python 爬取网页出错 菜鸟求解
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python 爬取网页出错 菜鸟求解相关的知识,希望对你有一定的参考价值。
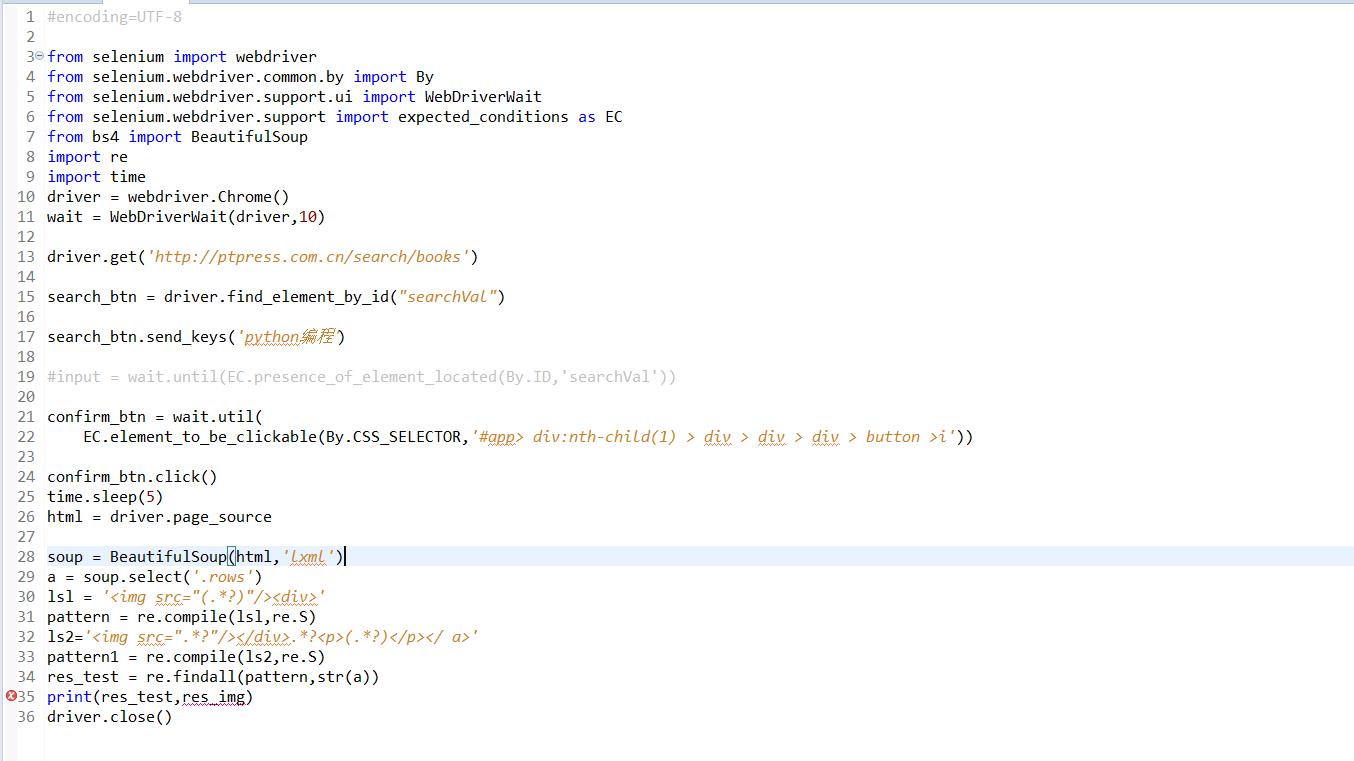
#encoding=UTF-8from selenium import webdriverfrom selenium.webdriver.common.by import Byfrom selenium.webdriver.support.ui import WebDriverWaitfrom selenium.webdriver.support import expected_conditions as ECfrom bs4 import BeautifulSoupimport reimport timedriver = webdriver.Chrome()wait = WebDriverWait(driver,10)driver.get('http://ptpress.com.cn/search/books')search_btn = driver.find_element_by_id("searchVal")search_btn.send_keys('python编程')#input = wait.until(EC.presence_of_element_located(By.ID,'searchVal'))confirm_btn = wait.util( EC.element_to_be_clickable(By.CSS_SELECTOR,'#app> div:nth-child(1) > div > div > div > button >i'))confirm_btn.click()time.sleep(5)html = driver.page_sourcesoup = BeautifulSoup(html,'lxml')a = soup.select('.rows')lsl = '<img src="(.*?)"/><div>'pattern = re.compile(lsl,re.S)ls2='<img src=".*?"/></div>.*?<p>(.*?)</p></ a>'pattern1 = re.compile(ls2,re.S)res_test = re.findall(pattern,str(a))print(res_test,res_img)driver.close()
2.7的编码对新手不友好
关于Scrapy爬取1000张网页的问题
爬了几页以后就一直这样了,什么数据都没有出来了用了代理池也没有用

2、可能是有一些特殊网页,你现有的程序无法解决,报了异常,无法执行
3、链接错误
解决方法是:用单个报错的链接测试一下,是否能够正常运行。追问
单个链接可以爬,放多了的话,前几个链接可以爬,之后的就这样
以上是关于python 爬取网页出错 菜鸟求解的主要内容,如果未能解决你的问题,请参考以下文章
Mindjet MindManager Runtime Error!出错问题!
安装testlink时出错,mysql,PHP都已安装完成且版本兼容,但在安装testlink是却报错,求解。