第一次作业:基于Linux进程模型分析
Posted 洛杉矶的甘蔗镇tm硬
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了第一次作业:基于Linux进程模型分析相关的知识,希望对你有一定的参考价值。
1、前言
本次作业选择Linux kernel 3.0.2的源码进行进程的分析。
Linux kernel 3.0.2源码的下载地址:https://mirrors.edge.kernel.org/pub/linux/kernel/v3.0/linux-3.0.2.tar.gz
2、进程的定义
「进程(Process)是计算机中的程序关于某数据集合上的一次运行活动,是系统进行资源分配和调度的基本单位,是操作系统结构的基础。」 -- 百度百科
「一个进程就是一个正在执行程序的实例」 -- 《现代操作系统》
可以从上面的进程定义看出,进程的管理和调度对于操作系统来说是十分重要的一部分,下面我们用最直观的方式先来看一看系统中的进程是什么样子的。
(在terminal中使用ps aux指令 查看系统中的所有进程)
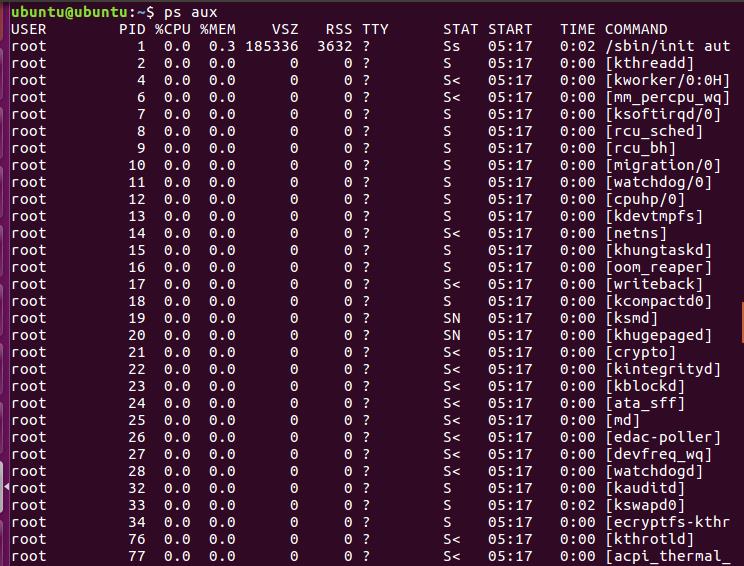
3、源码分析--进程的组织
3.1 进程是如何创建的
3.1.1 创建进程的方法
首先了解一下进程创建的方法:在Linux中主要提供了fork、vfork、clone三个进程创建方法。 这里我们简单讲一下fork。
fork创建一个进程时,子进程只是完全复制父进程的资源,复制出来的子进程有自己的task_struct结构和PID,但却复制父进程其它所有的资源。(这里要注意,新进程都是由于一个已存在的进程执行了一个用于创建进程的系统调用而创建的)。fork函数


long do_fork(unsigned long clone_flags, unsigned long stack_start, struct pt_regs *regs, unsigned long stack_size, int __user *parent_tidptr, int __user *child_tidptr) { struct task_struct *p; int trace = 0; long nr; /* * Do some preliminary argument and permissions checking before we * actually start allocating stuff */ if (clone_flags & CLONE_NEWUSER) { if (clone_flags & CLONE_THREAD) return -EINVAL; /* hopefully this check will go away when userns support is * complete */ if (!capable(CAP_SYS_ADMIN) || !capable(CAP_SETUID) || !capable(CAP_SETGID)) return -EPERM; } /* * When called from kernel_thread, don\'t do user tracing stuff. */ if (likely(user_mode(regs))) trace = tracehook_prepare_clone(clone_flags); 1) p = copy_process(clone_flags, stack_start, regs, stack_size, child_tidptr, NULL, trace); /* * Do this prior waking up the new thread - the thread pointer * might get invalid after that point, if the thread exits quickly. */ if (!IS_ERR(p)) { struct completion vfork; trace_sched_process_fork(current, p); 2) nr = task_pid_vnr(p); if (clone_flags & CLONE_PARENT_SETTID) put_user(nr, parent_tidptr); if (clone_flags & CLONE_VFORK) { p->vfork_done = &vfork; init_completion(&vfork); } audit_finish_fork(p); tracehook_report_clone(regs, clone_flags, nr, p); /* * We set PF_STARTING at creation in case tracing wants to * use this to distinguish a fully live task from one that * hasn\'t gotten to tracehook_report_clone() yet. Now we * clear it and set the child going. */ p->flags &= ~PF_STARTING; wake_up_new_task(p, clone_flags); tracehook_report_clone_complete(trace, regs, clone_flags, nr, p); if (clone_flags & CLONE_VFORK) { freezer_do_not_count(); wait_for_completion(&vfork); freezer_count(); tracehook_report_vfork_done(p, nr); } } else { nr = PTR_ERR(p); } return nr; }
被定义在linux-3.0.2/arch/kernel/fork.c中
那么什么是task_struct和PID呢,它们在linux系统中的进程组织扮演着什么样的角色,下面让我们再深入一点去了解一下。
3.2 PCB(进程控制块)--task_struct结构体
3.2.1task_struct定义:
Linux的进程控制块为一个由结构task_struct所定义的数据结构,task_struct定义在在/include/ linux/sched.h 中,其中包括管理进程所需的各种信息。在创建一个新进程时,系统在内存中申请一个空的task_struct区,即空闲PCB块,并填入所需信息。同时将指向该结构的指针填入到task[]数组中。当前处于运行状态进程的PCB用指针数组current_set[]来指出。这是因为Linux支持多处理机系统,系统内可能存在多个同时运行的进程,故current_set定义成指针数组。由于task_struct 的结构体成员非常多,这里不一一进行分析,这里给出部分成员及其分析
unsigned long flags; //Flage 是进程号,在调用fork()时给出 int sigpending; //进程上是否有待处理的信号 mm_segment_t addr_limit; //进程地址空间,区分内核进程与普通进程在内存存放的位置不同 //0-0xBFFFFFFF for user-thead //0-0xFFFFFFFF for kernel-thread //调度标志,表示该进程是否需要重新调度,若非0,则当从内核态返回到用户态,会发生调度 volatile long need_resched; int lock_depth; //锁深度 long nice; //进程的基本时间片 //进程的调度策略,有三种,实时进程:SCHED_FIFO,SCHED_RR, 分时进程:SCHED_OTHER unsigned long policy; struct mm_struct *mm; //进程内存管理信息 int processor; //若进程不在任何CPU上运行, cpus_runnable 的值是0,否则是1 这个值在运行队列被锁时更新 unsigned long cpus_runnable, cpus_allowed; struct list_head run_list; //指向运行队列的指针 unsigned long sleep_time; //进程的睡眠时间 //用于将系统中所有的进程连成一个双向循环链表, 其根是init_task struct task_struct *next_task, *prev_task; struct mm_struct *active_mm; struct list_head local_pages; //指向本地页面 unsigned int allocation_order, nr_local_pages; struct linux_binfmt *binfmt; //进程所运行的可执行文件的格式 int exit_code, exit_signal; int pdeath_signal; //父进程终止是向子进程发送的信号 unsigned long personality; //Linux可以运行由其他UNIX操作系统生成的符合iBCS2标准的程序 int did_exec:1; pid_t pid; //进程标识符,用来代表一个进程 pid_t pgrp; //进程组标识,表示进程所属的进程组 pid_t tty_old_pgrp; //进程控制终端所在的组标识 pid_t session; //进程的会话标识 pid_t tgid; int leader; //表示进程是否为会话主管 struct task_struct *p_opptr,*p_pptr,*p_cptr,*p_ysptr,*p_osptr; struct list_head thread_group; //线程链表 struct task_struct *pidhash_next; //用于将进程链入HASH表 struct task_struct **pidhash_pprev; wait_queue_head_t wait_chldexit; //供wait4()使用 struct completion *vfork_done; //供vfork() 使用 unsigned long rt_priority; //实时优先级,用它计算实时进程调度时的weight值
