其分为Anchor based和Anchor free两类,关于这两种也是各有优劣,但大趋势上好像是倾向于Anchor Free,但实际上,两者真正能够产生差别的原因在于正负样本匹配机制。本文便以YOLO系列目标检测算法为例,讲述Anchor Based和Anchor Free的相爱相杀。(作者能力有限,在此只发表个人观点,如有错误,请诸君不吝赐教)
之所以有上面的观点是因为在YOLO初始时,其使用的便是Anchor Free的思想,但其结果却与当时的Two Stage相形见绌,因此,在V2到V5的版本中,其一直使用的便是Anchor Based,但在YOLOX中,其又使用了Anchor Free的思想,并且性能表现一骑绝尘。归根结底,是由于正负样本匹配策略的改进令其如此大放异彩。
该观点是在下面这篇论文中提出的:

下载地址:
https://arxiv.org/abs/1912.02424
博主便以该论文为基础,结合自身的学习经验提出自己的一些浅知拙见。
基础概念
首先我们先来了解一下相关的基础概念,博主之前对anchor based和anchor free的理解便是是否实现规定anchor,但对一些概念问题不甚了解,在这里先解决一下:
问题1:Anchor-based 和Ancho- free分别是什么意思?
目标检测算法依据是否定义先验锚框分为基于锚框(Anchor-based )的无锚框(Anchor-free)的目标检测算法。
基于锚框的目标检测算法是通过显式或隐式的方式创建一系列具有不同尺寸、长宽比的检测框(锚框),然后对锚框中的内容进行分类或回归。其根据物体的尺寸、长宽比在训练数据中的分布确定锚框的尺度、长宽比、生成锚框数量、交并比阈值等超参数。这些超参数的选取会直接影响最后的精度。所以这种方法不仅依赖先验知识还缺乏泛化能力。
此外基于锚框的目标检测算法还有因为训练过程大量计算锚框与真实边界框的交并比而产生大量计算冗余、基于锚框生成的训练样本中正负样本失衡,影响精度、对异常物体检测精度低等缺点。
无锚框目标检测算法移除预设锚框的过程,直接预测物体的边界框。
无锚框目标检测算法可以分为基于中心域的目标检测算法和基于关键点的目标检测算法。
基于中心域的目标检测算法直接预测物体的中心区域坐标和边界框的尺度信息。YOLOV1算法是一种早期的基于中心域的目标检测算法。
关于YOLOV1的介绍,可以参考博主这篇文章:
https://blog.csdn.net/pengxiang1998/article/details/128249585?spm=1001.2014.3001.5502
但由于YOLO算法只检测离中心点距离最近的物体,所以召回率较低,精度低于同时期基于锚框的一阶段目标检测算法。后期的一些YOLO系列检测算法就没有采用无锚框的。
基于关键点的目标检测算法一般以热力图的方式预测输入图像中各个点是边界框中的关键点的概率,然后将多组热力图组合得到物体边界框。