总而言之,task_struct 是linux系统在管理和组织进程极其重要的一部分,task_struct是进程描述符。操作系统通过task_struct感知进程的存在。那么操作系统在进行进程调度时操作的就是task_struct本身吗?答案是否定的。因为作为一个庞大的结构体,如果操作系统每次进行调度时都直接对其进行操作,那么这无疑将大大增加调度器的复杂程度。所以linux采用进程调度实体(sched_entity)进行进程调度。我们将在下面的3.4中讨论这个进程调度实体。
3.2.2 PID(进程标识符)的定义
PID(Process Identification)是 Linux 中在其命名空间中唯一标识进程而分配给它的一个号码,称做进程ID号,简称PID。在使用 fork 或 clone 系统调用时产生的进程均会由内核分配一个新的唯一的PID值(注意,进程终止后这个PID会被回收并且有可能被分配给一个新进程)。在linux源码中PID是被定义在task_struct中的。 pid_t pid; 。并且在task_struct 中定义了一个PID散列表 struct pid_link pids[PIDTYPE_MAX]; ,该表是一个双向链表,也就是说PID是以双向链表的形式存储的。当有新进程产生时,会自动添加一个新的PID到对应的散列表。那么pid_t到底是什么数据类型,通过查阅资料可知pid其实是宏定义的 unsigned int 类型。
void attach_pid(struct task_struct *task, enum pid_type type, struct pid *pid) { struct pid_link *link; link = &task->pids[type]; link->pid = pid; hlist_add_head_rcu(&link->node, &pid->tasks[type]); }
3.3 进程的状态
3.3.1 进程的三种基本状态:
1)就绪(ready)态:可运行,但因为其他进程正在运行而暂时停止。
2)运兴态:该时刻进程实际占用CPU。
3)阻塞态:除非某种外部事件发生,否则进程不能运行。
-----《现代操作系统》
3.3.2 进程状态在task_struct 中的定义为:
volatile long state; /* -1 unrunnable, 0 runnable, >0 stopped */ 代码注释中给出了 state 不同取值时标识的进程状态,取值-1时为unrunnable ,取值为0时为runnable,取值大于0时为stopped。在sched.h中代码的开头宏定义了几种state的可能取值
#define TASK_RUNNING 0 #define TASK_INTERRUPTIBLE 1 #define TASK_UNINTERRUPTIBLE 2 #define __TASK_STOPPED 4 #define __TASK_TRACED 8 /* in tsk->exit_state */ #define EXIT_ZOMBIE 16 #define EXIT_DEAD 32 /* in tsk->state again */ #define TASK_DEAD 64 #define TASK_WAKEKILL 128 #define TASK_WAKING 256 #define TASK_STATE_MAX 512 #define TASK_STATE_TO_CHAR_STR "RSDTtZXxKW"
| 状态 | 描述 |
|---|---|
| TASK_RUNNING | 表示进程正在执行或者处于准备执行的状态 |
| TASK_INTERRUPTIBLE | 进程因为等待某些条件处于阻塞(挂起的状态),一旦等待的条件成立,进程便会从该状态转化成就绪状态 |
| TASK_UNINTERRUPTIBLE | 意思与TASK_INTERRUPTIBLE类似,但是我们传递任意信号等不能唤醒他们,只有它所等待的资源可用的时候,他才会被唤醒。 |
| TASK_STOPPED | 进程被停止执行 |
| TASK_TRACED | 进程被debugger等进程所监视。 |
| EXIT_ZOMBIE | 进程的执行被终止,但是其父进程还没有使用wait()等系统调用来获知它的终止信息,此时进程成为僵尸进程 |
| EXIT_DEAD | 进程被杀死,即进程的最终状态。 |
| TASK_KILLABLE | 当进程处于这种可以终止的新睡眠状态中,它的运行原理类似于 TASK_UNINTERRUPTIBLE,只不过可以响应致命信号 |
3.3.3 进程的状态转换图(图片来自网络)
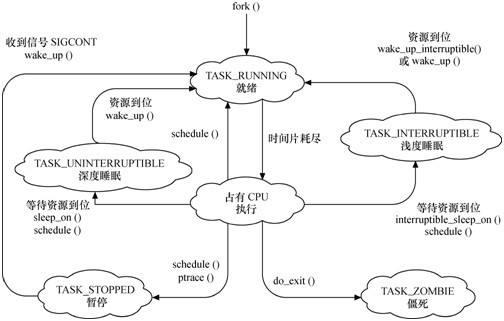
3.4 进程的调度
3.4.1 进程调度实体(sched_entity)
在上面的3.2.1中我们提到了进程调度实体,那么什么是进程调度实体呢 -- linux中可调度的不仅仅是进程,也可能是一个进程组,所以LInux就把调度对象抽象化成一个调度实体。就像是很多结构中嵌入list_node用于连接链表一样,这里需要执行调度的也就需要加入这样一个调度实体。实际上,调度器直接操作的也是调度实体,只是会根据调度实体获取到其对应的结构。
struct sched_entity { struct load_weight load; /* for load-balancing 即用于负载均衡,决定了各个实体占队列中负荷的比例,计算负荷权重是调度器的主要责任,因为选择下一个进程就是要根据这些信息。*/ struct rb_node run_node; /*run_node是一个红黑树节点,用于把实体加入到红黑树,on_rq表明该实体是否位于就绪队列,当为1的时候就说明在就绪队列中,一个进程在得到调度的时候会从就绪队列中摘除,在让出CPU的时候会重新添加到就绪队列 (正常调度的情况,不包含睡眠、等待)。*/ struct list_head group_node; /*exec_start记录进程开始在CPU上运行的时间*/ unsigned int on_rq; u64 exec_start; u64 sum_exec_runtime; /*sum_exec_time记录进程一共在CPU上运行的时间*/ u64 vruntime; u64 prev_sum_exec_runtime; /*pre_sum_exec_time记录本地调度之前,进程已经运行的时间。*/ u64 nr_migrations; #ifdef CONFIG_SCHEDSTATS struct sched_statistics statistics; #endif #ifdef CONFIG_FAIR_GROUP_SCHED struct sched_entity *parent; /* rq on which this entity is (to be) queued: */ struct cfs_rq *cfs_rq; /* rq "owned" by this entity/group: */ struct cfs_rq *my_q; #endif #ifdef CONFIG_SMP /* Per-entity load-tracking */ struct sched_avg avg; #endif };
3.4.2 进程调度的实际实现
调度器运行期间是要禁止内核抢占的,从级别上来讲,Linux中的调度器不见得比其他进程的级别高,但是肯定不会低于普通进程,即调度器运行期间会禁止内核抢占。从函数代码来看,这里首先调用了 preempt_disable 函数设置了 preempt_count 禁止内核抢占,然后获取当前CPU的就绪队列结构rq,prev保存当前任务,下面的 prev->state && !(preempt_count() & PREEMPT_ACTIVE) 是对有些进行移除运行队列。具体就是如果当前进程是阻塞并且 PREEMPT_ACTIVE 没有被设置,就有了移除就绪队列的条件,然后判断是否又挂起的信号,如果有,那么暂时不移除队列,否则就执行 deactivate_task 函数移除队列,并设置 prev->on_rq=0 ,表明该进程不在就绪队列中。下面的if是判断如果当前进程是一个工作线程,那么就通知工作队列,看是否需要唤醒另一个worker
static void __sched __schedule(void) { struct task_struct *prev, *next; unsigned long *switch_count; struct rq *rq; int cpu; need_resched: /*禁止内核抢占*/ preempt_disable(); cpu = smp_processor_id(); /*获取CPU 的调度队列*/ rq = cpu_rq(cpu); rcu_note_context_switch(cpu); /*保存当前任务*/ prev = rq->curr; schedule_debug(prev); if (sched_feat(HRTICK)) hrtick_clear(rq); /* * Make sure that signal_pending_state()->signal_pending() below * can\'t be reordered with __set_current_state(TASK_INTERRUPTIBLE) * done by the caller to avoid the race with signal_wake_up(). */ smp_mb__before_spinlock(); raw_spin_lock_irq(&rq->lock); switch_count = &prev->nivcsw; /* 如果内核态没有被抢占, 并且内核抢占有效 即是否同时满足以下条件: 1 该进程处于停止状态 2 该进程没有在内核态被抢占 */ if (prev->state && !