问题2:比较基于锚框和无锚框的目标检测算法的优缺点。
基于锚框的目标检测算法根据场景和数据集的特点预定义先验锚框,然后通过分类和回归等方法由预定义的锚框生成物体边界框。
优点是技术较成熟,缺点是泛化能力差,计算冗余等。
无锚框的目标检测算法直接预测图像中各像素属于待检测物体的概率及物体的边界框信息,然后根据这些信息生成边界框。
优点是泛化能力强、框架更简洁、异常尺度目标检测精度高,缺点是不适合进行通用目标检测,适用多尺度目标检测、小目标检测等,精度低于基于锚框的算法。
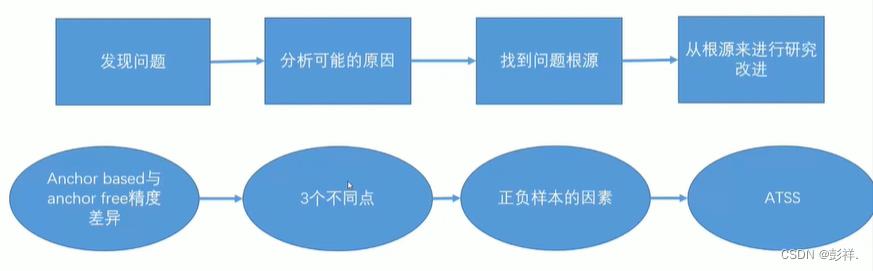
在论文中,作者指出导致Anchor based与Anchor free性能差距的原因是正负样本匹配策略导致的,并对此进行了实验验证,并由此提出了一种自适应训练样本选择方法(Adaptive Training Sample Selection (ATSS)),根据物体特征来自动的选择正负训练样本,并通过实验证明该方法的可行性。
论文源码:https://github.com/sfzhang15/ATSS
理论与实验
随着FPN和Focal Loss的提出,anchor-free的检测器变得流行起来。先前已经提到。论文中指出Anchor based和Anchor free性能差距的主要原因是正负样本匹配策略导致的,并且通过RetinaNet与FCOS分别作为两者检测器的代表来进行实验并证明结论。其都是一阶段检测器,相比而言,其有以下不同:
1.每个位置平铺的anchors数量不同。RetinaNet每个位置有几个anchor box,而FCOS每个位置只有一个anchor point。(FCOS的一个point等价于RetinaNet中一个anchor box的中心,所以这里叫做anchor point。)
2.正负样本的定义不同。RetinaNet使用的是样本和真实框的IoU判断正负,FCOS使用的是空间和尺度限制来选择样本。
3.回归的起始状态。RetinaNet从预设anchor box开始回归物体边框,而FCOS从anchor point开始定位物体。
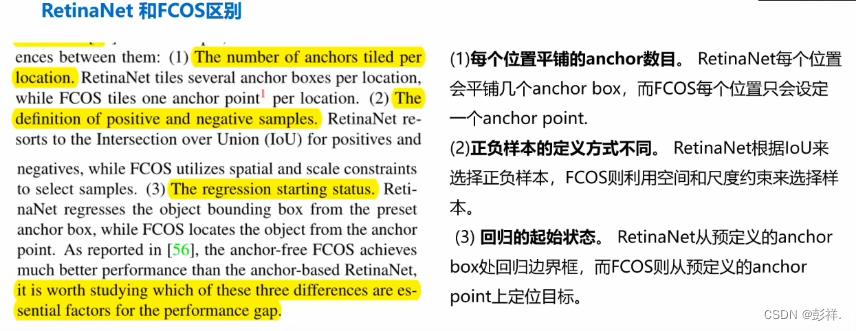
从上面我们看到,两者主要有三点不同,那么为何作者指出是由于正负样本匹配策略导致两者性能差距呢,作者通过控制变量的方式给出了证明。
可以看出其过程为:
实验设置
将Anchor数都设置为1
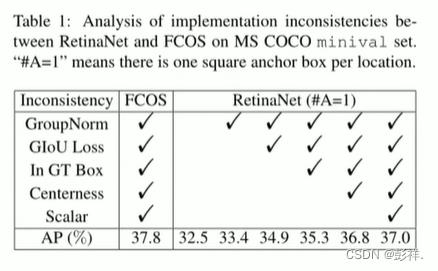
将RetinaNet设置为每个位置一个anchor(A=1)后进行实验:此时效果为:37.1% vs. 32.5%,而在FCOS中进行了一些通用的改进后,如heads中增加GroupNorm,使用GIoU作回归损失函数,限制ground-truth box中的正样本,映入center-ness分支,并未每个金字塔层增加一个可训练的标量。这些改进也可以应用到anchor-based的检测器中,因此他们不是造成anchor-based和anchor-free的核心差异。将这些应用到了RetinaNet(#A=1)以排除不一致设置,如表1所示。结果RetinaNet提高到了 37.0%,但是仍然和FCOS有0.8%的差距。这个差距是在排除所有无关不同情况下的,因此接下来可以探索他们的核心差异。
在应用了通用的改进后,RetinaNet(A=1)和FCOS只有两点不同:一是检测上的分类子任务,如训练正负样本的定义不同;二是回归子任务,如回归从anchor box还是anchor point开始。
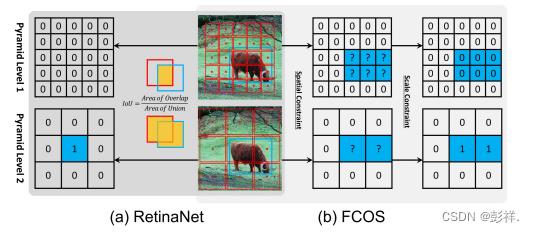
这里右上图中个人认为应该为1
上图表示正负样本的定义。正样本数字为1,负样本数字为0。蓝色框、红色框和红色点分别对应真实物体,anchor box和anchor point。(a)RetinaNet根据IoU判断样本正负,同时在空间维度和尺度维度上判断。(b)FCOS首先在空间维度上找到候选的正样本,然后再根据尺度维度选择最终的正样本。
RetinaNet根据IoU判定训练样本正负。如图1(a)所示,RetinaNet利用IoU同时在空间和尺度维度上直接选择最终的正样本。首先每个物体对应的anchors里IoU最高的为正样本,其次,anchor boxes的IoU大于 θ 也为正样本。然后将IoU小于 θ 的标记为负样本,其余的忽略。如图(b)所示FCOS使用空间和尺度限制来划分不同金字塔层的anchor point。首先考虑的处在真实框内的anchor point为候选正样本,然后基于每个金字塔层的定义的尺度范围来选择最终的正样本(FCOS有几个预设的超参数定义5个金字塔层的尺度范围),没有被选择的anchor points则为负样本。两种不同的选择策略产生了不同的正样本和负样本。
此时在 MS COCO minival数据集上不同设置的分析。
结果如下,对于RetinaNet,即Box列,当使用当使用空间和尺度限制替换IoU时,精度从 37.0% 提高到37.8%。对于FCOS,即Point列,如果使用IoU策略选择正样本,AP表现将从37.8% 下降到36.9%。这个结果证明了正负样本的定义方式是anchor-based和anchor-free检测器的本质区别。

在确定正负样本后,需要对对正样本回归,如下图(a)所示。当RetinaNet和FCOS采用相同的样本选择策略,得到的正/负样本一致,此时无论是从一个点还是从一个边框开始回归,最终的表现都没有明显的不同,如上表所示的37.0% vs. 36.9%和37.8% vs. 37.8%,这表明回归的起始状态是无影响的差异而不是核心差异。
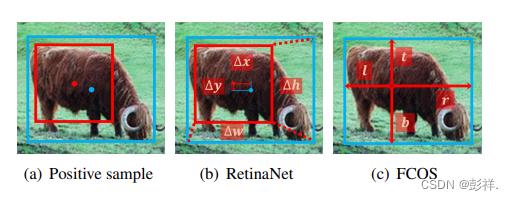
蓝点和边框是物体的中心和边框,红点和边框是anchor的中心和边框。(b)RetinaNet根据4个偏移从anchor box回归。©FCOS根据到边框四边的距离从anchor point回归。
由此可见,Anchor Free和Anchor Based 性能差距的主要原因便是正负样本匹配策略导致的。由此论文中提出的第一个观点得到了证明。
以上是关于YOLO系列中Anchor Based和Anchor Free的相爱相杀的主要内容,如果未能解决你的问题,请参考以下文章