(preempt_count() & PREEMPT_ACTIVE)) { if (unlikely(signal_pending_state(prev->state, prev))) { prev->state = TASK_RUNNING; } else { deactivate_task(rq, prev, DEQUEUE_SLEEP); prev->on_rq = 0; /* * If a worker went to sleep, notify and ask workqueue * whether it wants to wake up a task to maintain * concurrency. */ if (prev->flags & PF_WQ_WORKER) { struct task_struct *to_wakeup; to_wakeup = wq_worker_sleeping(prev, cpu); if (to_wakeup) try_to_wake_up_local(to_wakeup); } } switch_count = &prev->nvcsw; } pre_schedule(rq, prev); if (unlikely(!rq->nr_running)) idle_balance(cpu, rq); /*告诉调度器prev进程即将被调度出去*/ put_prev_task(rq, prev); /*挑选下一个可运行的进程*/ next = pick_next_task(rq); /*清除pre的TIF_NEED_RESCHED标志*/ clear_tsk_need_resched(prev); rq->skip_clock_update = 0; /*如果next和当前进程不一致,就可以调度*/
那么Linux是如何挑选下一个进程的呢, 这里就要提到Linux2.6版本以后使用的完全公平的调度器CFS了,下面我们来看一看它是基于一种什么样的思想的。
CFS是最终被内核采纳的调度器。它从RSDL/SD中吸取了完全公平的思想,不再跟踪进程的睡眠时间,也不再企图区分交互式进程。它将所有的进程都统一对待,这就是公平的含义。CFS的算法和实现都相当简单,众多的测试表明其性能也非常优越。按照作者Ingo Molnar的说法(参考Documentation/scheduler/sched-design-CFS.txt),CFS百分之八十的工作可以用一句话概括:CFS在真实的硬件上模拟了完全理想的多任务处理器。在真空的硬件上,同一时刻我们只能运行单个进程,因此当一个进程占用CPU时,其它进程就必须等待,这就产生了不公平。但是在“完全理想的多任务处理器 “下,每个进程都能同时获得CPU的执行时间,即并行地每个进程占1/nr_running的时间。例如当系统中有两个进程时,CPU的计算时间被分成两份,每个进程获得50%。假设runqueue中有n个进程,当前进程运行了10ms。在“完全理想的多任务处理器”中,10ms应该平分给n个进程(不考虑各个进程的nice值),因此当前进程应得的时间是(10/n)ms,但是它却运行了10ms。所以CFS将惩罚当前进程,使其它进程能够在下次调度时尽可能取代当前进程。最终实现所有进程的公平调度。
与之前的Linux调度器不同,CFS没有将任务维护在链表式的运行队列中,它抛弃了active/expire数组,而是对每个CPU维护一个以时间为顺序的红黑树。该树方法能够良好运行的原因在于:
* 红黑树可以始终保持平衡,这意味着树上没有路径比任何其他路径长两倍以上。
* 由于红黑树是二叉树,查找操作的时间复杂度为O(log n)。但是除了最左侧查找以外,很难执行其他查找,并且最左侧的节点指针始终被缓存。
* 对于大多数操作(插入、删除、查找等),红黑树的执行时间为O(log n),而以前的调度程序通过具有固定优先级的优先级数组使用 O(1)。O(log n) 行为具有可测量的延迟,但是对于较大的任务数无关紧要。Molnar在尝试这种树方法时,首先对这一点进行了测试。
* 红黑树可通过内部存储实现,即不需要使用外部分配即可对数据结构进行维护。
要实现平衡,CFS使用“虚拟运行时”表示某个任务的时间量。任务的虚拟运行时越小,意味着任务被允许访问服务器的时间越短,其对处理器的需求越高。CFS还包含睡眠公平概念以便确保那些目前没有运行的任务(例如,等待 I/O)在其最终需要时获得相当份额的处理器。
1)CFS如何实现pick next
下图是一个红黑树的例子。
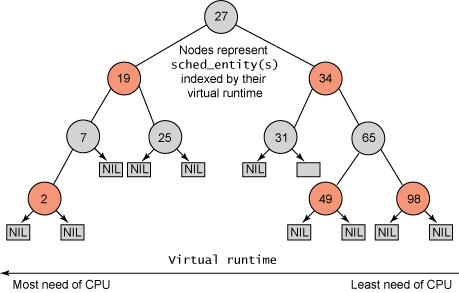
图片为 一个红黑树示例
所有可运行的任务通过不断地插入操作最终都存储在以时间为顺序的红黑树中(由 sched_entity 对象表示),对处理器需求最多的任务(最低虚拟运行时)存储在树的左侧,处理器需求最少的任务(最高虚拟运行时)存储在树的右侧。 为了公平,CFS调度器会选择红黑树最左边的叶子节点作为下一个将获得cpu的任务。这样,树左侧的进程就被给予时间运行了。 (楷体字均引用自网络)
了解CFS的思想后,我们来看看实际代码实现是怎么样子的:
static struct task_struct *pick_next_task_fair(struct rq *rq) { struct task_struct *p; /*从CPU 的就绪队列找到公平调度队列*/ struct cfs_rq *cfs_rq = &rq->cfs; struct sched_entity *se; /*如果公平调度类没有可运行的进程,直接返回*/ if (!cfs_rq->nr_running) return NULL; /*如果调度的是一组进程,则需要进行循环设置,否则执行一次就退出了*/ do { /*从公平调度类中找到一个可运行的实体*/ se = pick_next_entity(cfs_rq); /*设置红黑树中下一个实体,并标记cfs_rq->curr为se*/ set_next_entity(cfs_rq, se); cfs_rq = group_cfs_rq(se); } while (cfs_rq); /*获取到具体的task_struct*/ p = task_of(se); if (hrtick_enabled(rq)) hrtick_start_fair(rq, p); return p; }
pick_next的实体:
static struct sched_entity *pick_next_entity(struct cfs_rq *cfs_rq) { /*从红黑树中找到最左边即等待时间最长的那个实体*/ struct sched_entity *se = __pick_first_entity(cfs_rq); struct sched_entity *left = se; /* * Avoid running the skip buddy, if running something else can * be done without getting too unfair. */ if (cfs_rq->skip == se) { struct sched_entity *second = __pick_next_entity(se); if (second && wakeup_preempt_entity(second, left) < 1) se = second; } /* * Prefer last buddy, try to return the CPU to a preempted task. */ if (cfs_rq->last && wakeup_preempt_entity(cfs_rq->last, left) < 1) se = cfs_rq->last; /* * Someone really wants this to run. If it\'s not unfair, run it. */ if (cfs_rq->next && wakeup_preempt_entity(cfs_rq->next, left) < 1) se = cfs_rq->next; clear_buddies(cfs_rq, se); return se; }
4.对Linux进程模型的看法
通过对Linux进程模型的分析,我们不能不说Linux进程模型的设计是十分精妙的,从建立新进程的do_fork,到进程控制块PCB的设计,再到实际对进程进行调度时的CFS。无不体现了开发人员付出的心血和聪明才智,虽然这次作业只阅读了很小的一部分源码,在Linux数以千万计行的代码中连冰山一角都算不上,但是可以发现,我们平时使用计算机时习以为常的一些东西(不只是进程),都是建立在大量绝妙的设计和创新上的。对于如此之庞大的一个系统来说,去阅读它全部的代码几乎是不可能的(我们阅读的速度甚至跟不上它更新的速度),但是我们可以从中了解到的是开发过程中的思想,避免过多使用(或简化)大体量的结构,不断创新使用更好的算法,等等等等,这些是我们需要去学习的。
参考及引用的资料:
https://blog.csdn.net/zhoudaxia/article/details/7375668
https://blog.csdn.net/sunnybeike/article/details/6918586
https://blog.csdn.net/lizhi200404520/article/details/6546260
以上是关于第一次作业:基于Linux进程模型分析的主要内容,如果未能解决你的问题,请参考以下文章